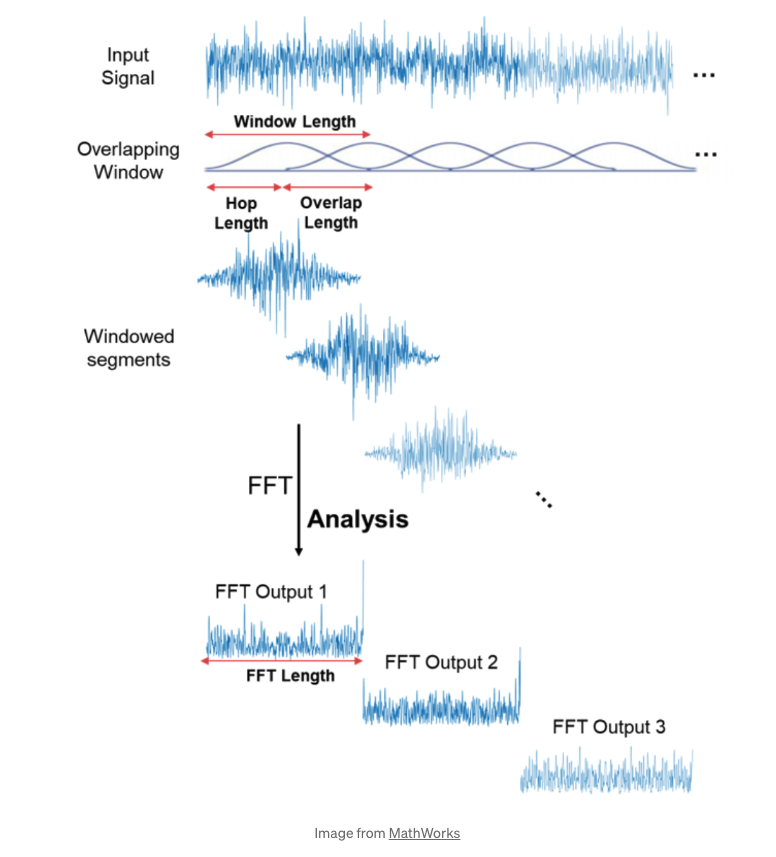
연구 관련해서 음성 데이터를 사용할 일이 생겼다. 보통 음성 데이터를 Raw data로 사용하면 용량이 너무 커지므로 딥러닝에서는 음성의 feature를 추출하여 사용한다. 이때 가장 많이 사용하는 음성 특징 추출 방법이 mel spectrogram이다. 이번 글에서는 mel spectrogram이 무엇인지, 그리고 어떻게 뽑아내는지에 대해 알아보고자 한다. 1. mel spectrogram이란? 소리의 파형을 인간이 들을 수 있는 범위로 줄인 mel scale로 다운 스케일한 이후, 그 파형을 그림으로 그린 모양이다. 2. 어떻게 뽑아낼 수 있을까? librosa library를 사용하면 된다. 스크립트를 보면 다음과 같다. audio_file = "sound.wav" y, sr = librosa.lo..