
1. 논문 소개
An Implicit Physical Face Model Driven by Expression and Styles는 Siggraph Asia 2023에 디즈니리서치에서 발표한 논문으로, data-driven implicit neural physics model을 기반으로 한 새로운 face model을 제안하고 있다.
https://www.youtube.com/watch?v=-qM_XUv-JhA
기존의 facial animation들은 보통 blendweight vector로 expression을 정의하여 다루게됨. 이때, 캐릭터마다 대응되는 blendshape rig를 설정하고, 같은 blendshape weight 적용해서 그들만의 style로 expression을 수행하도록 한다.
➡️ 이러한 방식은 expression을 수행할 때 개별마다 나타나는 style을 간과하는 방식
본 프레임워크에서는 expression에서 개별마다 고유한 style이 존재한다는 점에 주목하고, style과 expression을 개별적인 입력으로 받아, 물리 기반의 facial animation을 출력한다. 이때 생성되는 facial animation은 얼굴의 물리적인 특성과 상호작용을 고려하여 생성했기 때문에, 캐릭터가 말하거나 웃을 때 생기는 피부와 피부의 접촉, 뼈 구조의 변형 등 실제와 같은 물리적 효과을 애니메이션에 반영할 수 있다.
해당 framework를 사용하게 되면 다음과 같은 일들을 할 수 있게 된다.
1️⃣ 다양한 style과 expression의 조합: 입력으로 style과 expression을 개별적으로 넣어주기 때문에, 같은 expression을 입력으로 넣어주고 다양한 style을 각각의 입력으로 넣어주어, 같은 표정이지만 다양한 캐릭터에 맞게 조정된 애니메이션을 생성할 수 있음.
2️⃣ style 보간: 1️⃣에서 언급한 것처럼 style transfer도 가능하지만, 여러 캐릭터의 style을 보간하여 새로운 style을 만들어낼 수도 있다.
3️⃣ unseen expression의 animation 생성: 해당 framework는 unseen expression data에 대해서도 확장이 가능하다. 즉, 학습된 style에 대해서 본적 없는 expression의 animation을 생성할 수 있다.
2. Framework 동작 소개
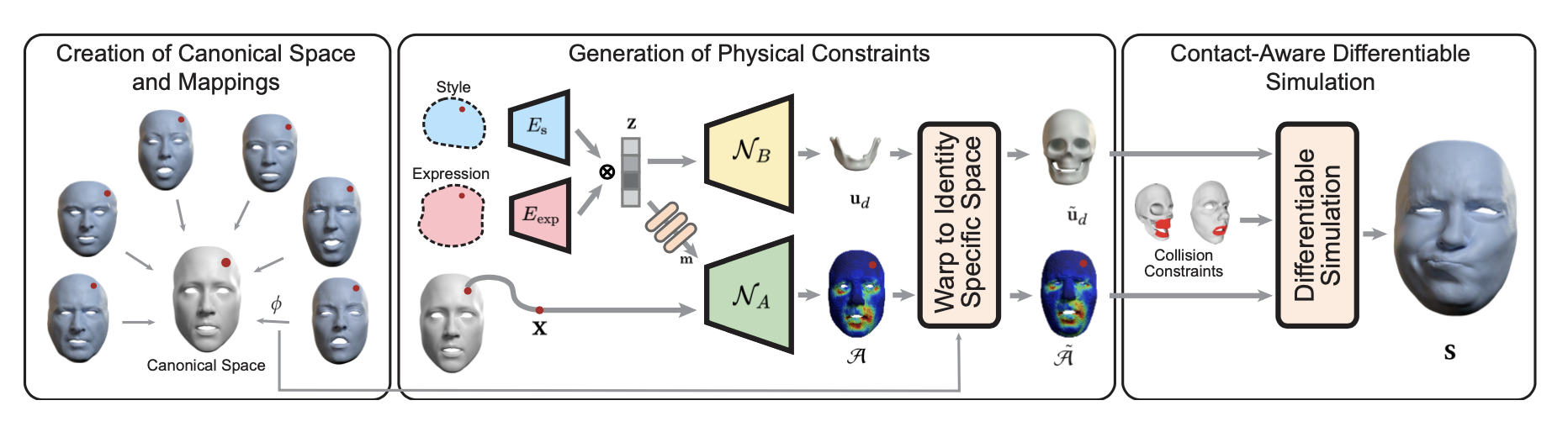
Framework는 크게 3가지의 파트로 이루어져있다.
- 1️⃣ canonical space를 생성하고 mapping하는 부분(2-1. Creation of Canonical Space and Mapping)
- 2️⃣ physical constraints를 생성하는 부분과 (2-2. Generation of Physical Constraints)
- 3️⃣ 이렇게 생성한 constraint들을 바탕으로 simulation을 생성하는 부분 (2-3. Contact-Aware Differentiable Simulation)
위의 파트들을 하나씩 살펴보자.
2-1. Creation of Canonical Space and Mapping

