
집중안되는데 용케 다 읽었다..고생했으

https://arxiv.org/abs/2009.02119
Speech Gesture Generation from the Trimodal Context of Text, Audio, and Speaker Identity
For human-like agents, including virtual avatars and social robots, making proper gestures while speaking is crucial in human--agent interaction. Co-speech gestures enhance interaction experiences and make the agents look alive. However, it is difficult to
arxiv.org
Speech Gesture Generation from the Trimodal Context of Text, Audio and Speacker Identity 논문은 trimodal context of speech(speech audio, speech text, speaker id 정보)를 받아 그에 맞는 gesture 동작을 만들어내는 framework를 제안하고 있다.
기존의 data-driven approach(end-to-end 방식)에서는 single modality(speech audio나 text)만 고려하여 limited model만 만들었지만, 본 연구에서는 speech text, audio, speaker identity를 모두 고려하였다는 점에서 의의가 있다.
또한 style emedding space에서 다른 point를 고르게 되면, 같은 speech에서도 다양한 style의 gesture를 만들어내는게 가능함을 보여주었다.
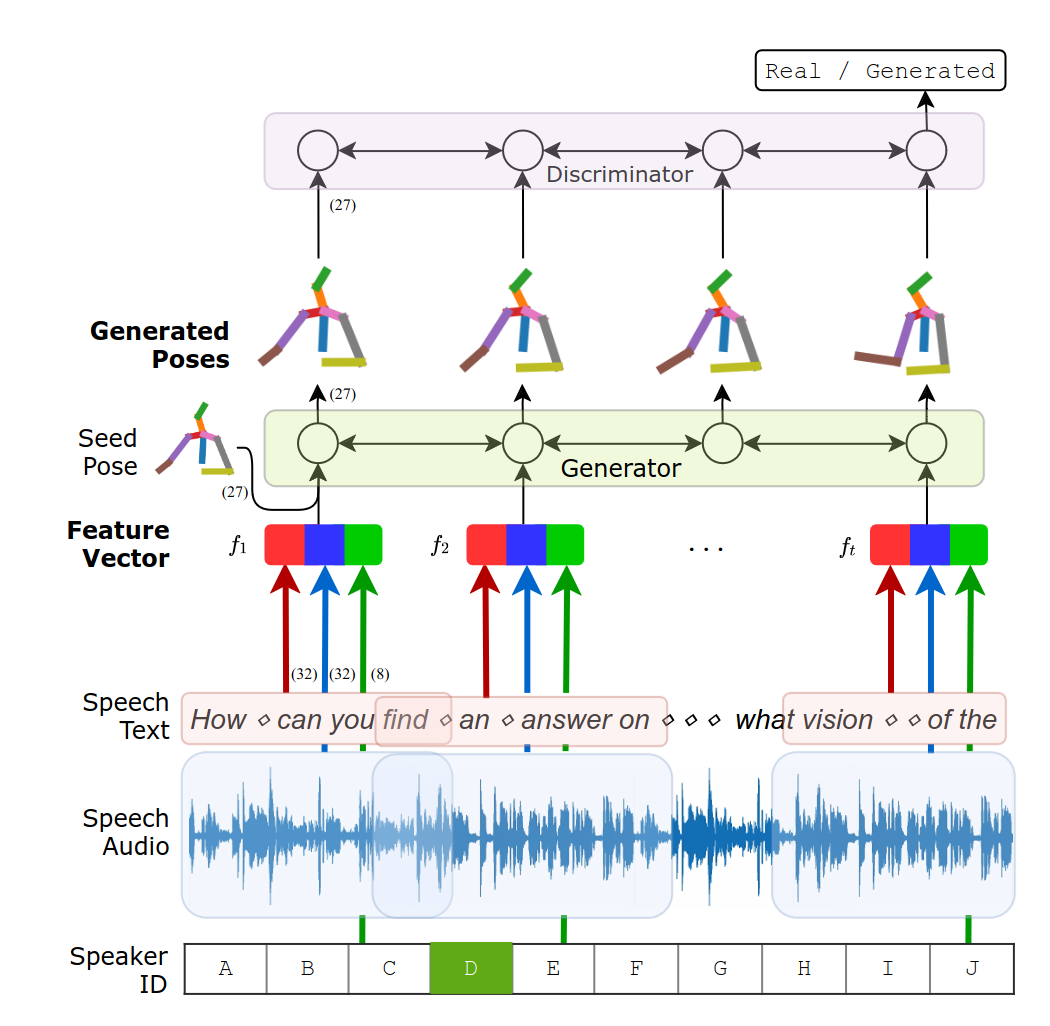
1. Overall Architecture

nerual network는 input speech modalities를 위한 3개의 encoder와 gesture generation을 위한 1개의 decoder로 구성이 되어있다. gesture는 sequence of human poses로 표현되며, generator는 Recurrent neural netowrk로 되어있다. 또한 encoded speech context를 포함하고 있는 Input sequence of feature를 받아 pose를 frame-by-frame으로 만들어낸다.
