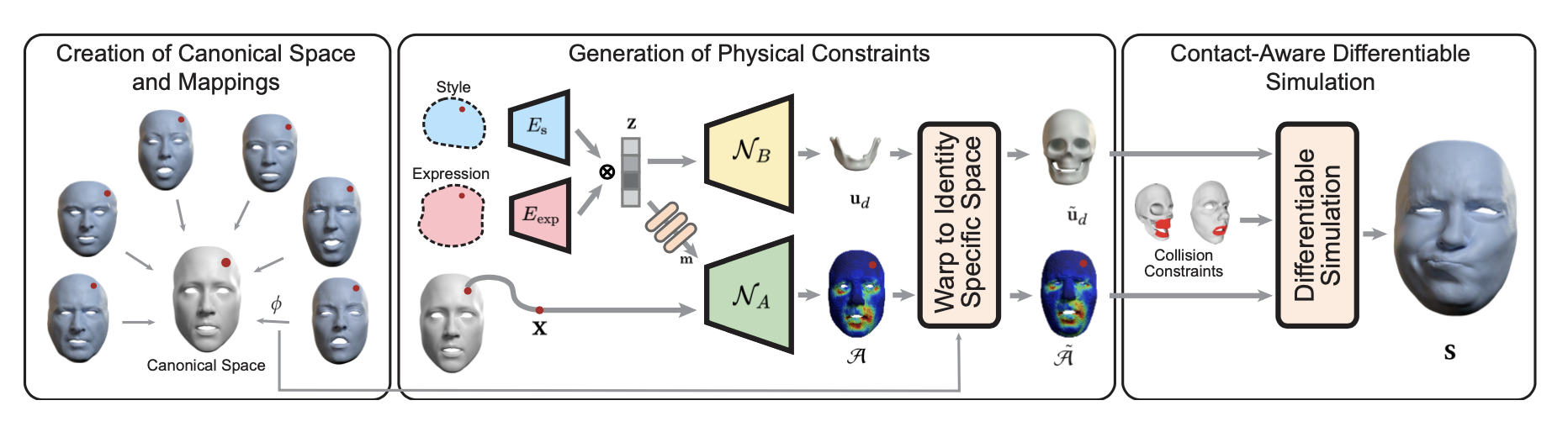
하고자 하는 것Audio Input과 Emotion labels을 받으면, 해당 emotion에 적절하면서도 audio input에 맞는 speech facial animation을 생성할 수 있는 EMOTE framework 제안Datasetemotional speech에 대한 dataset은 존재하지 않음. 그래서 emotional video dataset인 MEAD dataset에서 reconstruction method 사용해서 생성한 data 사용.MEAD dataset에 포함된 감정 label을 사용하는 것이 아니라 emotion feature를 따로 extract해서 사용EMOCA’s public available emotion recognition network를 사용해서 emotion f..