
https://lava.kaist.ac.kr/?page_id=6467
https://arxiv.org/abs/2202.05274
Motion Puzzle: Arbitrary Motion Style Transfer by Body Part
This paper presents Motion Puzzle, a novel motion style transfer network that advances the state-of-the-art in several important respects. The Motion Puzzle is the first that can control the motion style of individual body parts, allowing for local style e
arxiv.org
Motion Puzzle 논문에서는 body part 별로 원하는 스타일을 적용할 수 있는 framework를 제안하고 있다. style 관련된 부분은 아직 잘 모르긴하지만, 참 참신하고 잘 쓰인 논문이라는 생각이 들었다!
1. 전체적인 설명
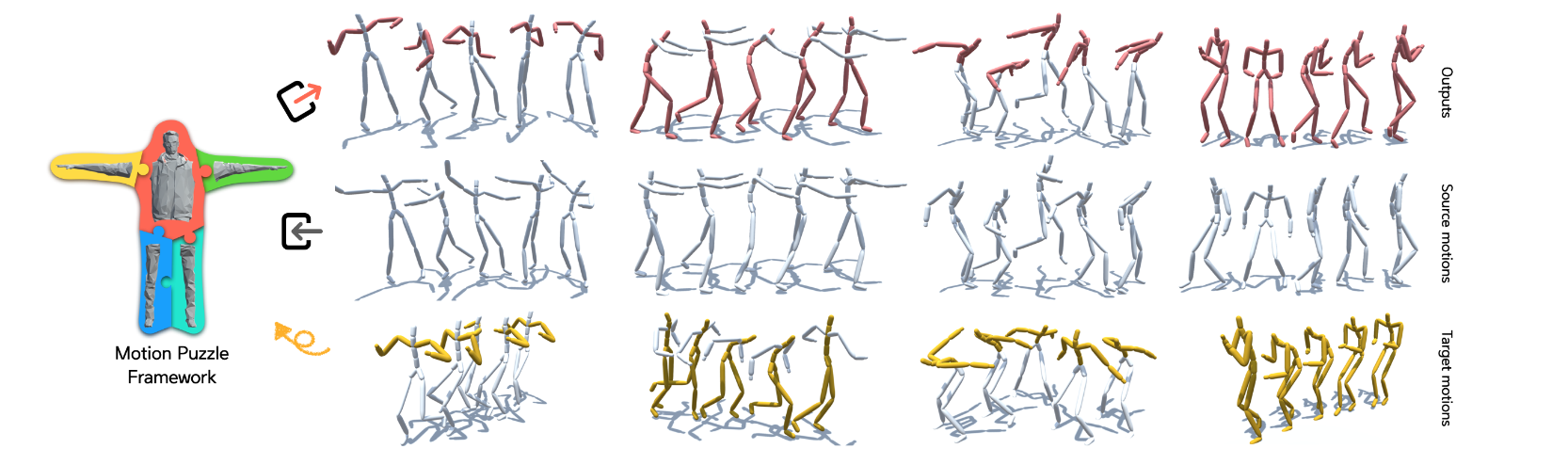
Figure1 그림을 보면, Motion Puzzle framework의 역할을 전체적으로 알 수 있다. 하나 또는 여러개의 target motions들로부터 body 전체의 style 또는 부위별로 style들을 추출하여 하나의 source motion에 적용한다. 결과적으로 상단의 stylized whole-body motion을 얻을 수 있다.
Motion Puzzle 논문에서 설명하는 본 논문의 contribution은 다음과 같다.
- 개별 body part별로 control할 수 있는 motion style transfer method를 처음으로 제안
- motion style의 global features와 local features를 시공간적으로 transfer할 수 있는 two-step style adaption network, BP-StyleNet을 제안. 이를 통해 time-varying style feature도 capture하고 translate할 수 있다.
- style labeling이나 training data의 motion pairing 필요없이 arbitary style transfer이 가능하다
Motion Puzzle에서 사용하는 dataset은 다음과 같다.
