
Audio에 따른 dance motion 및 gesture motion을 생성하는 방법론을 제안하는 논문이다. 결과 영상을 보면 알겠지만, stylistic한 모션의 구현을 굉장히 잘하고있다.
https://www.speech.kth.se/research/listen-denoise-action/
https://www.speech.kth.se/research/listen-denoise-action/
www.speech.kth.se
본 논문에서 하고자 하는 task를 더 자세히 말하자면, 주어진 sequence of audio feature a_{1:T}로부터 선택적으로 style vector s를 포함시켜 huamn pose x_{1:T}를 생성하는 것이다. 그럼 본문 내용을 하나씩 살펴보자.
Diffusion model에 대한 설명
논문에 나와있는 내용이 이해하기 힘들어서 따로 포스트로 정리하였다.
https://chickencat-jjanga.tistory.com/140
Diffusion Model 설명
overview Diffusion Model은 data를 만들어내는 deep generative model 중 하나로, data로부터 Noise를 조금씩 더해가면서 data를 완전한 Noise로 만드는 1) Forward diffusion process와 이와는 반대로 Noise로부터 noise를 조
chickencat-jjanga.tistory.com
논문의 내용으로 조금 더 내용을 보충하자면,

Reverse diffusion process에서 x_n이 주어졌을 때 x_n-1이 나올 확률은 다음과 같은데, 이는 multivariate Gaussian density function을 따른다. 이때 sigma의 경우 scaled identity matrix로 세팅했을 때 좋은 결과가 나와 이로 세팅하였다 (원래는 이 값도 diffusion model에서 학습시키는 값인데 여기서는 학습을 안시키고 고정적으로 세팅해주는 듯하다.) 따라서 학습된 distribution은 완전히 mean mu(x_n, n)에 의해 명시되게 된다.
Diffusion model은 보통 score-matching에 의해 학습이 이루어진다. (이거 말고 negative log likelihood -ln p(x_0 | x_1) term도 사용하긴한다.)
score-matching을 활용한 위의 식을 간단히 설명하면, data sample로부터 score를 추정하고, network가 생성한 data로부터도 score를 추정해 두 값의 차이가 적어지도록 학습시키는 식이다.
x_0는 training data D로부터 uniformly하게 drawn 된 값이며, n 역시 {1, ...., N}에서 uniformly하게 세팅된 값이다. noise인 sigma ~ N(0, 1)를 따른다. 그리고 가장 중요한 sigma hat은 x_0에 추가된 noise(sigma)를 예측하는 neural net이다. 이 neural net은 noise 제거 과정과 학습된 확률 밀도 p(x_0)을 정의하게 된다. sigma hat의 인수로 들어간
이 값은 n번째 단계에서 x_n를 의미하며, ~alpha_n과 ~beta_n은 beta 값들에 의해 정해지는 상수이다. 그리고 K_n은 상수이다. 여기서는 [Ho et al. 2020]에서 제안하는대로 K_n =1로 세팅하였으며 이렇게 했을 때 더 나은 결과를 보이는 경향이 있다고 한다.
또한 여기서는 추가 Input으로 c를 넣어주어 conditional neural network인 sigma hat(x, c, n)을 학습하게 된다.
식 (4)에서 흥미로운 점은 단순 제곱 오차를 최소화한다는 점인데, 보통 단순 제곱 오차를 최소화하는 방향으로 학습을 하면, 평균 자세로 회귀하고 자연스럽지 않은 움직임이 발생하는 경우가 많다. 하지만 sigma가 랜덤변수이기 때문에 식 (4)는 단순한 평균 제곱 오차와는 다르다. 사실 식 (4)에서의 score-matching은 data log-likelood에 대한 변분 하한을 최대화한다. (변분하한은 확률 모델링에서 사용되는 통계적 추론 방법 중 하나로 주어진 데이터와 모델 사이의 likelihood를 효과적으로 계산하기 위해 사용된다.)
