
Experiments and results
* 본 실험에서는 모션 퀄리티랑 모션 스타일의 다양성을 테스트하기 위해 Lafan1 dataset을 주로 사용하였으며
generalizability(일반화 가능성)를 테스트하기 위해 Human3.6M dateset을 사용하였다.
* 별 설명이 없더라도 모든 모델은 Lafan1 dataset으로 training 된 것이고, transition lengths는 5~30 frames이다.
* test window는 65 frames이고 두 dataset의 Subject 5로부터 sampled 하였다.
* 본 실험에서는
1) motion quality
2) transition quality
3) 본적 없는 시그널이 주어졌을 때 model generalizability 를 evaluation하는데 포커스를 맞추었고
qualitative visual evaluation(정성적인 시각 평가)과 quantitative metric을 모두 사용하였다.
* quantitative metric은 본적 있는 target frame과 transition duration이 주어졌을 때 reconstruction accuarcy 를 측정
-> 측정할 때 Normalized Power Spectrum Similarity (NPSS)를 joint angle space 상에서 사용하고
-> predicted results와 ground truth 사이의 average L2 distance of global position 도 사용한다.
=> NPSS랑 L2 distance 이 두 metric은 transition quality를 측정하기에 좋음
* 그리고 본 논문에서 bone-length loss term을 training 중에 사용하기는 했으나 이게 bone length를 유지시켜주지는 못함
30 frame transition motion에서 average bone length error = 0.64cm
* RTN과의 공정한 비교를 위해 우리 연구에서 joint position을 joint rotation으로 바꾸고 joint position을 FK로 얻게 만든 다음 RTN과 joint position accuracy 비교를 하였다.
* 추가적으로, motion quality를 측정하기 위해 foot skating metric을 사용하였다.
이 metric은 motion manifold가 velocity가 주어졌을 때 resonable한 pose를 만드는지 측정하는 metirc이다.
-> foot height h가 threshold H 안에 있을 때 ground에 대한 foot velocity를 평균낸다.
-> H는 실험적으로 2.5cm로 설정하였다.
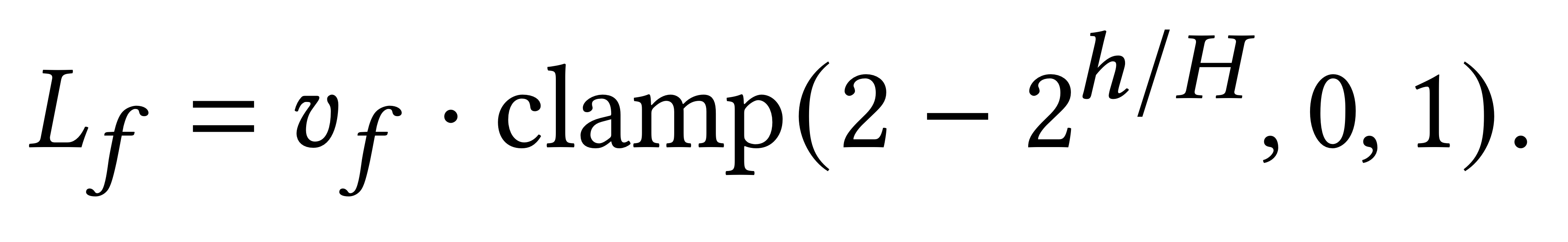
-> h가 H보다 크면 clamp에 의해 0의 값을 가지게 되고, h가 H보다 작으면 땅에 가까울수록 큰 값을 가지게 된다.
-> 즉, 땅에 발이 가깝고, 발의 속력이 크면 값이 커지는 metric
5.1 Ablation study
Pose representation
이전 연구에서는 joint positions, joint angles를 함께 사용하였다.
어떤 representation이 manifold model에 best인지 알아내기 위해 foot skating에 집중하여 ablation study를 진행
그 결과는 다음과 같다.

-> Foot skating metric은 낮을수록 좋은 metric. Position-based일 때 결과가 더 좋다.
-> [Wang et al. 2021]에서도 joint position representation이 foot skating을 완화시킬수 있다고 나온다 .
-> Note* 우리 모델이 position-based representation을 사용하기는 하지만 여전히 joint angles을 modeling한다. joint positions는 여기서 학습을 더 용이하게 하는 regualarization term으로 역할한다.
Motion manifold focus on the lower-body joints
우리는 natural motion modeling에서 lower-body와 hip에 focus를 맞추었다.