이 파트에서는 다양한 개체의 얼굴을 통합적으로 처리하기 위해 공통의 canonical space D_c를 생성하고 각 identity별 material space D^id_M에서 canonical space로의 매핑 방법을 정의한다.
이와 같이 통합된 canonical space를 사용하는 이유는? : 다른 identity 간의 style과 expression을 일관되게 학습하고 simulation할 수 있도록 하기 위해
Canonical Space D_c
모든 개체의 얼굴을 표준화하여 표현할 수 있는 3D 볼륨으로, canonical facial surface와 bone mesh로 구성된다. 다양한 개체의 얼굴을 통합적으로 모델링하기 위한 기준점 역할을 한다.
Mapping Function
각 identity별로 정의되는 function으로, 각 개체별 material space D^id_M에서 Canonical space로의 변환을 수행한다. 이러한 mapping 함수는 idenity마다의 얼굴 형태와 뼈 구조를 cnonical space에 정렬시키는 역할을 하게 된다. mapping 함수를 생성하기 위해서는 identity마다 MLP network를 학습시켜야한다.
각 identity마다 학습시키는 MPL network의 loss function은 다음과 같다.

총 2가지의 term으로 이루어져있는데
- 앞쪽 term: 표면 mesh(facial surface mesh와 bone mesh 포함) 상의 점의 위치 차이를 작게 만드는 term으로, mapping함수를 거친 개별 identity의 mesh 상의 점과 canonical space에서의 mesh 상의 점의 위치 차이를 작게 만드는 term이다.
- 뒤쪽 term: elastic regularization term으로, volumatic mapping을 smooth하게 만들기 위한 term이다. 여기서는 N_e개의 point를 uniformly하게 sample해서 사용하게 되며, 매핑 함수가 생성하는 변형에서 회전을 제외한 성분의 크기를 최소화하여 과도한 왜곡 없이 부드러운 변형을 유도하게 된다.
이러한 term으로 구성된 loss function을 사용해 mapping function을 pre-trained시켜 사용하게 된다.
Actuation Field
실제 시뮬레이션 시에는, Actuation Field라는걸 사용하게 된다. Actuation Field는 얼굴의 각 부분이 어떻게 움직여야 하는지를 정의한다. 즉, 얼굴 표정이나 움직임을 생성하기 위해 각 지점에 적용되어야 하는 물리적인 힘이나 변형을 모델링한다고 보면 된다. model이 일반화를 잘하도록 하기 위해 canonical actuation function을 학습시킨 뒤 이를 각 identity마다 adpated시켜 사용하게 된다.
Actuation Field는 다음과 같이 정의된다.

위의 수식에서 A(*)이 canonical actuation function이고, 위의 수식의 결과로 각 identity에 adapted된 A^~id(*)가 나오게 된다. actuation field의 학습은 2-2. Generation of Physical Constaints에서 다룰 것이다.
2-2. Generation of Physical Constraints
2-1에서 언급한것처럼, 본 framework에서는 shared canonical space에서의 acutation tensor field를 정의하는 unified implict actuation network를 학습시키기 된다. 이렇게 canonical space상에서 학습을 시키게 되면, different material spaces 상에서 학습해야하는 부담을 덜 수 있을 뿐만 아니라 여러 identity간의 common feature를 찾아내어 transferability를 상승시킬 수 있다.

- Style: identity마다 style code를 부여하여 이 style code를 network의 입력으로 넣어주게 된다. 다양한 identity를 동일한 network로 학습시켜 canonical space를 학습시키기 때문에, 새로운 identity에 대해서 implict actuation network N_A를 새로 학습시키지 않아도 된다.
- Expression: per-frame blendweights를 expression code로 넣어주게 된다.(per-frame reconstructed geometry를 simulation의 target으로 넣어주게 된다.)
- Activation code z: style code와 expression code는 각각 MLP를 통과하여 higher dimensional latent space로 mapping되고 concatenated되어 actiavation code z가 된다.
- modulation code m: activation code를 작은 tiny network를 통과시켜 modulation code m을 생성해 Implicit Actuation Network N_A의 입력으로 들어가 canonical implicit actuation tensor field A를 control하는데 사용된다.
Implicit Actuation Network N_A
Implicit Actuation Network를 사용해서 canonical implicit actuation tensor field A를 정의하게 되고, 이는 identity마다 정의된 mapping function을 사용해 identity specific space에서의 A^~id로 변형된다.
jaw transformation을 얻어내기 위한 Network N_B
rest state로부터 jaw transformation을 얻어내기 위해 Network N_B를 학습시키게 된다. N_B의 입력에는 Activation code z가 들어가게 되며, N_A의 학습과 유사하게 canonical jaw coordinate system 상에서 학습을 시키게 된다.
2-3. Generation of Physical Constraints

