
본 포스트는 Listen, Denoise, Action! Audio-Driven Motion Synthesis with Diffusion Models 논문에서 진행한 실험의 내용들을 정리하는 글이다.
<목차>
- 4.1 데이터 처리 및 모델링 접근 방식 실험
- 4.2 일반적인 평가 프레임워크
- 4.3 두 개의 gesture generation dataset에서 우리의 방법과 기존의 방법 중 제일 나았던 방법 비교
- 4.4 audio-driven dance syntehsis 분야에서 우리의 방법과 기존의 최첨단 방법 비교
- 4.5 객관적인 지표
- 4.6 path-driven locomotion generation에 일반화된느 것을 보여줌
- 4.7 결과 요약
4.1 Data and modelling
<사용한 dataset>
실험에서 다섯가지 데이터셋을 사용했고 개요는 table 1에 나타나있다. 전신 모션 데이터셋만 사용하였다.

모든 데이터셋은 처음에 60 프레임 이상의 속도의 데이터였으나, 모델링을 위해 초당 30 프레임으로 변환하였다. 또한 자세를 나타내기 위해 joint rotation으로 포즈를 표현하고 이를 T-pose에 대한 exponential map representation으로 매개변수화시켰다.
<path-driven locomotion vs 나머지>
path-driven locomotion을 제외한 모든 모델은 총 root의 땅에 대한 움직임을 설명하는 3개의 추가적인 출력을 생성하도록 했다. -> character가 이동을 가능하게 하기 위해
path-driven locomotion의 경우 root node의 움직임은 출력이 아니라 synthesis의 입력으로 사용되었으며, 10 프레임동안 smoothing을 시켰다.(????)
<audio Input>
audio conditioning input은 모델마다 다르다. 도메인(speech vs music)에 의존
<style input>
모두 스타일 입력에 대해 one-hot encoding을 사용하였다. 왜냐하면 discrete한 style label만 사용했기 때문이다. 5.3절에서 설명한 전투 모델은 전투 동작 집합에 대한 이진 플래그를 입력으로 사용함
그리고 style 제어가 가능한 대부분의 시스템에 대해서, 스타일 입력이 없는 동일한 모델을 추가로 훈련시켰다. 이건 3.3에서 설명한것처럼 classfier-free guide를 통해서 style 표현을 할 수 있게 해준 모델로, / 다음에 표현된게 이에 대한 정보이다.
<parameter 측면>
parameter 중에서 노이즈 스케줄링 beta_n value를 조정하는 것이 가장 중요하며 Linear schedule에서 end 값을 높였을 때 성능이 향상하는 것을 확인할 수 있었음. 단일 GPU에서 훈련되었으며, 배치 당 5초 길이의 모션 시퀀스 80개를 사용하였음.
4.2 Evaluation methodology
본 연구의 핵심은 생성되는 모션이 사용자에게 어떻게 보이느냐이다. 따라서 객관적 지표도 활용하기는 하지만 가장 중요한 지표는 주관적 지표다!
<비교대상>
제스처 생성 작업에서 가장 성공적이였던 벤치마킹의 예는 "GENEA challenges". 현대의 gesture generation 생성 방법을 같은 세팅에서 사용자 연구로 비교한거. 여기서 높은 평가를 받았던 method랑 우리의 방법을 비교할거다.
<사용자연구>
user study의 경우 4가지를 수행했음. 이 중에서 3가지는 gestue generation을 고려하였고 하나는 dance를 고려하였지만 일단 모두 동일한 설정과 분석 방법으로 수행했음.
각 연구는 두가지 옵션을 각각 비교하는 방식으로 진행되었다. 10초 짜리 두 개의 비디오 클립이 연이어 재생되는 형태로 비교시켰다. 이때 비교하는 두 비디오의 오디오와 아바타를 사용하였고, 비디오를 다보고 나면 텍스트 질문과 다섯 개의 응답 버튼에 답하도록 하였다.
