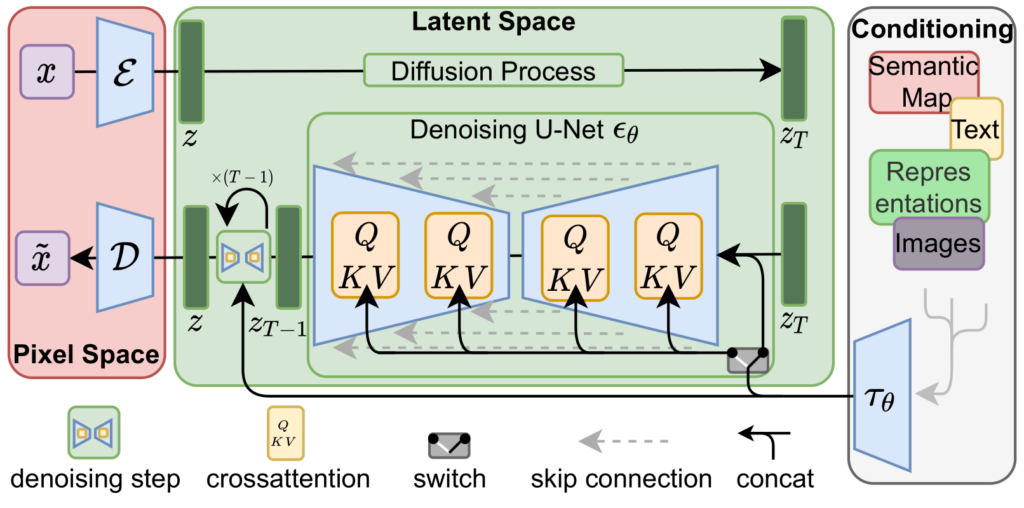
개념 이해하기Latent Diffusion은 기존 Diffusion Model의 연산 부담을 줄이기 위해 나온 모델이다. 기존 diffusion model은 고해상도 이미지 공간에서 직접 노이즈를 제거해야하다보니 계산량이 너무 많았다. latent diffusion은 이에 주목하여 이미지를 먼저 autoencoder를 통해 압축된 latent space로 옮겨서 latent 공간에서 diffusion을 수행한 뒤 마지막에 다시 이미지를 복원한다. u net이 노이즈 제거시에 latent값과 추가조건(ex: text embedding)을 함게 고려하면서 노이즈를 제거할 수 있기 때문에 conditioning이 가능하다 코드 뜯어보기사전 학습된 Stable Diffusion 모델이 돌아가도록 하는 코드를 통..