- motion dataset으로는 unlabeled styles의 다양한 motion을 제공하는 CMU motion data를 사용
- unseen test data로 dataset of [Xia et al 2015] 사용
- 인접한 clip끼리 60 frame씩 겹치게, 120 frame clip으로 끊어서 사용
- data representation은 다음과 같음
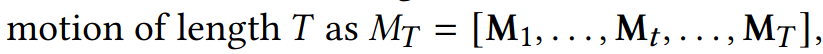
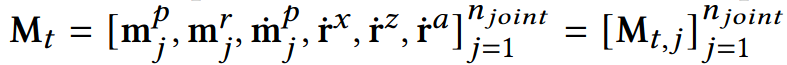
- 차례대로, character forward facing direction에 대해 표현된 1) joint local position 2) joint local rotation 3) joint local velcotiy. 그리고 current frame에 대해 표현된 previos frame에 상대적인 4) root translational velocity in x direction 5) root translational velocity in z direction, 6) root의 angular velocity about y axis 를 의미한다.
2. Overall network architecture of Motion Puzzle framework
Motion Puzzle framework에서는 시공간적으로 연관되는 여러개의 joint가 움직이는 complex human motion을 다루기 위해, spatial-temporal graph convolutional network를 framework의 basis로 사용한다. 그리고 graph pooling-unpooling method를 사용하여 graph와 human body part structure를 일치시킨다.
