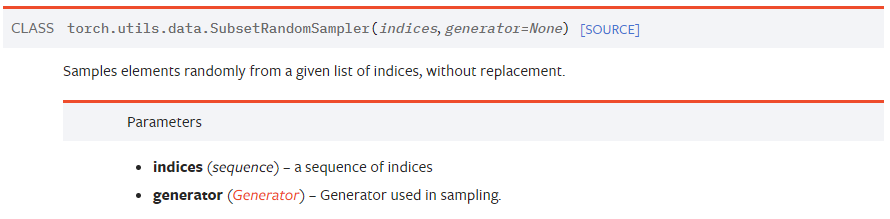
모든 pytorch의 dataloader는 sampler라는걸 가지게 된다. * RandomSampler DataLoader(dataset=train_dataset, shuffle = True, batch_size = 1) 위와 같이 shuffle=True로 세팅하게 되면 dataloader의 sampler는 자동으로 RandomSampler로 선택된다. 만약 RandomSampler가 아닌 내가 원하는 방식대로 동작하는 sampler를 따로 지정해주고 싶다면 shuffle= False로 세팅하여야한다. * SubsetRandomSampler shuffle=True일때는 전체 dataset에서 data를 andom하게 뽑게 된다. 만약 전체 dataset에서가 아닌 일부 subset에서 data rand..