
https://ziqiaopeng.github.io/emotalk/
EmoTalk
Speech-driven 3D face animation aims to generate realistic facial expressions that match the speech content and emotion. However, existing methods often neglect emotional facial expressions or fail to disentangle them from speech content. To address this i
ziqiaopeng.github.io
Speech-driven 3D face animation aims to generate realistic facial expressions that match the speech content and emotion.
EmoTalk는 ICCV 2023에 발표된 논문으로 speech content와 emotion에 맞는 적절한 speech-driven 3D face animation을 생성하는 방법을 제안하고 있다. EMOTE 논문과 하고자 하는 것 자체는 비슷하지만 약간의 차이가 있는데, speech에 드러나는 emotion을 캡쳐해서 그 emotion에 맞는 facial animation을 생성한다는 점과, framework를 end-to-end로 학습시킨다는 점이다.
논문에서 제아하는 시스템의 overview는 다음과 같다.

- speech로부터 emotion 정보와 content 정보를 구분하기 위해 두 개의 encoder(Emotion Encoder와 Content Encoder)를 두어 한 encoder에서는 emotion latent feature를 뽑아내도록 하였으며, 나머지 한 encoder에서는 content latent feature를 뽑도록 하였다.
- 또한 user가 control할 수 있는 parameter 2개를 더 받는데, 두 정보 모두 one-hot encoding으로 표현된다.
- 표현되는 emotion의 강도 (2차원)
- personal style (24차원)
- 이러한 feature들은 합쳐져서 emotion-guided feature fusion decoder에 들어가고 emotion-enhanced blendshape coefficient를 출력하게 된다.
- 각 프레임의 face blendshape coefficients은 52개의 value로 표현이 된다.
그럼 각각의 module 및 디테일적인 부분에 대해 좀 더 자세히 살펴보자.
3.1. Emotion distangling encoder
speech와 facial expression 사이의 뒤얽힌 관계를 다루기 위해, 본 framework에서는 Ji et al의 연구에서 영감을 받은 disentangling encoder를 제안하였다. 본 연구에서는 origianl distenanglement module에서 몇가지 변경을 가했는데
- MFCC feature extroactor를 preTraiend wav2vec 2.0으로 변경하였다. (MFCC는 rich speech information을 capture하지 못하고, input process가 복잡하기 때문.) 그리고 wav2vec 2.0의 TCN layer는 고정시킨 채로 finetuning을 시켰다.
- disentanglement process를 간소화해서 간결함과 이해가능성을 증가시켰다.
- module을 end-to-end form으로 변경하여 모델이 52 blendshap coefficient를 직접적으로 출력할 수 있도록 하였다.
하지만 이러한 구조만으로는 content와 emotion 사이의 disentanglement를 보장할 수 없기 때문에 다양한 emotion과 content를 결합한 pseudo-training pairs를 사용하여 input으로 사용하고, network가 대응되는 ground-truth를 reconstruct하는 output를 출력할 수 있도록 하였다.
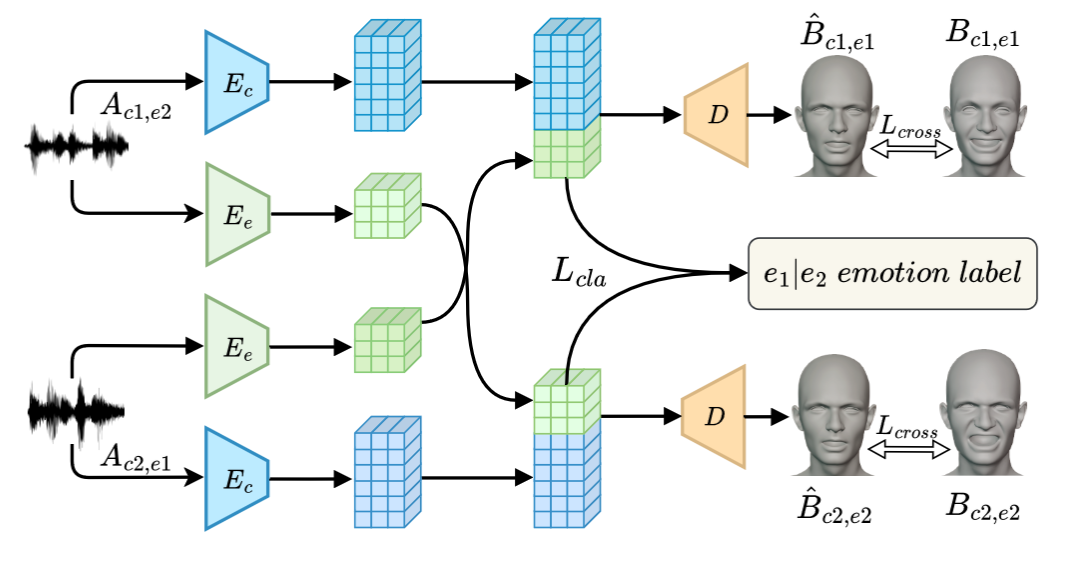
c1의 content와 e2의 감정을 가지는 raw speech audio A_{c1, e2}와 c2의 content와 e1의 감정을 가지는 raw speech audio A_{c2, e1}를 각각 input으로 사용하는데,
- 이 때 A_{c1, e2}로 c1의 cotnent feature, e2의 emotion feature를 생성하고
- A_{c2, e1}로 c2의 content feature, e1의 emotion feature를 생성한다.