각 user study를 분석하는 방법은 merit score를 기반으로 했는데, 여기서 약간의 선호도는 1, 명백한 선호도는 2, 두 시스템간의 동등한 선호도는 0의 점수를 부여하였다. 그런다음 means of a one way ANOVA랑 post-hoc Tukey multiple comparision 테스트를 사용하여 통계적으로 유의함을 보였음.
4.3 Gesture-generation experiments
4.3.1 Experiment on the Trinity speech-gesture dataset(TSG Dataset)
첫 번째 실험에서는 StyleGestue[Alexander-son 2020]와 우리를 비교했다.
StyleGesture는 음성 조건화 제스처 생성을 위한 autoregressive normalising-flow model로 GENEA Challenge에서 최고의 동작 품질을 달성한 모델이다. 이 평가를 위해 우리는 TSG 데이터셋을 사용했으며, GENEA Challenge와 동일한 훈련/테스트 분할을 사용하고 테스트 세트의 데이터에 대해서만 평가를 수행했음. 동작은 그림 3에 나타난 GENEA 2022 아바타를 사용하여 시각화되었습니다. 이 아바타 디자인에는 입이랑 눈이 없어서 몸에 집중하게 된다.
TSG 데이터는 스타일 라벨을 포함하고 있지 않음. StyleGesture에서 말하는 모션 스타일은 모두 손 높이, 손 속도 이런 운동학적인 스타일이고 여기서 말한 discrete한 style 제어는 검증이 이루어지지 않았다. 따라서 StyleGesture와 비교하는 실험에서는 오디오 조건만 사용해서 모션 품질을 비교하였음
TSG 데이터에 대한 실험에서는 제스처 모션의 품질을 평가하기 위한 선호도 테스트를 수행하였고 총 네 가지의 조건에서 비교했음
- 원본 동작 캡처 (labelled GT)
- 제안된 시스템 (LDA)
- 제안된 Conformers 대신 원래의 DiffWave 아키텍처를 사용한 무시(제거) 조건 (LDA-DW)
- 스타일 입력이 없는 StyleGestures 시스템 (SG)
User study에서 "동작이 얼마나 자연스럽게 보이고 어떻게 말의 리듬과 억양과 일치하는지를 고려할 때 어떤 캐릭터의 동작을 선호합니까?"라는 질문을 함. 답변은 5단계로 선호정도를 선택하게 했고, 응답으로 1) 왼쪽 명확히 선호 2) 왼쪽 약간 선호 3) 선호하지 않음 4) 오른쪽 약간 선호 5) 오른쪽 명확히 선호 선택하게 함
ordered pair seen) 참가자가 ordered condition pair를 본 횟수
No.ordered pair) 가능한 pair 개수
이건 User study의 결과이다. GT가 merit score에서 가장 높은 점수를 얻었고, 다음으로 LDA, LDA-DW, SG 순서로 점수를 받았다. 이 결과로 알 수 있는건 인간 모션 캡처보다는 떨어지지만 제안된 확산 모델은 StyleGestures보다 우수한 성과를 보였음을 알 수 있음. 또한 LDA-DW보다 우수함을 통해서 Conformer 아키텍쳐가 결과에 기여했음을 알 수 있음 또한, LDA와 LDA-DW 간의 차이는 hyperparameter 및 Noise schedule을 사용하는 실험에서 더 큰 것으로 나타났으며, 이는 Conformers가 하이퍼파라미터 설정에 대해 민감하지 않다는 것을 나타냄. 여기서 LDA-DW가 성능이 낮다는걸 확인해서 뒤에 연구에는 이걸 포함시키지 않았음.
4.3.2 Experiments on the ZeroEGGS dataset
ZeroEGGS도 2022 GENEA Challenge에서 우수한 성과를 거둔 딥 생성 모델임. ZeroEGGS는 speech encoder랑 transformer 아키텍쳐를 사용하는 확률적인 스타일 인코더와 Recurrent gesture generation module로 구성되어있다. ZeroEGGS는 datset도 제안했는데 여기에는 스타일 정보가 포함되어있다.