Speech와 gesture는 temporally synchronized되어있다. 그래서 generator는 current time step 근처의 speech text와 audio를 받는다. (speech text 전체와 audio 전체를 받는게 아니라)
또한 first few frames에 대해 poses를 seed 하여 연속성이 더 나은 동작들을 합성할 수 있었다.
2. Encoding Speech Context
일단, input data를 output gesture와 같은 time resolution을 가지도록 하여, speech input과 generate pose를 frame by frame으로 할 수 있게 하였다.
2-1. speech text
word sequence에 padding token을 삽입하여 padded word sequence(word_1, word_2, ..., word_t) 를 만들어낸다. padding token을 넣는 이유는 gesture와 temporally match되도록 하기 위해서이다.
이 padded word sequence는 word embedding layer를 거쳐 300 dimension의 word vector로 transformed된다.
그리고, 이 word vector들은 temporal convolutional network(TCN)을 거쳐 32-D feature vector(f^text_1, f^text_2, ...f^text_t)로 만들어진다. TCN은 convlutional operations을 통해 sequential data를 가공한다. 본 논문에서는 four-layered TCN을 사용하는데, 각 f^text_i는 time step i 근처의 16개의 padded word를 가공한다.
2-2. speech audio
Raw audio waveform은 1D convolutional layers를 거쳐 32-D feature vectors sequence(f^audio_1, f^audio_2, ... f^audio_t) 로 가공된다. 실험에 따르면 각 feature vector는 1/4초의 receptive filed를 가지고 있다. 1/4초의 receptive field는 때때로 발생하는 speed-gesture asynchrony를 cover하기엔 충분하지 않다고 알려져있으나, Gesture generator의 bidirectional GRU가 이를 커버할 수 있다.
2-3. speaker ID
model은 style embedding space를 학습하기 위해 speaker IDs도 사용한다. 한가지 알아둬야하는 점은 목적이 서로 다른 style을 capture하는 embedding space를 구축하는 거지, 각 화자의 gesture를 복제하는게 아니라는 점이다.
speaker IDs는 one-hot vectors로 encoding된다. fully connected layers가 이 speaker ID를 훨씬 작은 차원을 가지는 style embedding space로 mapping 시킨다. style embedding space를 더 interpretable하게 만들기 위해 variational inference(확률적 sampling process를 사용하는) 가 사용된다.
또한 합성의 all time step에서 style embedding space의 feature는 같은걸 사용한다.
3. Gesture Generator
generator는 encoded feature(speech text, audio, speaker id로부터 뽑은 Encoded features가 concatenate된 feature vector)를 Input으로 받아 gestures을 생성해낸다.
3-1. gesture representation
각 Human pose는 10개의 upper body joint로 구성되어있으며(spine, head, nose, neck, L/R shoulders, L/R elbows, and L/R wrists) 9개의 directional vectors(spine-neck, neck-nose, nose-head, neck-R/L shoulders, R/L shoulders-R/L elbows, R/L elbows-R/L wrists)로 표현된다. 각 vector는 unit length를 가지도록 normalized되며, 이러한 표현을 사용했을 때 bone length와 root motion의 영향을 덜 받는다는 장점이 있다.
3-2. architecture
generator는 multilayered bidirectional gated recurrent unit(GRU) network를 사용하였다. generator는 feature vector f_i를 받아 next pose d hat_{i+1}를 반복적으로 생성해낸다.