-> 그런데 이건 최근 딥러닝 연구와 다른 연구 동향이다. 왜나하면 locomotion에서 lower-body motion은 상대적으로 simple하기 때문
-> 하지만 foot skating 때문에 lower-body는 motion quality에서 굉장히 중요한 역할을 한다.
-> 따라서 중요한 중요한 부분에 대해서는 motion manifold에서 우선적으로 학습하게 하고 upper-body와 lower-body의 상관관계는 transition sampler에게 학습을 맡겼다.
whole body를 directly하게 학습하는 방법도 있는데 이렇게 되면 상대적으로 unconstrained한 upper-body의 motion이 learning에 ambiguity를 가져오게 된다. 이걸 증명하기 위해 upper-body를 CVAE에 도입하고 transition sampler에서 upper joint rotation difference term을 제거하여 학습을 진행하였는데 이 네트워크를 Full-body network라고 부를 것이다. 비교 결과는 다음과 같다.
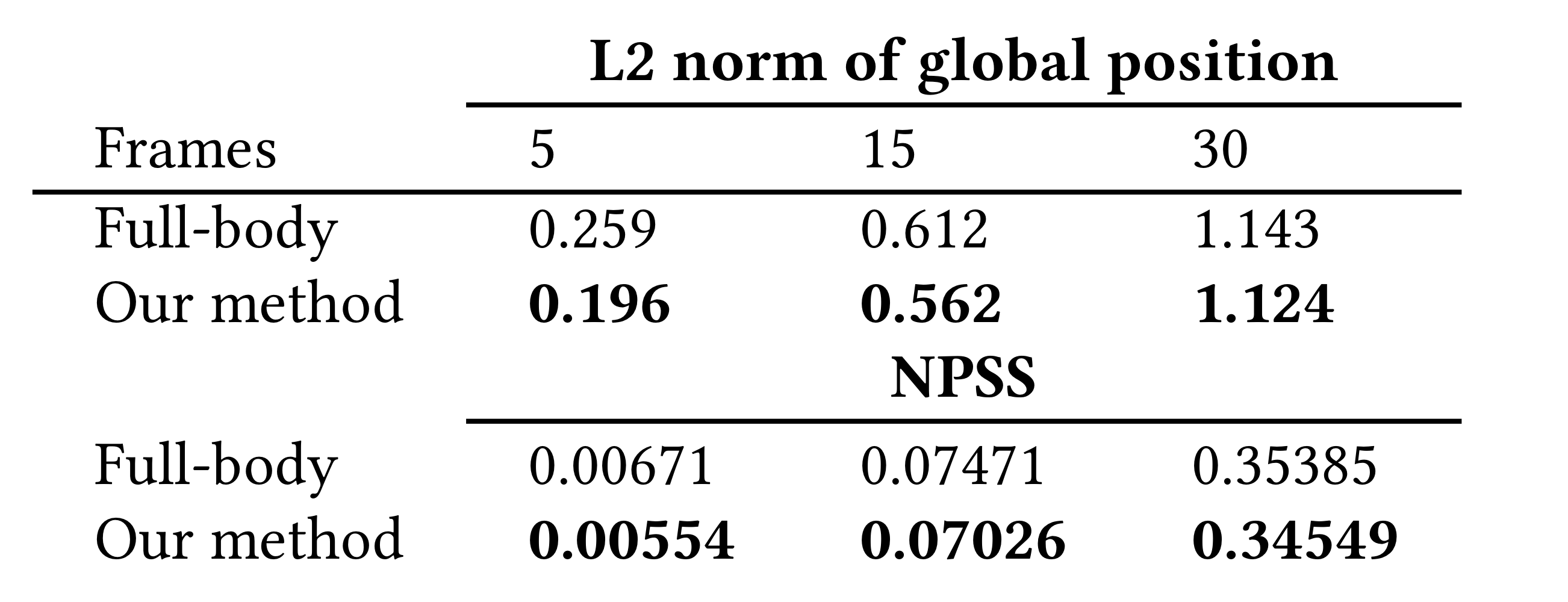
-> L2 norm과 NPSS모두 작은 값이 작을수록 좋은 emtric
-> Full-body network를 사용할 때 에러가 더 크다. 이건 prediction이 "averaged" motion에 가까워지기 때문
우리 방법대로 lower body와 upper body를 separating하면 learning을 향상시킬 수 있다.
5.2 Evaluation and Comparision
motion quality
motion quality에서 foot sliding은 굉장히 중요하다.