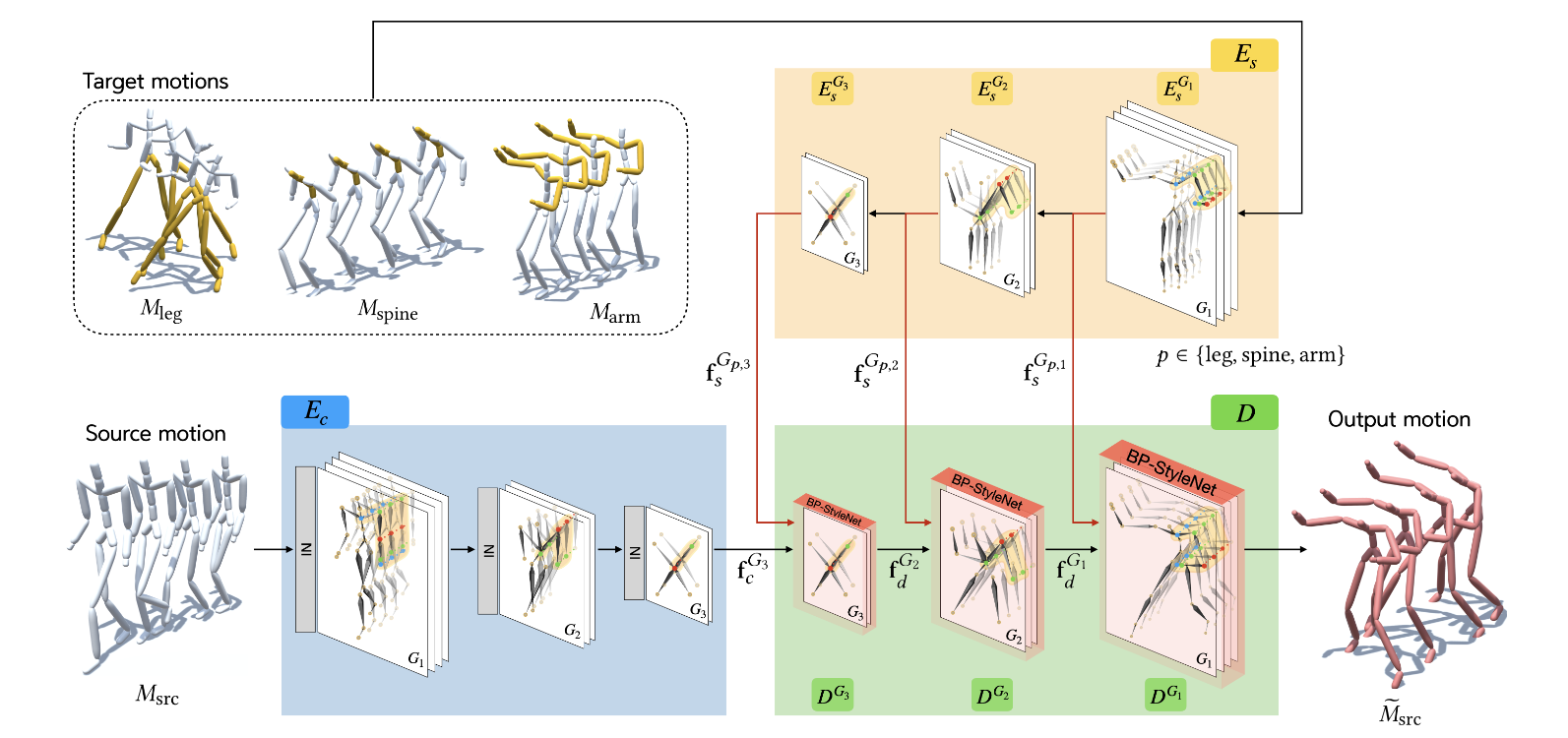
앞에서도 한번 설명했지만, framework의 Input과 output은 다음과 같다.
- Input: one source motion for content and multiple target motions (최대 5개)
- Output: stylized whole-body motion
2-1) Skeleton based Graph Convolutional Network
human motion에서 시공간적 relationship이 존재한다는 특징을 modeling하기 위해 Motion Puzzle framework에서는 spatial-temporal graph를 사용한다.
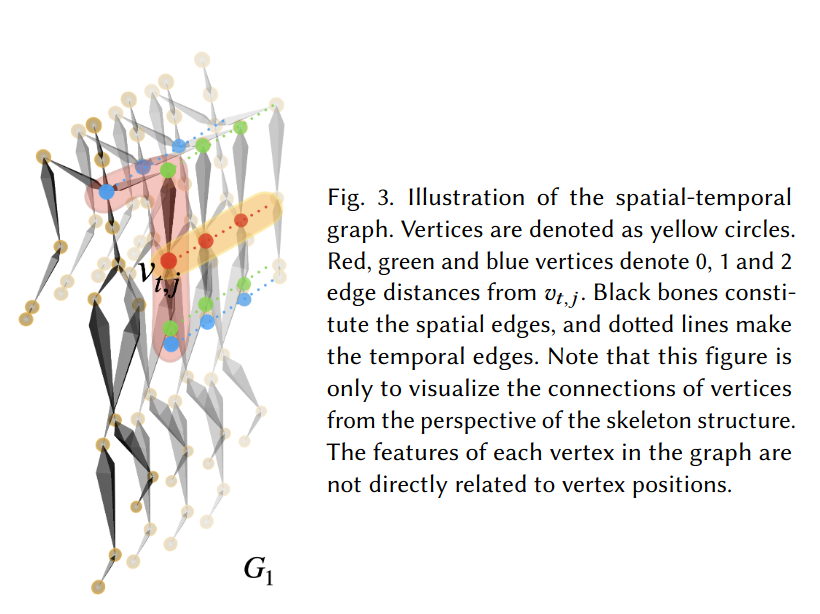
위의 그림에서 spatial-temporal graph G_1 = (V_1, E_1)이 나타나고 있다.
vertex set V_1은 skeleton sequcne의 모든 joint에 대응된다.
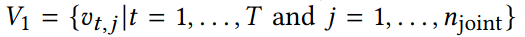
Edge set E_1은 두 종류의 edge를 포함하고 있다. 각 프레임에서 인접한 joint들에 해당하는 vertex끼리 잇는 E_B와 인접한 프레임에서 같은 joint에 해당하는 vertex끼리 잇는 E_F 로 구성되어있다.
