
오늘두 역시나 gesture generation 관련 논문 리뷰! 작년 Siggraph Asia에서 직접 발표를 들었던 논문이라 더 반갑게 읽었던 것 같다. 그때도 생각했던거지만 다시봐도 결과물의 퀄리티가 꽤 괜찮다. 교수님 허락만 맡으면 논문세미나에서 발표할 생각이라 꽤 열심히 읽었지롱

https://arxiv.org/abs/2209.07556
ZeroEGGS: Zero-shot Example-based Gesture Generation from Speech
We present ZeroEGGS, a neural network framework for speech-driven gesture generation with zero-shot style control by example. This means style can be controlled via only a short example motion clip, even for motion styles unseen during training. Our model
arxiv.org
https://www.youtube.com/watch?v=EJPdTtVrxHo
Zero-shot Example-based gesture generation from speech 논문에서는 speech audio와 원하는 style의 짧은 motion clip을 input으로 받아, speech에 맞는 원하는 style의 gesture를 generation하는 framework를 제안하고 있다. style을 word로 표현하는데는 한계가 있는데 여기서는 example motion clip을 넣어주기만 하면 된다는 점과, training dataset에 포함되지 않는 motion clip도 style을 잘 캡쳐해서 사용할 수 있다는 점에서 굉장히 편리하다.
1. System Overview
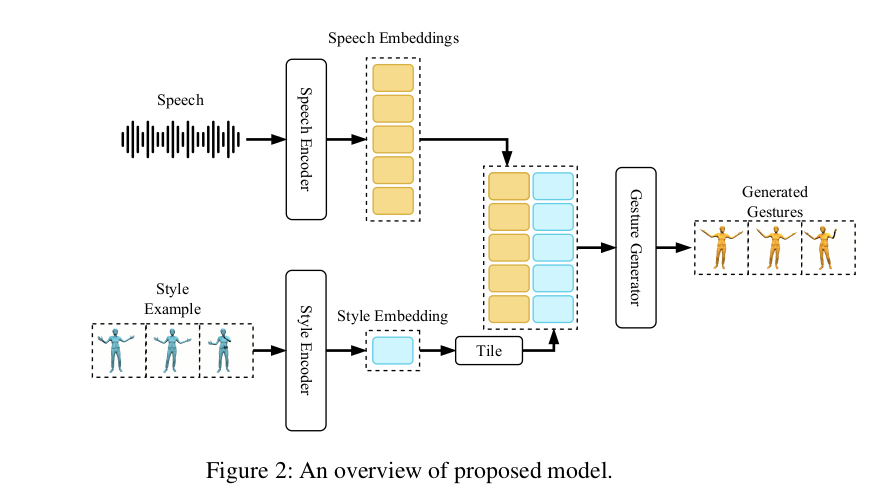
앞에서 언급했던 대로 raw speech audio와 원하는 style의 짧은 motion clip을 받아 gesture를 generation한다. model은 크게 3가지의 component로 구성된다. (1) Speech Encoder, (2) Style Encoder, (3) Gesture Generator
각각의 역할에 대해서는 아래에서 살펴보자.
2. Speech Encoder
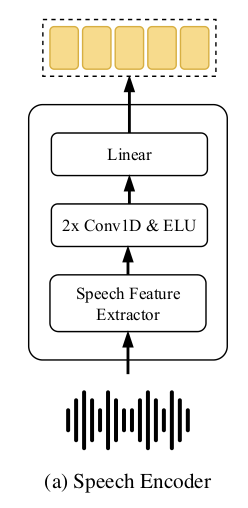
<역할> speech encoder는 sequence of raw speech data를 speech embedding sequence S로 변형시킨다.
