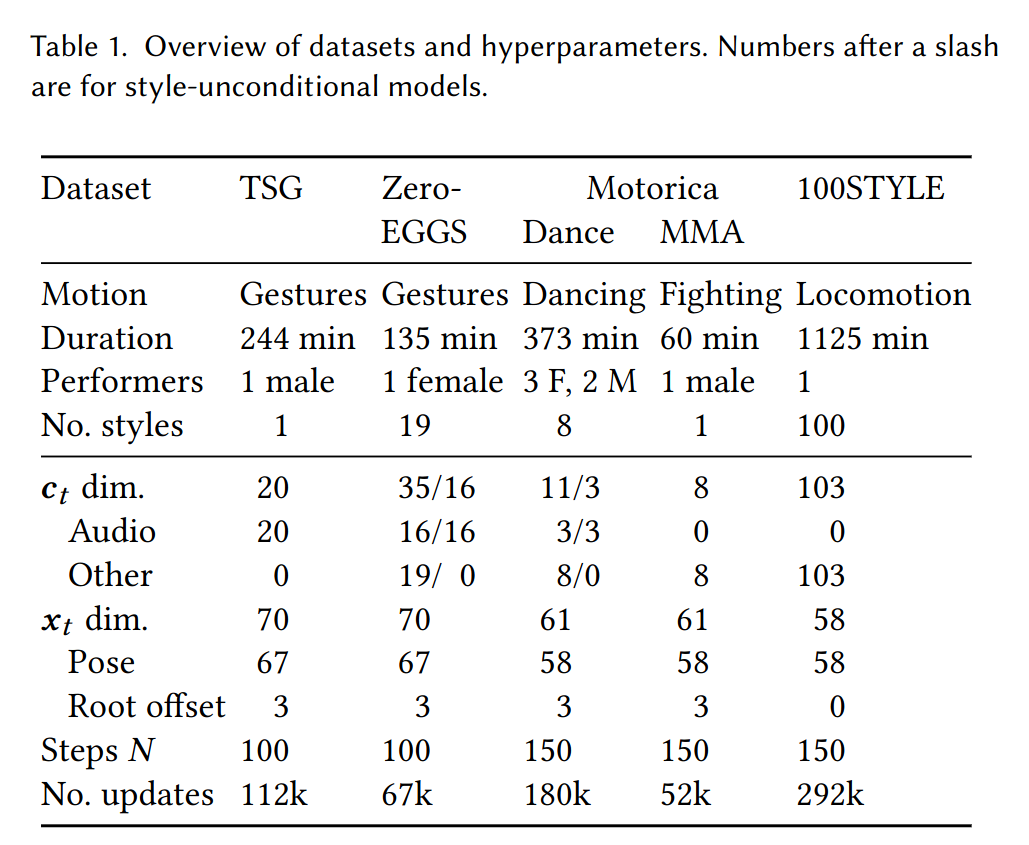
본 포스트는 Listen, Denoise, Action! Audio-Driven Motion Synthesis with Diffusion Models 논문에서 진행한 실험의 내용들을 정리하는 글이다. 4.1 데이터 처리 및 모델링 접근 방식 실험 4.2 일반적인 평가 프레임워크 4.3 두 개의 gesture generation dataset에서 우리의 방법과 기존의 방법 중 제일 나았던 방법 비교 4.4 audio-driven dance syntehsis 분야에서 우리의 방법과 기존의 최첨단 방법 비교 4.5 객관적인 지표 4.6 path-driven locomotion generation에 일반화된느 것을 보여줌 4.7 결과 요약 4.1 Data and modelling 실험에서 다섯가지 데이터셋을 사..