그런 다음 두 Input으로 만든 feature를 교차해서 사용하여
- c1의 cotnent feature와 e1의 emotion feature를 사용해 생성한 blendshape coefficient와 c1,e1에 해당하는 ground truth blendshape coefficient를 비교하여 loss를 계산하고
- 마찬가지로 c2의 content feature와 e2의 emotion feature를 사용해 생성한 blendshape coefficient를 c2,e2에 해당하는 ground truth blendshape coefficient와 비교하여 loss를 계산한다.
이러한 방식을 통해 content와 emotion feature의 분리를 강제할 수 있다.
3.2. Emotion-guided feature fusion decoder
이 모듈은 emotion feature(256차원), content feature(512차원), personal style feature(32차원), emotional level feature(32차원)를 받아 네 특징을 잘 반영하는 facial animation을 생성하는 것을 목표로 하고 있다. 네 특징은 같은 차원에서 concatenate되어 decoder의 input으로 들어가게 된다.
합쳐진 feature들로부터 3D blendshape coefficient를 생성하기 위해 Transformer decoder와 유사한 module을 사용하였다. Emotion-guided feature fusion decoder에서의 과정을 차례대로 살펴보면
- 먼저 periodic position encoding을 통해 speech 동안 입의 움직임에서 입의 열림과 닫힘에 대한 안정적인 시간을 포착하고
- biased multi-head self attention layer를 통해 mask layer에서 가까운 정보에 더 큰 가중치를 부여하여 인접한 동작의 변화에 더 집중할 수 있게 한 뒤에
- emotion-guided multi-head attention을 통해 emotion latent vector를 통해 emotion 정보를 다시 한번 반영시켜주고
- feed-forward layer를 통과 시킨 뒤에
- audio-blendshape decoder를 통해 52 blendshape coefficient를 출력한다.
3.3. Loss function
network의 학습을 위해 다음의 4개의 component로 이루어진 loss function을 사용하였다.
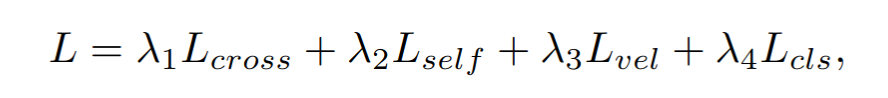
1) cross-reconstruction loss

앞에서 설명했던 서로 feature를 cross시켜 reconstruct하도록 한 뒤 해당 ground truth와의 차이 계산
2) self-reconstruction loss
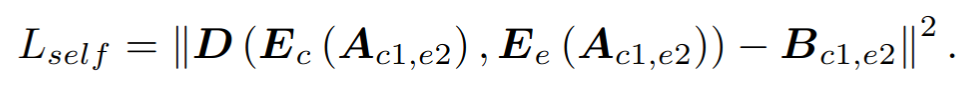
3) velocity loss
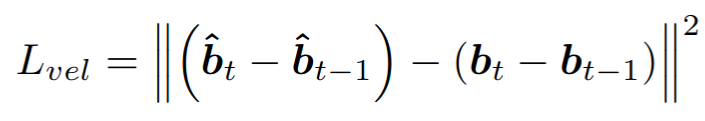
예측한 결과의 velocity와 ground truth 사이의 velocity의 차이를 계산한다. 해당 loss를 쓰는 이유는 생성되는 facial animation에서 jittering을 없애기 위해
4) classfication loss
emotional latent space에서 emotion을 명확하게 구분되도록 하는 것이 어렵기 때문에 emotion extoractor E_e의 output에 대해 classfication loss를 도입하여 감정이 좀 더 잘 분리될 수 있도록 구현하였다.
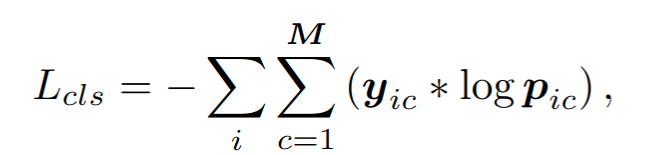
위의 식에서 y_ic는 실제 데이터 i의 class label을 의미하며, 데이터 i가 클래스 c에 속하면 yic = 1, 아니라면 yic=0이다. p_ic는 모델이 예측한 결과로 모델이 예측한 데이터 i가 클래스 c에 속할 확률을 의미한다.
3.4. Dataset construction
3D talking face data with emotions -> 굉장히 부족하기 때문에 2D dataset으로부터 blendshape capture method를 써서 3D data를 생성해서 사용하였다. 이렇게 구축한 3D emotional talking face dataset인 3D-ETF는 700000 frame의 blendshape coefficient로 구성되었으며 blend linear skinning 기술을 사용하여 blendshape 계수는 물론이고 mesh vertices data까지 구축하였다.