실험을 위해 4가지의 스타일을 선택했고 이 스타일에는 Happy, Angry, Oration, Old가 포함된다
평가할때 음성 오디오의 스타일이 스타일 제어 효과에 간섭하는 것을 막기 위해, training data에서 중립스타일의 음성 녹음 2개를 빼고 학습시켰으며 평가할 때 이 data를 사용하였음.
이 데이터에 대해서는 세가지 조건을 비교하였음
- 우리의 제안 모델 (LDA)
- 우리의 제안 모델이긴한데 classifier-free guidance를 사용하여 style control을 할 수 있는 모델 (라벨은 LDA-G) 이때 𝛾를 1.5로 사용하여 스타일을 과장하였음 (style control 측면에서는 얘가 제일 점수 높음. 즉 스타일 강도 제어를 효과적으로 할 수 있음을 보인 결과임, preference 측면에서 움직임이 과장되었기 때문에 선호도가 낮은 것은 당연하다)
- ZeroEGGS (ZE)
style control 평가에서는 선호도 대신 "얼굴 표정을 무시하고 몸의 움직임만 기준으로 봤을 때 두 클립 중 어느 것이 제시된 스타일같아 보이나요?"라는 질문을 했고 여기서 스타일은 [행복한것처럼 보이는 사람, 화난것처럼 보이는 사람, 늙은 사람, 대중에게 연설하는 사람] 중 하나였음. 대답은 [분명히 왼쪽 것, 아마다 왼쪽 것, 모르겠다, 아마도 오른쪽 것, 분명히 오른쪽 것] 중 하나를 선택하도록 하였음. 스타일 판단에 음성 내용이 영향을 미치지 않도록 하기 위해서 음성을 빼고 실험을 진행함.
4.4 Music-driven dance synthesis
여기서는 audio-driven dance motion generation을 생성하기 위해 dance model을 학습시키고 평가해보았음. 기존에 존재하던 영상dataset이랑 새로운 영상 datset으로부터 광학모션캡쳐를 사용해 Casual style, hip-hop style, popping style, krumping style, jazz, charleston, tap, locking 스타일을 포함하는 오디오 및 댄스 데이터 373분 분량을 만들었음. 이 데이터셋은 공개될 예정이라고 함
기존에 존재하던 AIST++데이터셋이랑 비교했을 때 여기서 제안하는 데이터셋이 더 크고, 전체 노래를 capture 했고 완전히 새로운 style subset을 추가하였음. AIST++는 광학 기반의 모션 캡쳐를 사용하지 않았기 때문에 움직임 등의 아티팩트가 있어서 이 논문에서도 훈련을 할 때 foot contact과 관련된 loss를 추가했었음. 이에 반해 여기서 제안하는 그런 추가적인 처리를 하지 않았음
이 데이터에 대해서 style-conditioned model과 style-unconditional model을 둘다 만들었음. style conditioned model은 style을 one-hot encoding해서 사용하던 그 모델이고 style-unconditioned model은 classifier-free 였던 그 모델을 얘기함. 이 모델을은 audio input으로 세가지 오디오 특징을 받았는데, 하나가 1) 스펙트럼 플럭스, 2) 크로마, 3) RNNDownBeat-프로세서의 활성화로 구성되었으며 이건 Madmom 오디오 신호 처리 라이브러리를 사용해서 얻었음
이렇게 세가지를 쓴 이유는 음악의 구조를 반영하면서도 음악의 장르를 넘어서 다양한 댄스 스타일에 대한 일반화가 가능하게 하기 위해서이고, 이렇게 하면 음악에 오버피팅 되는걸 줄일 수 있어서이다. 이거보다 더 큰 음악차원을 썼을 때는 결과가 더 안좋았다.