<과정> 먼저 raw audio samples를 spetrograms로 변형한다. (여기서는 log-amplitude of the spectrogram과 mel frequence scale을 많은 gesture generation에서 용하는 값으로 설정하였다.) 또한 supplementary feature로 energy per frame도 extract하였다. 이렇게 raw audio samples에서 뽑은 feature들은 re-sampled되어 1D convolution layer와 non-linear operators를 지난다. 마지막으로 frame-wise linear layer를 거치게 되면 이 결과가 a sequence of embedding vectors S = [s_0, s_1, ...s_{T-1}]가 된다. (여기서 T는 number of frames in the sequence를 의미한다.)
3. Style Encoder
<역할> Style Encoder는 reference style animation clip을 reference style의 general attirbute를 capture하는 low dimensional, fixed size, embedding vector로 변형시킨다.
<전체적인 특징> Style Encoder는 VAE framework(Variational Auto-Encoder) 를 사용하였는데, VAE는 latent space를 학습하는 확률적 생성모델로, 입력 데이터를 encoding하여 latent space로 표현하고 이를 디코딩하여 입력 데이터를 재구성하는 방식이다. 잠재공간에서 데이터의 특성을 분리하여 학습하기 때문에 보간(interpolation)을 통해 서로 다른 특성을 조합하는 것이 가능하다. 또한 모델로부터 다양한 변형된 데이터를 얻을 수 있다는 장점이 있다.
<표현> reference motion의 각 frame은 다음의 feature vector로 표현된다.
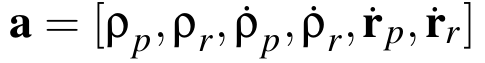
각각 joint local translations(3*j차원) , joint local rotations(6*j차원), joint local translational velocities(3*j차원), joint local rotations(3*j차원), root translational velocity local to the character root transform(3차원), root rotational velocity local to the character root transform(3차원)을 의미한다. (j는 joitn 개수)
joint rotation은 2-axis rotation matrix로 표현되었으며, joint and root rotational velocities는 rotation vector로 표현되었다.
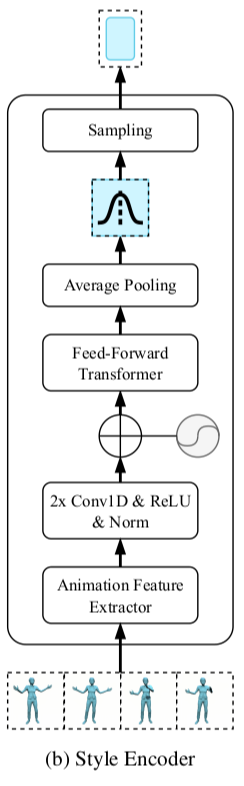
<과정> Style Encoder가 reference style animation clip을 embedding vector(차원수 D_e)로 변형시키는 과정은 다음과 같다.
먼저 sequence of feature frames A = [a_0, a_1, ...a_{M-1}]가 normalize되어 neural network의 input으로 들어간다. A는 2개의 1D convolutional layers를 지나는데 각 layer에는 ReLU와 layer noramlization layer가 적용된다.
Positional encoding이 sequence ordering을 Encode할 수 있도록 해주며, Feed-Forward Transformer block을 적용하였다. Feed-Forward Transformer block에는 multi-head self-attention layer와 2개의 convolution layers가 구현되어있는데 각 convolution layer마다 residual connection과 layer normalization이 뒤따라오게 된다.
이 과정을 거치게 되면 sequence of shape {M X 2D_e}가 나오게 되는데 이 모든 seuqence를 average 하여 D_e-dimensional multivariate Gaussian distribution의 평균값과 분산값을 구한다. 그리고 final style embedding vector를 distribution에서 sampling하여 얻게 된다.