2-2에서 Generation of Physical Constraints 파트의 결과로 각 identity의 material space에서 정의된 물리적 제약 조건이 생성된다. Contact-Aware Differentiable Simulation part에서는 이러한 제약조건을 만족시키면서 energy를 최소화하는 최종 simulation을 생성하고자 한다.
본 연구의 simulation framework는 3가지의 energy term으로 구성된다.
- 1️⃣ shape targeting
- 2️⃣ bone attachment
- 3️⃣ contact energies
Shape Targeting, Bone Attachment
첫 두 term(shape targeting, bone attachment)들은 Project Dynamics[Bouaziz et al. 2014]를 기반으로 하며, local constraint는 다음과 같이 표현된다.

위의 식은 constraint C_i를 만족하면서, term의 값을 최소로 하는 y_i를 찾는 것을 목표로 한다. y_i는 최적화 과정(학습과정이 아님)에서 조정되는 값으로, 제약조건을 만족하면서 에너지를 최소화시키는 target position을 의미한다. u는 simulation vertices으로 시뮬레이션의 현재 상태를 의미한다. 즉, 위의 식에서 현재 상태와 차이가 가장 적으면서도 constraint를 만족시키는 target position y_i과 현재 상태의 차이에 비례하게 energy를 평가한다. total energy E(u)는 이러한 local energy 값들을 전부 합쳐서 구할 수 있다.
최종적으로, 다음의 linear system을 slove하게 된다.

simulation vertices가 target position과 가까워지도록 다음의 linear system을 solve하여 최적화시키게 된다.
Contact energies
전통적인 물리 시뮬레이션에서는 객체들이 서로 침투하지 않도록 하기 위해, 부등식을 사용해 객체 간의 최소 거리를 강제하는 방식을 사용했다. 하지만 IPC model에서는 collision을 penalize하는 smoothly clamped barrier potential(아래의 수식)이라는걸 사용하여 inequality constraint를 사용하지 않아도 된다.

- d_i는 surface primitives의 주어진 pair i 사이의 거리를 의미한다. (예를 들어 vertex-traingle 사이의 거리 또는 edge-edge 사이의 거리 의미)
- d^은 사용자가 정의한 충돌 해결을 위한 허용 오차입니다. 이 값은 시스템이 어떤 상황을 충돌로 간주할지 결정하는 데 사용되며, 이 허용 오차 내에서는 충돌이 발생하지 않도록 시스템이 조정된다.
위의 smoothly clamped barrier potential을 사용하면?!
➡️초기 상태에 충돌이 없는 한, 이후 발생하는 모든 침투를 방지할 수 있다.
본 프레임워크에서는 이러한 barrier erenrgy를 도입하여 facial simulation을 다음의 optimization problem을 푸는 문제로 정의한다.

이때 B(u)는 nonliear하고, PD-based가 아니기 때문에, B(u)를 테일러전개를 사용해 다음과 같은 B^(u)로 근사한다 (이때 ^u는 이전 반복에서의 최적화 상태를 의미한다.)

이렇게 근사한 뒤, 아래와 같은 새로운 linear system을 푸는 문제로 정의하게 된다.

여기서 K는 시뮬레이션 전반에 걸쳐서 고정되어 있고, delta^2 B는 지속적으로 변하지만 선형시스템 좌변의 일부에만 영향을 미친다. 또한 최적화 과정에서 시뮬레이션의 정확성과 안정성을 위해 다음과 같은 기술을 사용한다.
- continous collision detection: 모든 iteration마다 collision detection을 하여 침투가 일어나지 않도록 보장
- line search: optimization 과정에서 적절한 step size를 찾아서 알고리즘의 수렴을 보장하도록 함
이때 충돌의 경우에는, 모든 영역을 고려하는 대신 충돌이 일어나기 쉬운 영역(e.g. the lips)만 고려하여 barrier potential(B)를 설계한다. 우리가 embedded simulation을 사용하고 있기 때문에 (u가 세밀한 mesh가 아니라 coarser simulation mesh임) finer collision proxy p를 얻기 위해 다음과 같은 계산을 거치게 된다. ➡️ p = Wu
이렇게 p를 linear한 mapping을 따르게 함으로써, optimization framework에서 CCD(continuous collision detection)가 가능하도록 하였다. (system이 linear할 경우 ➡️ 미래에 발생할 충돌을 사전에 계산하고 감지하는 과정이 단순화된다.)