베일란도 모델(BL)을 동일한 데이터셋을 사용하여 훈련시켰다. 이 모델은 해당 분야에서 최신 기술로 매우 좋은 평가를 받은 모델이고, Transformer를 사용해서 포즈 순서의 discrete 버전을 처리하는 autoregressive model임. 이 모델은 훈련이 네 단계에 걸쳐서 복잡하게 훈련됨. 여기서는 스타일 입력을 명시하지 않으므로 스타일은 음악 데이터와 밀접한 관련이 있다. 이 세팅은 style 무관 모델이랑 유사하며 LDA이랑은 차이가 있다.
그리고 데모 비디오에 천 개 이상의 프레임으로 구성된 긴 댄스 시퀀스를 제공하는데, 이러한 시퀀스는 한번에 생성되었음. 훈련시킬때 150 프레임 길이의 시퀀스만 훈련했음에도 불구하고 천 개 이상의 시퀀스에 대해서도 잘 동작함. 이건 모델 아키텍쳐에 사용된 translation-invariant self-attention이랑 관련이 있어보임.
주관적 평가를 위해서 LDA, 스타일에 무관한 LDA-U, BL 이 3가지 모델을 GT와 함께 비교했는데 주관적 비교를 하기 위해서 Jazz, 찰스턴, 힙합, 라킹, 크럼프, 캐주얼 스타일에 대해 비교를 수행했다.
각 스타일의 댄스 모션을 만들기 위해서 각 스타일마다 10초 길이의 6개의 audio segment를 뽑아내서 36개의 오디오 세그먼트를 만들었음. 그리고 각 스타일의 댄스 모션을 생성하기 위해서 모델에 넣어줬음. 각 스타일마다 다른 음악을 사용했지만, LDA-U나 BL처럼 스타일 무관 모델이 스타일에 맞는 댄스를 생성할거라는 보장이 없음. 반면 LDA는 요청하는 어떠한 스타일로도 주어진 음악에 맞추어 잘춘다. 그리고 table2랑 유사하게 선호도 테스트를 진행하였다. 참여자들은 비교 비디오에 대해서 "댄스 모션이 얼마나 자연스럽고 음악과 잘 일치하는지 고려하여 어떤 캐릭터의 댄스 모션을 선호하나요?"라는 질문에 대답하도록 함