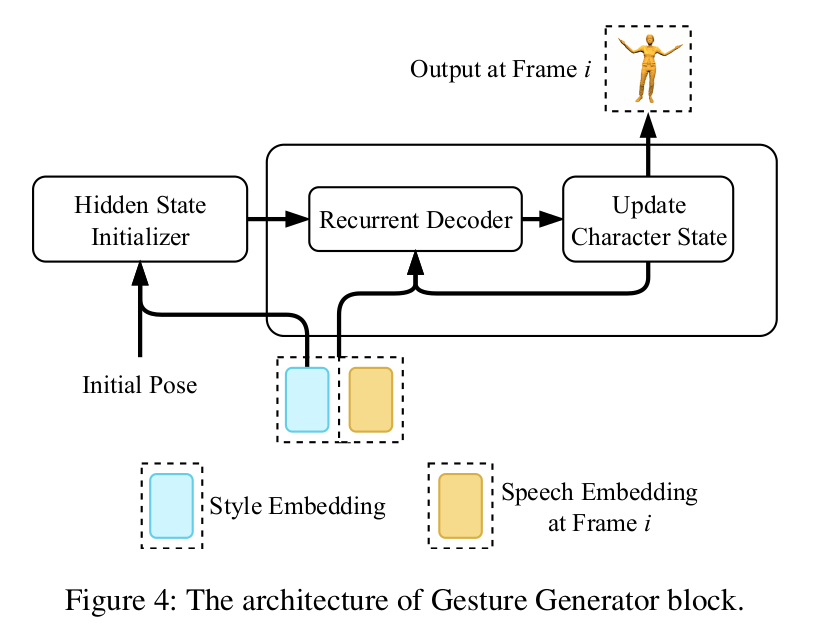
4. Gesture Generator
<역할> gesture generator는 conditional auto-regressive model로, speech embedding sequence S와 reference style embedding vector e를 받아 final geesture sequence Y = {y_0, y_1, ...y_T_1}를 만들어낸다.
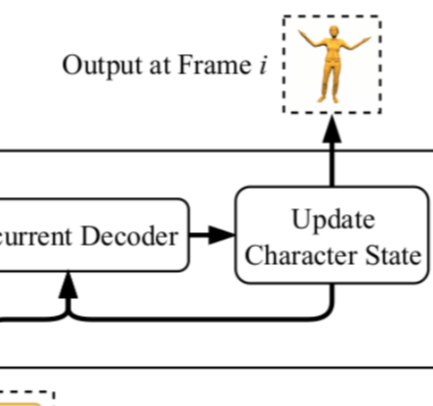
<표현> 각 frame의 output pose state는 다음과 같이 표현된다.
style encoding에서 각 frame의 feature vector와 매우 유사하다. r_p와 r_r 부분만 추가되었는데 각각 position or root와 orientation of root(quaternion으로 표현)를 의미한다. r_p는 각 frame의 root translational velocities를 사용해 update되고, r_r은 각 frame의 rotational velocities를 사용해 update된다.
<과정>
(1) Recurrent Decoder
gesture generator의 핵심은 Recurrent Decoder 부분이다. Recurrent Decoder는 auto-regressive neural network로, 2개의 Gated Recurrent Units (GRU)로 구성되어있다. Recurrent Decoder는 previous pose state vector y_{i-1}(사실 이것만 하는건 X, 뒤에 더 자세히 후술)과 reference style embedding vector e, speech frame s_i를 받아 frame i의 pose encoding을 만들어낸다.
또한 추가적으로 알아야할 부분이 있는데, rotational drifting을 막기 위해, fixed target facing direction도 recurrent decoder에 condition 시키고 있다. target facing direction을 world space에서 characer root transform으로 바꾸고, previously generated pose state와 concatenate 시키고 이를 normalize 시켜 Recurrent Decoder에 제공한다. (제공하는 곳은 Update Character State Block)
(2) Update Character State block
Recurrent Decoder의 output으로 나온 pose encoding을 받아 pose state를 계산하고 character facing direction을 update한다.
pose state를 계산하기 위해 Recurrent Decoder의 output을 denormalize하고, predicted root translational and rotational velocities를 사용해 root transform을 update한다.
(그리고 위에서 후술했던 것처럼 target facing direction을 root transform으로 바꾸고 pose state와 concatenate 시켜 recurrent decoder에 제공한다.)

