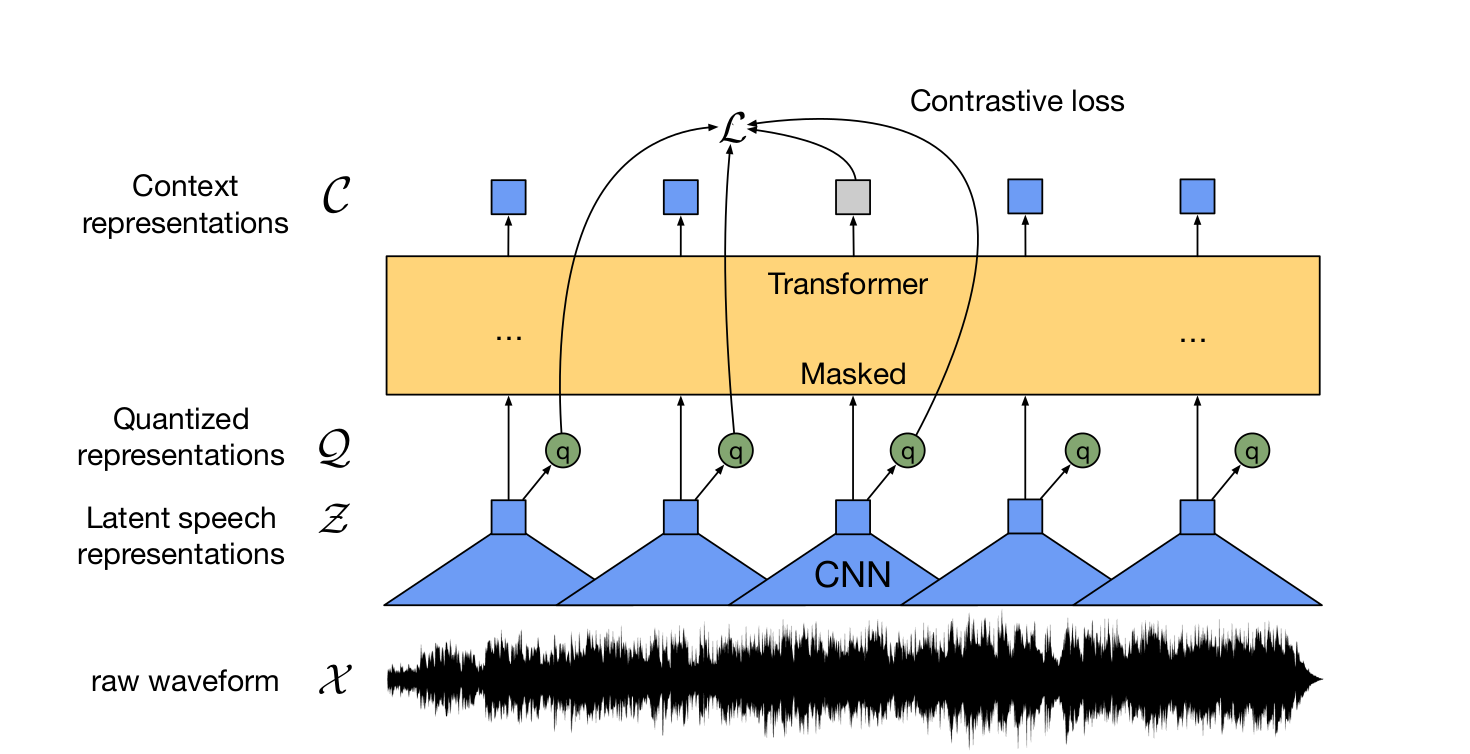
Wav2vec 2.0 이 speech representation과 같은 분야에서 효과적인 성능을 보이는 것은 지난 포스트를 통해 확인할 수 있었다. 하지만 내가 하고자하는건 music representation이라 music representation에도 wav2vec 2.0이 효과적인 성능을 보이는지 좀 더 알아볼 필요가 있었다. 이와 관련된 내용을 "Learning Music Reprsentation with WAV2VEC 2.0" 이라는 논문에서 확인할 수 있다. https://arxiv.org/pdf/2210.15310.pdf 본 논문에서는 wav2vec 2.0을 pretraining 단계에서부터 음악을 통해 학습시켜 wav2vec 2.0 모델이 pitch나 Instrument를 인코딩하는 Lat..