또한 long speech를 위해 speech는 2초 단위의 chunk로 나눠지며 gestures를 각 chunk 단위로 합성한다. 이때 transition을 smooth하게 하기 위해 previos synthesis에서 last four frame을 seed pose(d_{i=1, ,,,4})로 사용한다. seed pose는 feature vector와 concatenated 되어 next synthesis에 (f_i, d_i) 형태로 들어간다.
3-3. adversarial scheme
discriminator에 대해서, multilayered bidirectional GRU를 사용하는데 각 time step마다 binary output을 만들어내고 이 t개의 binary output을 모아 최종적으로 real인지 generated인지 판단을 내린다.
4. Training
4-1. dataset
TED 영상 dataset을 사용하였다. upper body가 clearly visible한 부분은 97h 분량이였고, gesture pose를 15 frame per second로 Resample하고, 각 training sample한 34 frames를 가지도록 stride 10 frame sampled 되었다. 초반 4개의 Frame은 seed pose로 사용되었으며, 30 poses(2초 분량, 하나의 chunk)를 generate 하도록 하였다.
dataset은 training, vadliation 그리고 test sets으로 division되는데, 이러한 division은 video level에 따라 수행된다. TED dataset은 모드 다른 speaker들에 의해 수행되었기 때문에 unique speaker ID의 수는 비디오의 수와 동일하다. 따라서 split set 간에 spekaer ID는 겹치지 않는다.
4-2. Training Loss Function
t는 gesture sequence의 length를 의미하고, d_i는 i번째 pose(directional vector로 표현된)를 의미한다.
encoder와 gesture generator를 학습시키기 위해 다음의 loss function을 사용하였다.

discriminator를 학습시킬 때는 다음의 loss function을 사용하였다.
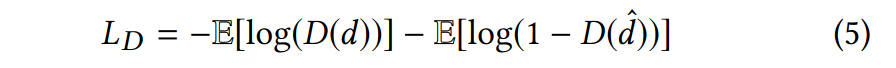
식 (2) encoder와 gesture generator를 학습시킬 땐, training example에 있는 Human pose d와 generated pose d hat 과의 차이를 최소화 할 수 있도록 Huber loss(L^Huber_G)를 사용하였다.
식 (3), (5) discriminator를 학습시킬 때 사용하는 L_D와 encoder 및 gesture generator를 학습시킬 때 사용하는 L^NSGAN_G는 non-saturating generative adversarial network (NS-GAN)에서 가져왔다. generator와 discriminator는 L_G와 L_D에 의해 번갈아가면서 update된다.
식 (4) multiple한 input context에 condition된 generative model에서 weak context가 무시되는 posterior collapse 현상을 겪을 수 있다. 본 모델에서는 speaker IDs가 상대적으로 약한 context라 무시될 수 있다. 이렇게 style feature가 무시되는 것을 피하기 위해 diversity regularization을 사용하였다.
L^style_G는 different style features에 의해 생성된 gestures 간의 Huber loass이며, 이 loss term은 embedding space의 style features가 다른 gesture를 만들도록 guide하는 역할을 한다.
tau는 numverical stability를 위한 value clamping을 위한 것이다.
또한 f^{style_1}은 training sample의 speaker ID에 대응되는 style feature이고 f^{style_2}은 randomly selected ID에 대응되는 style feature이다.
식 (1) L^KLD_G는 N(0, I)와 스타일 임베딩 공간 사이의 쿨백-라이블러(KL) 발산으로, 스타일 임베딩 공간이 너무 희소해지는 것을 방지하기 위해 사용된다. KL 발산은 두 확률 분포 사이의 차이를 측정하는 지표로서, 여기서는 스타일 임베딩 공간과 표준 정규분포(N(0, I)) 사이의 차이를 계산하여 사용한다.
스타일 임베딩 공간이 너무 희소하게 되는 것을 방지하기 위해 KL 발산을 사용하는 이유는, 너무 희소한 스타일 공간은 모델이 다양한 스타일을 포착하는데 어려움을 줄 수 있고, 적절한 스타일 임베딩을 찾는 것을 어렵게 만들 수 있기 때문이다. 따라서 L^KLD_G는 스타일 임베딩 공간을 보다 밀집하고 다양한 스타일을 잘 표현할 수 있도록 유도한다.
이렇게 학습된 encoder와 generator는 synthesis stage에서 사용된다. model이 가벼우므로 real-time으로 합성이 가능하다.