(3) Hidden State Initializer
Hidden State Initializer는 별도의 neural network로, inital pose, character facing direction, style embedding을 기반으로 GRU layer에 hidden states를 제공한다. 이렇게
이렇게 별도의 initializing network를 사용하면 result의 quality가 좋아진다고 한다.
3개의 linear layer와 ELU activation functions을 사용한다.
5. Dataset and Data Preparation
full body motion은 60fps로 표현되며 skeleton의 joint에는 finger와 hand joint까지 모두 포함된다. 또한 data 양을 늘리기 위해 animation data를 mirror시킨 버전까지 포함시켰다.
또한, 모든 frame에서 head z-axis direction을 추출하여 이를 바닥에 projected 시킨 뒤 이를 평균 낸 head direction을 global target facing direction으로 사용하였다. runtime에는 global z-axis를 global target facing direction으로 사용하였다.
Audio data의 경우 48kHz의 sampling rate로 record 되었는데 speech encoding을 위해 FFT Hanning-window of 50ms와 hop length of 12.5ms를 사용해 spectrogram으로 추출하였다. 이를 mel frequency scale로 투영하고 log amplitude(각각 80개의 채널을 가지는)와 total frame energy를 추출하여 final speech features를 생성한다. 그런 다음 다시 60 fps로 re-sampled 시킨다.
6. Training & Losses
<대략적인 Training 세팅값 >
- Network는 rectified Adam optimizer를 사용해 end-to-end로 학습
- learning rate는 1e-4
- decay factor는 0.995로 1K iterations마다 적용
- bach size는 32
- 120k iterations 후에 training을 stop시킴
- 한 batch에서 length of the sequence T는 256 frames(4.26 seconds)로 세팅
- teacher forcing 사용 X
- style example sequence는 같은 animation clip에서 sampled 됨. 이때 length M은 256 frames에서 256 frames로 random하게 설정되는데, 어떻게 설정되든 target sequence를 둘러싸고 있음
- 전체 batch의 10%에서 animation과 speech speed를 random하게 바꿈 (data augmentation strategy)
<Losses>(아 어렵당...........)
본 논문에서 제안하는 model은 conditional VAE로, objective가 evidence lower bound (ELBO) of the marginal log likelihood of gesture motion given a speech sequence를 최대화하는 것이다. 따라서 training loss를 negative ELBO로 formulate하였다.
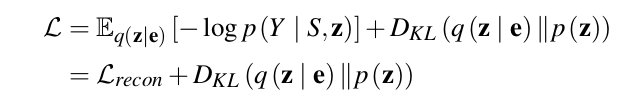
두번째 term은 Regularization term으로 style encoder에 의해 predicted된 posterior distribution q(z|e)와 prior distirbution p(z)의 Kullback-Leibler divergence이다.
첫번째 term은 reconstruction loss로 다음과 같이 나눠진다.
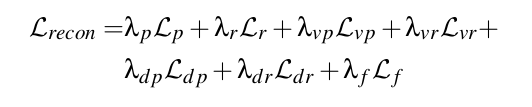
- L_p: mean absolute error(MAE) between predicted and target joint position
- L_r: MAE beween predicted and target joint rotations
- L_vp: MAE beween predicted and target joint velocities
- L_vr: MAE beween predicted and target joint rotational velocities
- L_dp: local space와 world space 상에서 translational velocities를 finite-difference를 통해 즉석에서 계산하여 MAE에 비례하게 penalize
- L_dr: local space와 world space 상에서 rotational velocities를 finite-difference를 통해 즉석에서 계산하여 MAE에 비례하게 penalize
(위의 term 모두 local space와 world space 상에서 모두 계산되었음)
(근데 나 솔직히 L_db랑 L_dr이랑 무슨 소린지 모르겠어...ㅠㅜ)
- L_f: MAE for the facing direction in the world space. character rotational drift를 막기 위해 사용