
728x90
728x90
Method 정리
1. Observation
- 3가지의 파트로 나뉜다.
- simulated character의 observation (312차원)
- sensor로부터 sparse하게 오는 observation (162차원)
- scale of the user (1차원)
1) simulated character observation (총 312차원)
캐릭터는 33 dof, link는 총 16개
- → joint의 angle (33차원)
- → joint의 angle velocities (33차원)
- → link의 Cartesian position (16*3 = 48차원, character local frame에 대해 표현된다.)
- → link의 orientations (16*6 = 96차원, rotation matrix의 앞 두 column, character local frame에 대해 표현된다.)
- → 두 발의 contact forces (2*3 = 6차원)
- → link의 linear velocity (16*3 = 48차원)
- → link의 angular velocity (16*3 = 48차원)
2) sensor로부터 sparse하게 오는 observation (162차원)
센서는 3가지 종류. headset, left controller, right controller
- → headset의 position (3차원, character local frame에 대해 표현된다.)
- → headset의 orientation (6차원, character local frame에 대해 표현된다. rotation matrix의 앞 두 column)
- → left controller의 position(3차원, character local frame)
- → left controller의 orientation(6차원, character local frame)
- → right controller의 position(3차원, character local frame)
- → right controller의 orientation(6차원, character local frame)
- → 총 27차원
- → 그런데 policy가 6 future user observation에 접근할 수 있기 때문에 총 27*6 = 162차원
<training 시에는>
- sensor data를 수집하고 그에 맞는 pose를 새롭게 만들어서 dataset을 만드는게 아니라
- motion dataset으로부터 sensor data를 계산해서 sensor data, ground-truth pose pair를 만들어낸다.
3) scale of the user (1차원)
- → user의 height in meters
- → 이걸 input으로 받아서 simulated character의 size를 똑같이 맞추는 작업을 처음에 진행해야한다.
<training 시에는>
- → motion data의 first pose (A-pose)를 사용해서 subject의 height를 추출하였다.
2. Reward
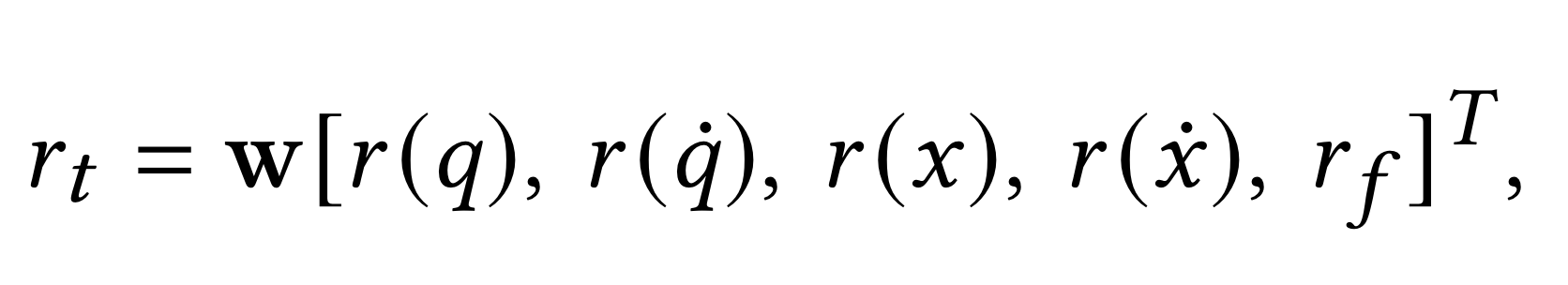
- r(q): simulated character와 ground-truth mocap pose의 joint angle 차이를 quantify한거
- r(q dot): simulated character와 ground-truth mocap pose의 joint angular velocity 차이를 quantify한거
- r(x): simulated character와 ground-truth mocap pose의 Cartesian position 차이를 quantify한거
- r(x dot): simulated character와 ground-truth mocap pose의 Cartesian velocities 차이를 quantify한거
💡 사용자의 하체를 관찰할 수 없는 상태에서 위의 term만 사용하면 자연스럽지 않은 모션이 나오게 된다. 이를 방지하기 위해서 r_f라는 term을 추가적으로 사용
- r_f = exp(k_f Σ_{i=L, R} max(0, f_{y,i, prev} - f_{y, i}))
- f_y는 vertical contact force, 너무 급격한 vertical contact force의 감소를 penalize하는 term이다.
3. Training
- policy는 PD target를 output으로 내놓는게 아니라 directly output torque를 내놓는다.
- policy와 simulation은 36 frames per second
- Lafan dataset 사용
728x90
728x90
'연구 > 논문 리뷰' 카테고리의 다른 글
| Motion Fields for Interactive Character Animation 정리(2) (0) | 2023.04.03 |
|---|---|
| Motion Fields for Interactive Character Animation 정리(1) (0) | 2023.04.03 |
| QuestSim: Human Motion Tracking from Sparse Sensors with Simulated Avatars 정리(1) (0) | 2023.01.11 |
| 논문분석: Real-time Controllable Motion Transition for Characters (0) | 2022.08.25 |
| 논문분석: Real-time Controllable Motion Transition for Characters(3) (0) | 2022.08.18 |