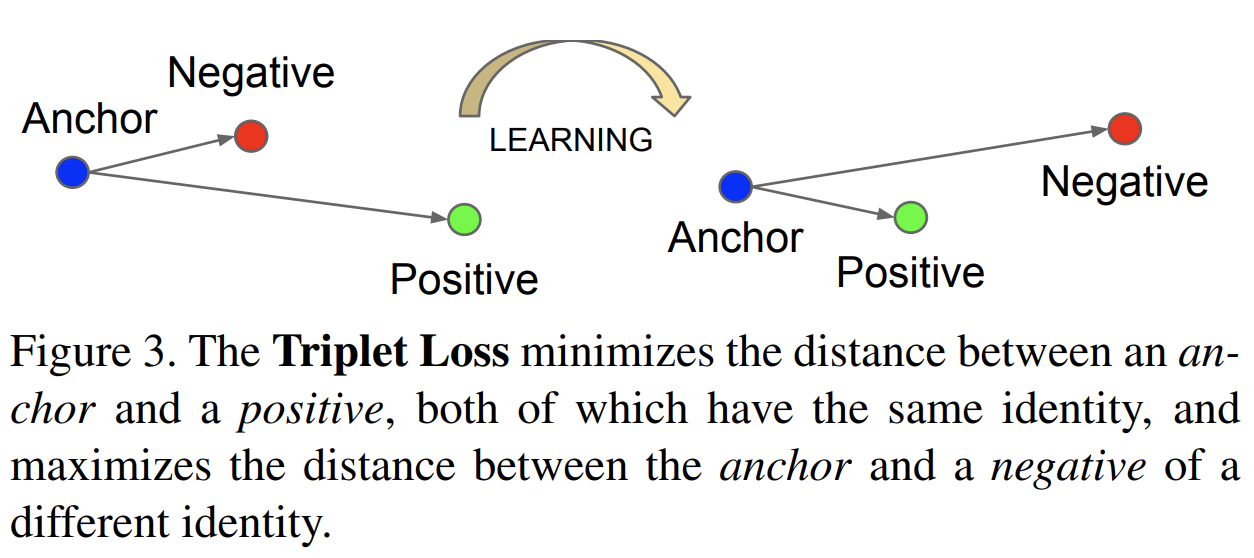
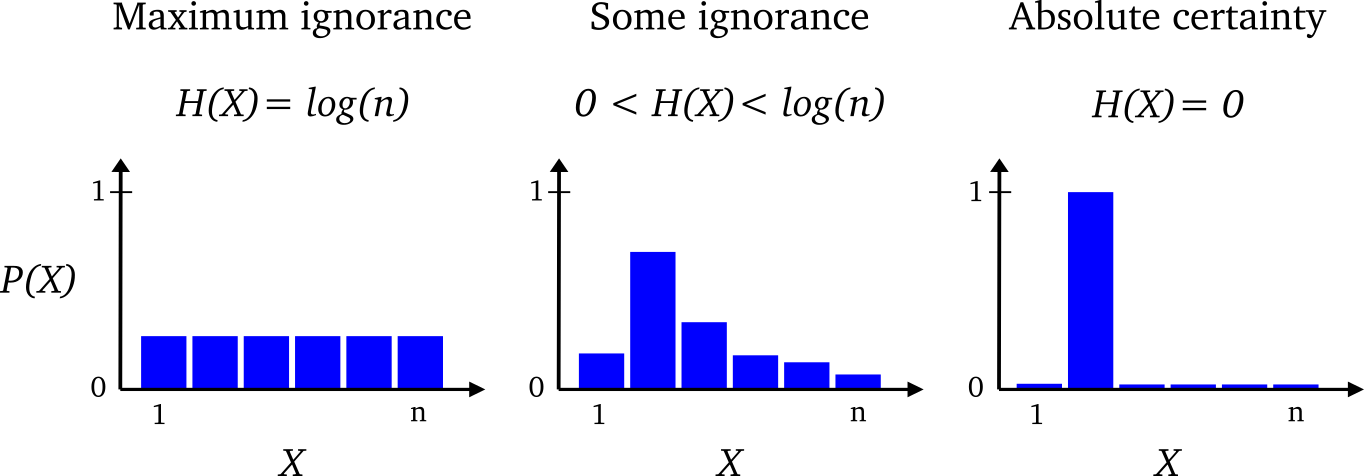
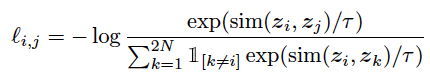supervised contrastive learning을 하기 위해 공개된 코드를 사용해야할 일이 생겼다. 아무리 가져온 코드라 하더라도 이해하지 않고 사용하는건 말이 안되는 것 같아, 해당 코드를 분석하는 포스트를 작성하고자 한다.🍀 코드 출처: https://ffighting.net/deep-learning-paper-review/self-supervised-learning/supervised-contrastive-learning/ Supervised Contrastive Learning - 딥러닝 논문 리뷰Supervised Contrastive Learning 논문의 핵심 내용을 리뷰합니다. Supervised Contrastive Learning의 제안 방법을 살펴봅니다. 마지막으로 성능 비..