N이 커질수록 변분 하한은 더 밀접해지며, 극한에서는 확률적 미분 방정식을 얻게 된다. 즉, 여러단계를 거쳐 diffsuion process와 backward process를 진행하는 diffusion model은 확률 분포를 잘 표현하고 데이터 생성 과정을 모방하며, 데이터의 확률적 동적을 설명하는데 효과적인 방법이다.
sampling은 x_N~N(0, 1)에서 시작하여 역방향으로 N 단계의 과정 p를 거쳐 진행하게 되는데, 이러한 reverse sampling 과정은 시간이 많이 소모된다. 특히 N 값이 클 경우에는 더욱 더 시간이 오래 걸릴 수 있다. trained diffusion model로부터 sampling을 빠르게 하는 것이 최근의 strong한 연구 관심사 중 하나이다.
3.1 Model architecture
전체적인 아키텍쳐는 DiffWave architecture를 베이스로 하고 있다. DiffWave 아키텍쳐는 80Hz의 acoustic feature vector들을 input으로 받아 22.5Hz의 scalar-valued audio waveform을 생성해내는 conditional diffusion model이다. 이 네트워크는 내부적으로 dilated convolutions의 residual stack을 사용하였다.
본 논문에서 제안하는 프레임워크의 구조는 다음과 같다. DiffWave 구조를 채택하였으나 sclar output 대신 vector valued를 출력하도록 하였으며, Input과 output의 fps를 같게 하였다. (DiffWave에서는 up sampling으로 output을 만들어냄)
본 프레임워크에서 궁극적으로 학습하고자 하는 바는 p(x_{1:T} | a_{1:T})로, x_t는 t time에서의 pose, a_t는 t_time에서의 acoustic feature이다. 즉, x_{1:T} = x_{1:T, 0}가 되도록 학습하고자한다. 0은 마지막 denosing step을 의미하며, 마지막 denosing step을 거친 결과로 나온 motion이 원본 motion과 같아지도록 학습하는 것을 목표로 한다.
본 논문에서 사용하는 아키텍쳐는 dilated convolution의 Residual stack을 사용하는 DiffWave의 아키텍쳐를 base로 하고 있는데 이 dilated convolution 대신 conformer 또는 transformer를 사용하도록 바꾸었음. conformer는 convolution과 transformer를 합친 구조이다. convolution network는 kinematic적으로 중요한 properties를 학습하는데 장점이 있고 Transformer network는 장기적인 시간 스케일에 걸친 정보를 효과적으로 통합하는데 장점이 있는데 conformer는 이 두 장점을 모두 보유한 구조이다.
Residual block마다 Transformer 또는 Conformer 4개를 사용하였으며 모두 같은 dilation 값을 사용한다. 만약 dilation 값이 1보다 작으면 Transformer를 사용하는 것으로 볼 수 있고, 그게 아니라면 Conformer를 사용하는 것으로 볼 수 있다.
confromer에는 time t의 개념이 없기 때문에 position encoding 메커니즘을 사용해야한다. 이를 위해 여기서는 translation-invariant scheme인 translation-invariant self-attention (TISA)를 사용해 self-attention activations에서의 position t의 Impact를 parameterise했다. translation-invariant하다는 개념은 보통 비전쪽에서 많이 사용되는데 한 이미지 내에서 같은 패턴의 위치가 바뀌더라도 동일한 기능을 유지하는 느낌의 개념으로, 여기서도 같은 data의 위치가 바뀌더라도 결과의 영향이 없도록 TISA 방법을 사용했다고 보면 된다. (즉, 이건 1:T 중 어디에 위치하는지를 나타내는 정보를 encoding한거)
여기서 n은 diffusion step 몇 번 단계를 거치고 있는지를 의미하며 이 값을 DiffWave와 동일하게 sinusoidal embedding을 사용하여 인코딩하였고 (이게 e(n)으로 표기된다) 이를 feed-forward network를 거치게 해서 denosing network에서 사용하게 하였다.