이런식으로 graph 구조를 쓴다는건 이해했는데 더 자세한 내용은 생략했다..어차피 가져다 쓸거고 내가 구현할게 아니니까...?!ㅎㅎ 필요하면 다시 읽어봐야겠다...
2-2) Style Encoder
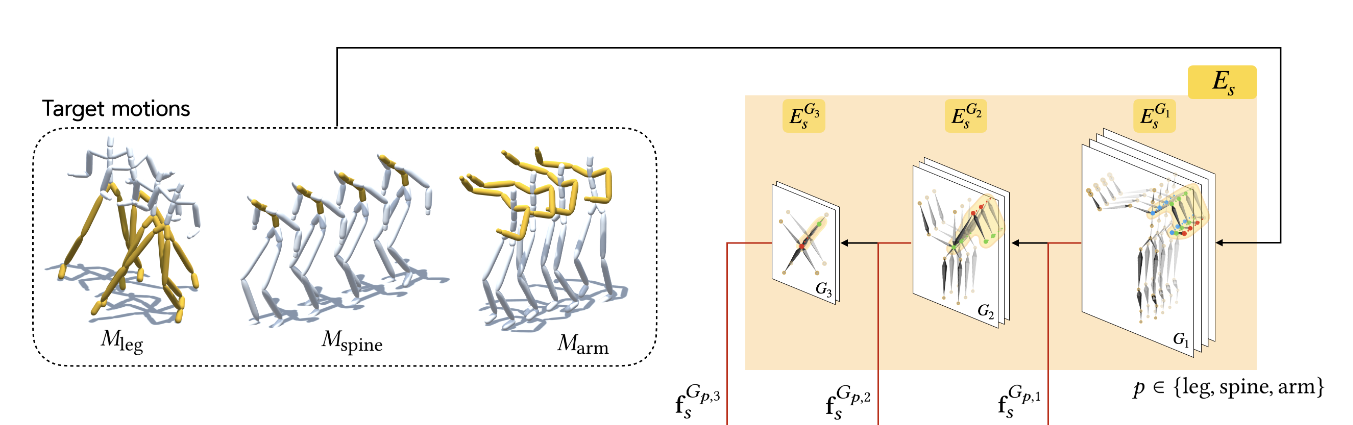
style encoder는 3개의 encoding block으로 이루어져있다. 그리고 각 블록마다 style feature를 만들어낸다. 이 style feature들은 decoding process에서 style을 transfer할 때 progressively하게 사용된다.
각 level의 feature들은 5 part의 features로 나누어진다.
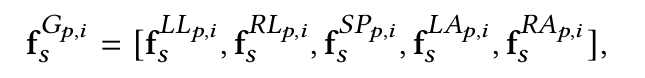
LL, RL, SP, LA, RA은 graph G의 subset vertices를 의미하며 각각 left leg, right leg, spine, left arm, right arm을 의미한다. 이러한 분할 덕분에 body part별로 style을 transfer하는 것이 가능하다. 즉, whole set of style features는 모두 다른 motion으로부터 만들어지는 것이 가능하다. 또한 각 part-feature는 temporal lengths를 다르게 가지는 것도 가능해서 자유로운 style control이 가능하다.
2-3) Content Encoder
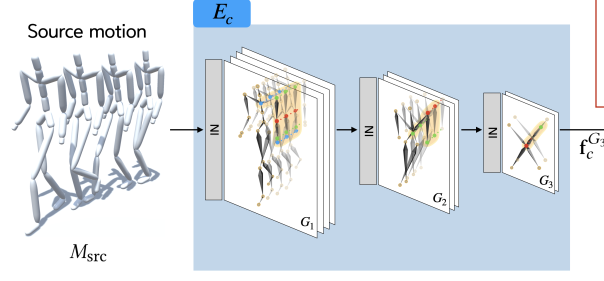
content encoder도 style encoder와 유사한 구조를 가지고 있다. 다만 다른 점은 1) style variation을 없애기 위해 모든 STGCN layer마다 Instance Normalization을 진행한다는 점과 2) final output만을 사용한다는 점이다.
content feature는 style feature과 같이 human's five body parts에 맞는 graph structure를 가지고 있다. 이러한 structure는 human motion을 reconstructing하고 per-body-part style tranfer에 핵심적인 역할을 한다.
