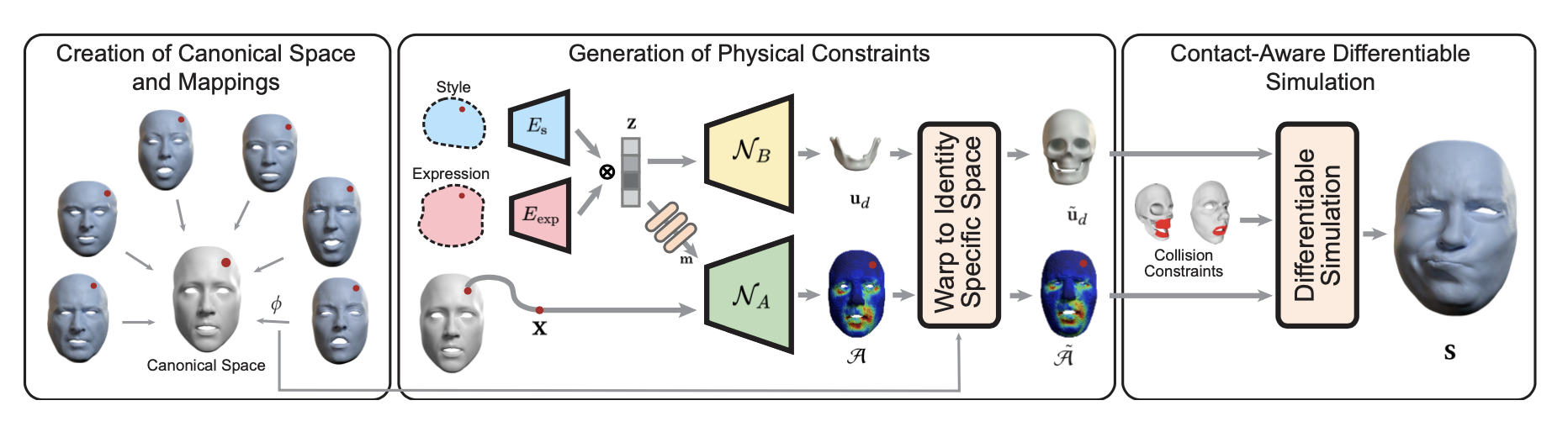
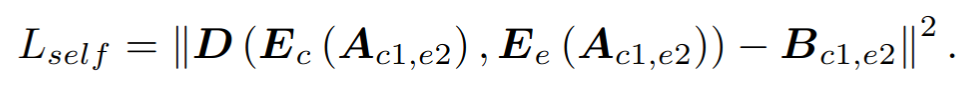SAME: Skeleton-Agnostic Motion Embedding for Character Animation 코드를 사용해야할 일이 있어 논문의 개념을 빠르게 살펴보았다.내가 하고자하는 건 skeleton에 구애받지 않는 motion embedding vector를 사용하는 것인데, 그림의 z를 생성하는 Encoder를 사용하고자 한다고 보면 된다. Skeletal motion data 𝑀 = (𝑆, 𝐷1:𝑇 ) 는 skeleton data 𝑆 and motion data 𝐷로 이루어진다.스켈레톤 데이터( 𝑆 )캐릭터의 스켈레톤 구조를 나타내며, 관절의 절대 위치(𝑝𝑗)와 부모 관절에 대한 상대 오프셋(𝑜𝑗)으로 구성된다. 즉 𝑆 = {𝑝1:𝐽 , 𝑜1:𝐽 } 의 형..