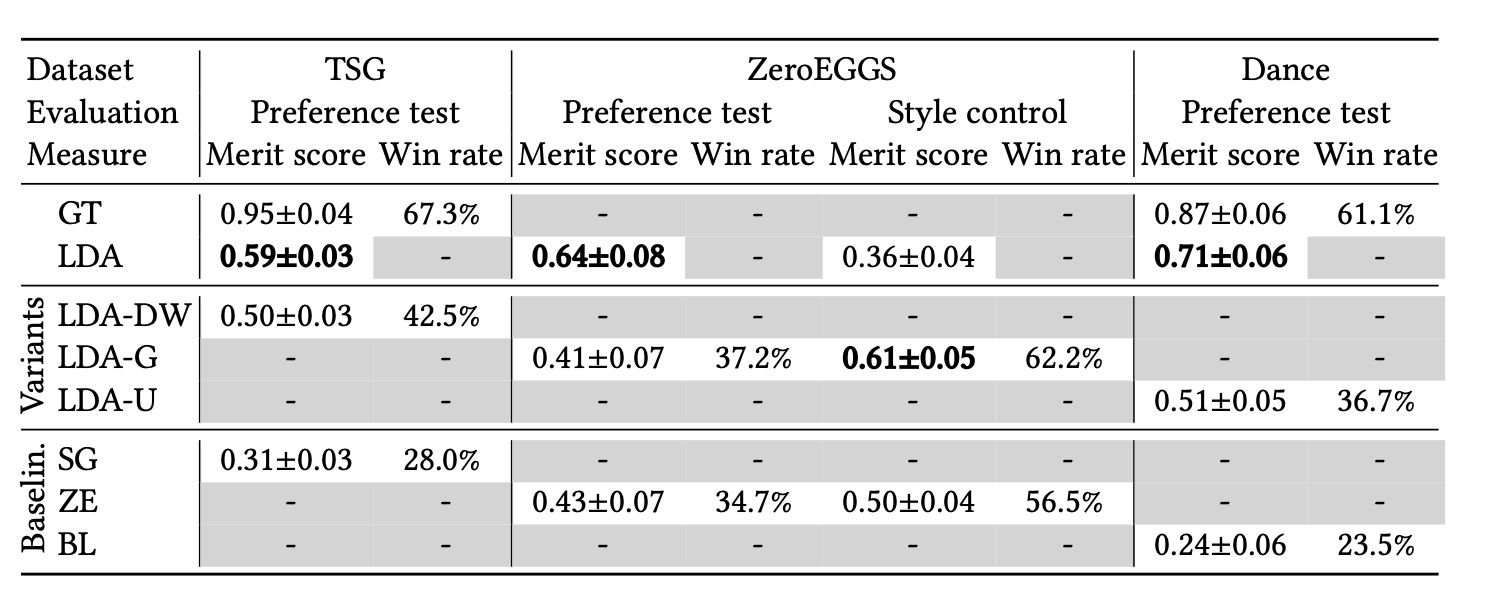
table3의 dance preference test를 보면 ground-truth가 점수가 제일 높고, 그 다음이 LDA, LDA-U, BL 순이다. 실험 결과 우리 모델이 베일란도는 확실히 능가하고 인간 모션 캡쳐 수준은 안되지만 그래도 우수하는걸 알수 있었음. LDA-U의 평가가 비교적 낮은데, 이건 style 정보를 오디오로부터 얻어내는데 오디오의 길이가 짧아서 그런걸수도 있음.
그리고 베일란도 논문에 제시된 예제보다 여기서 학습시킨 베일란도 모델이 만들어내는 댄스 모션의 퀄리티가 훨씬 좋았는데, 이 논문에서 제안하는 datset의 퀄리티가 더 좋기 때문임.
4.5 Objective metric
주관적 지표가 메인이긴 하지만 몇 가지 객관적인 지표도 계산해봄. generative model의 성능을 평가하는데 가장 많이 사용되는 FID 지표를 사용하였음. 데이터 집합 D랑 합성된 sample S 간의 FID 값은 D에서 뽑아낸 피쳐들과 S에서 뽑아낸 피쳐들의 각 multivariate Gaussian distribution 사이의 2-Wassertein(와서스타인)distacne로 정의됨. 즉 FID는 실제 데이터랑 합성된 data의 distribution이 얼마나 다른지 평가하는 값이다. 따라서 모션이 원하는 스타일을 정확하게 반영하는지, 오디오에 일치하는지 이런 부분들은 FID로판단할 수 없다.
제스쳐 합성의 경우에는 feature extractor로 Yoon et. al에서 제공한 오토인코더를 사용하였으며 이렇게 생성된 metric을 FGD라고 부름. 이 메트릭은 제스처 쪽에서 인간과의 유사성 평가를 할 때 중간정도의 상관관계가 있음이 확인되었음
댄스 합성같은 경우에는 Siyao et al에서 사용한 메트릭을 계산했는데 다음과 같다.