2-4) Decoder
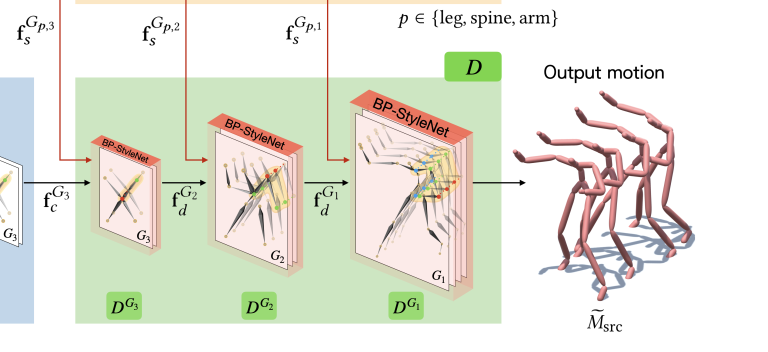
Decoder는 multi-level target style features를 사용하여 content feature를 output motion으로 만들어주는 역할을 한다. 각 level의 decoding block은 1) BP-StyleNet와 2) Unpooling layer로 구성되어 있다.
1) BP-StyleNet
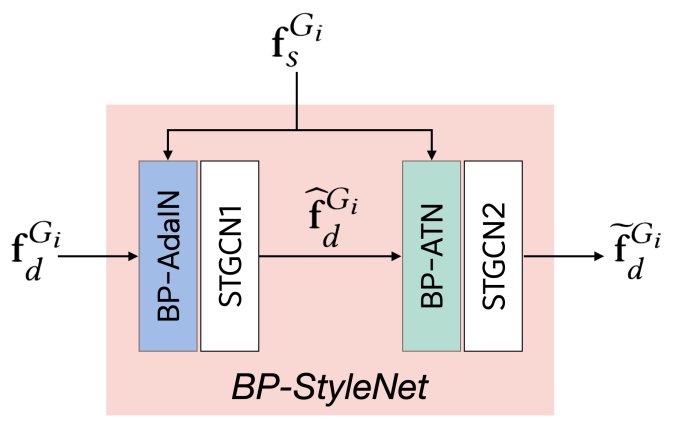
BP-StyleNet은 (1) BP-AdaIn과 (2) BP-ATN으로 이루어진다.
BP-AdaIN style feature의 global statistics를 transfer하는 역할을 하고, BP-ATN은 style feature의 local feature를 transfer하는 역할을 한다. 결론적으로 BP-StyleNet의 output은 style feature의 local trait과 global trait을 모두 reflect하게 된다.
BP-AdaIn에서는 아래식과 같이 body part별로 AdaIN 연산을 적용하게 된다.
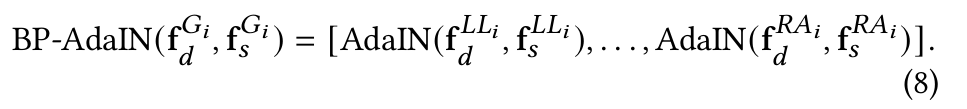
AdaIn 연산방식은 다음과 같다.
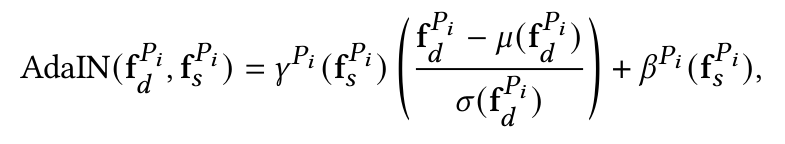
작성예정...논문 왤케 어렵냐?