
https://chickencat-jjanga.tistory.com/63
Motion Fields for Interactive Character Animation 정리(1)
본 논문에서는 motion field라는 structure를 제안하고 있다. motion field는 어떻게 구성되는지, 또 어떠한 장점이 있는지 차근차근 알아보자. Preliminary Definition 1. Motion States character의 state m를 character 모
chickencat-jjanga.tistory.com
지난 포스트에서 Motion States 표현을 어떻게 하는지, Motion Database는 어떤식으로 생성하는지 Action값이 정해졌을 때 next motion state는 어떻게 결정하는지 알아보았다.
이제 가장 중요한 Control part를 살펴보도록 하자.
Control
user input을 가장 잘 반영하는 action 값을 어떻게 만들어낼 수 있는지 살펴보자!
1. Markov Decision Processes Control
(1) State
State 값으로 motion state만 사용하면, user-specified task를 수행하기에 충분하지 않다. 그래서 task parameter를 추가해서 state로 사용한다.
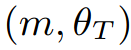
예를 들어 한방향으로 움직이는 task의 경우에는 theta_t의 값으로 single number(angular deviation from the desired heading)을 사용한다. 이 값을 바꾸면서 user는 character의 direction을 control 할 수 있다.
(2) Action
각 task state에서 motion field는 다음 frame을 결정하기 위해 set of actions A(m)을 결정해야한다. A(m)에는 무한히 많은 actions들이 있는데 MDP를 solve하기 위해서는 각 state마다 finite set한 actions이 있어야한다. 이 MDP controller의 요구조건을 만족시키기 위해 우리는 A(m)으로부터 finite set of action A(s)를 뽑아낸다.
motion state m이 주어졌을 때, similarity weight를 수정하여 k actions를 만들어낸다. 각 action은 다른 neighbor보다 특정 한 neghbor를 선호하게 된다.

즉, action a_i는 similarity weights에서 w_i를 1로 세팅하고 renormalize한 것이다. (i 번째 neighbor의 영향을 크게 한 것이라고 보면 된다.)
위와 같이 action을 세팅하면 characer에게 충분한 유연성을 부여하면서도 m과 크게 다르지 않은 motion을 만들어낼 수 있다.
(3) Transitions
state 표현이 바뀌었기 때문에 intergation function도 task parmeter를 반영하여 재정의해야한다.
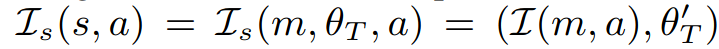
task parameter는 state가 update될때마다 tuning해주면 된다.
(4) Rewards
direction following task의 경우, desired heading으로부터 small deviation을 유지할 때 high reward를 준다. 이런식으로 task를 얼마나 잘 수행하는지에 따라 reward를 다르게 준다.