- 운동학적 특징을 사용한 FID_k
- 기하학적인 특징을 사용한 FID_g
- Div_k랑 Div_g는 다양성 점수인데 이건 모든 클립 간 모든 가능한 쌍의 특징 간에 평균 유클리드 거리
- 음악 비트와 댄스 비트 간의 시간 간격의 역수로 계산한 beat-alignment 점수 BAS
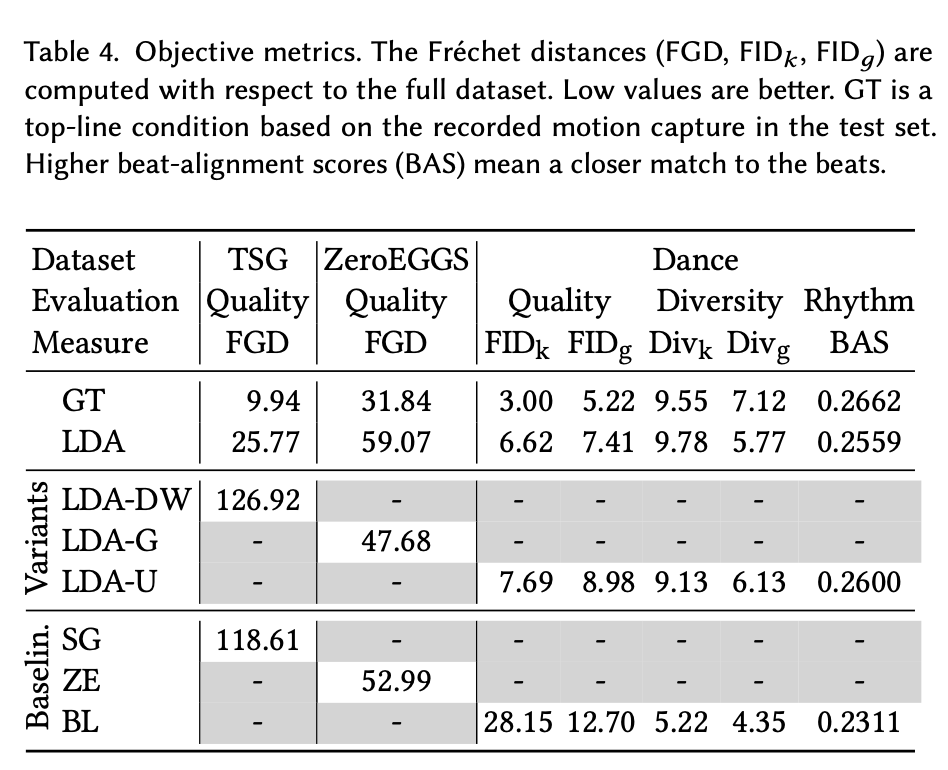
결과가 table 4에 나타나있음. FGD 점수랑 FID 점수는 낮을수록 좋은데 ground truth 쪽 결과가 가장 좋게 나타났음. 객관적 지표라 인간의 인식과 대체로 일치하긴 하지만 안맞는 부분도 있음. 예를 들어 stylegestirue랑 LDA-DW는 거의 유사한 결과를 가지는데 Table3에서 user study를 했을 때는 LDA-DW의 결과가 훨씬 좋았음.
그리고 표를 통해 베일란도 모델보다 우리 모델이 더 다양한 댄스를 생성하고 비트와도 더 잘 정렬되는걸 알 수 있음. 근데 주의해야하는데 비트 매칭이 잘된다고 좋은 댄스는 아님. 자연스러운 댄스는 종종 중첩 리듬도 포함하고 있기 때문
4.6 Path-driven locomotion synthesis
모델을 일반성을 강조하기 위해서 diffusion model이 path-driven locomotion generation을 하도록 훈련시켰음. 루트 노드 모션은 지면 평면 상에 정의되어있는 경로를 따라야했고, 이 경로는 1프레임당 3개의 숫자로 정보를 제공하도록 하였음. 이건 100STYLE 데이터 세트에서 훈련이 되었는데 이 데이터셋에는 다양한 이동 스타일의 모션 캡쳐 데이터가 있고, 스타일 정보 외에도 루트 노드 경로를 설명하는 숫자가 1프레임당 3개로 제공되어서 사용하기 좋았음.

이 모션은 RaisedLeft 스타일의 원형 경로에서 생성된 모션임. 제시해준 스타일과 경로 제어를 정확하게 따라감. foot 안정화를 위한 어떠한 장치도 사용안했지만 foot sliding이 없는 모션을 만들어냄.
Findlay도 diffusion model을 사용한 path-driven locomotion을 생성해냈지만 우리꺼가 더 퀄리티 좋음
4.7 Summary
결론적으로 subective evaluation을 통해서 우리의 모델이 gesture generation과 dance generation 측면에서 기존 모델들보다 더 뛰어나다는걸 증명했음. 그리고 classifier-free guide가 모델의 스타일 표현 강도를 잘 조절할 수 있음을 보였음