Conformer들은 ReLU 함수와 gating operation을 사용하였다. (gating operation: 이 연산은 입력 데이터를 조절하거나 선택적으로 전달하여 모델이 중요한 정보를 기억하고 잊을 수 있도록 하는 메커니즘을 제공)
기존의 diffusion model이 audio가 아닌 Text에 condition되어 gesture나 dance Motion이 아닌 simple action을 만들었다는 점에서 기존의 diffusion model을 사용한 연구와 차별성이 있음. 또한 denosing network의 아키텍쳐 자체도 다른데, 기존 연구들이 denosing network의 아키텍쳐에 transformer를 썼던거에 반해, 우리는 Conformer를 사용함. 또한 position information을 encoding하기 위해 sinusoidal position encoding들을 사용했던 기존 연구들에 반해, 이 연구에서는 translation-invariant scheme를 사용하였다. sinusoidal position encoding을 사용하면, training에서보다 더 길이가 긴 sequence에는 사용이 안된다고 한다 (여기서는 input sequence의 길이가 길어지면 사용이 안되는거겠지)
3.2 Style control with guided diffusion
본 framework에서는 conditional diffusion model을 사용하여 motion의 style을 control할 수 있을 뿐만 아니라 style의 강도까지 조절할 수 있는 메커니즘을 제공하고 있다. style을 control하는 것은 network의 output으로 나오는 sigma hat을 style에 conditioned 시켜서 달성할 수 있고, style의 강도를 조절하는 건 guided diffusion이라는 테크닉에서 lambda 값을 tuning하는 방식으로 denoising process distribution을 조절한다.
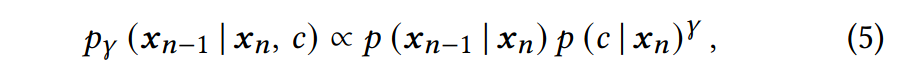
위의 식에서
𝑝(𝒙_{𝑛−1} | 𝒙_𝑛)는 이미지의 상태변화를 모델링하는 확률 분포고
𝑝(𝑐 | 𝒙_𝑛)^𝛾 이 부분은 현재 이미지 상태가 주어졌을 때 c의 확률을 모델링하였다. 𝛾 값이 커질수록 c의 영향이 커짐을 의미한다. 이때 주어진 class c의 가장 뚜렷한 예제에 초점을 맞추어 diffusion process를 진행하게 된다. 즉, guided diffusion에서는 위의 식이 성립하도록 diffusion process를 진행시켜야한다.
위의 작업들은(classfier를 생성하지 않고 특정 class의 예시 모션을 제공함으로써 조건화하는 그러한 방식) conditional diffusion model과 unconditional diffusion model을 결합해서 달성할 수 있다. 이런걸 classifier-free guidance라고 부른다. 다르게 말하면 diffusion model은 조건화된 model의 output과 조건화되지 않은 model의 output을 모두 계산하고 이를 조합하여 최종 output을 만들어낸다.
즉, 오디오에만 조건화된 diffusion 결과(unconditional diffusion model)와 오디오와 스타일에 조건화된 diffusion 결과(conditional diffusion model)를 결합한다는 의미이다.
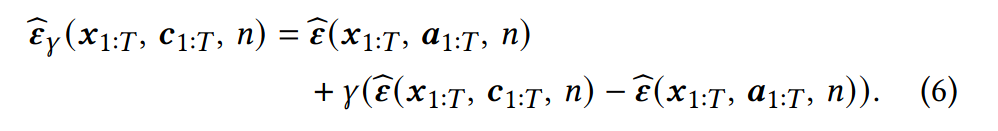
식은 다음과 같다. lamda의 값에 따라 스타일 Input의 영향을 강조하거나 약화시킬 수 있다.
실험에서는 이렇게 style guidance를 제공했을 때와 제공하지 않았을 때 (그냥 style label을 One-hot encding해서 s로 사용하고, time t sequence동안 변하지 않는 값으로 사용) 를 비교해보았다.
또한 이 모델을 사용하면 style-conditional model과 style-unconditional model 둘다 사용할 수 있는데, 이를 위해서는 style information s_{1:T}를 training 중에 랜덤으로 드랍시키면 된다. 근데 이건 필수적인건 아님. 각각 따로 학습시킨게 더 성능이 좋아서 실험에서는 각각 따로 학습(conditioned와 unconditioned) 시킨걸 사용했음.