이전 연구들에서 foot sliding 문제를 겪는 이유는 -> "averaged" motion과 drifiting issue 때문
이 문제를 해결하는 가장 일반적인 방법은 1) post processing stage를 만드는거. 더 최근 연구에서는 2) dense control signal이 가능할 때는 contact patterns를 만들거나 3) generated motion의 distribution을 data랑 비슷하게 맞추는 방법들을 사용하였다.
-> 1) post processing 같은 연구 우리 application에는 적합하지 않고
-> 2) predicting contact pattern도 임의의 target frame에 대해 바로 만들기가 어려워서 우리의 연구에 적합하지 X
-> 3) distribution을 constaining하는 것은 효과적인것처럼 보이지만 foot skating을 완화시키기 쉽지 않음
=> 이를 증명하기위해 RTN, RTN에 foot skating loss를 더한거랑 비교를 하였다.
=> naive baseline으로 linear interpolation한 것과도 비교를 하였다.
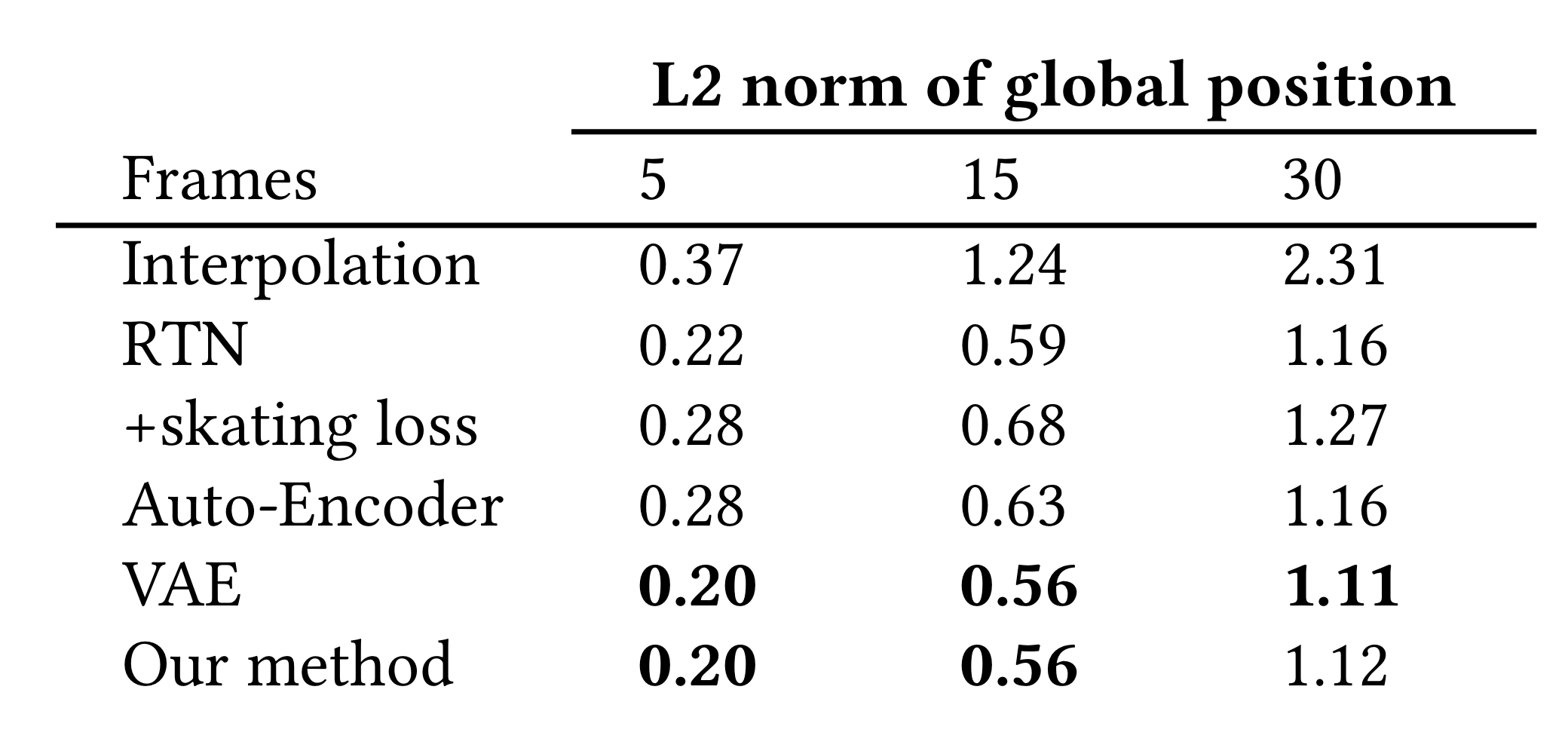
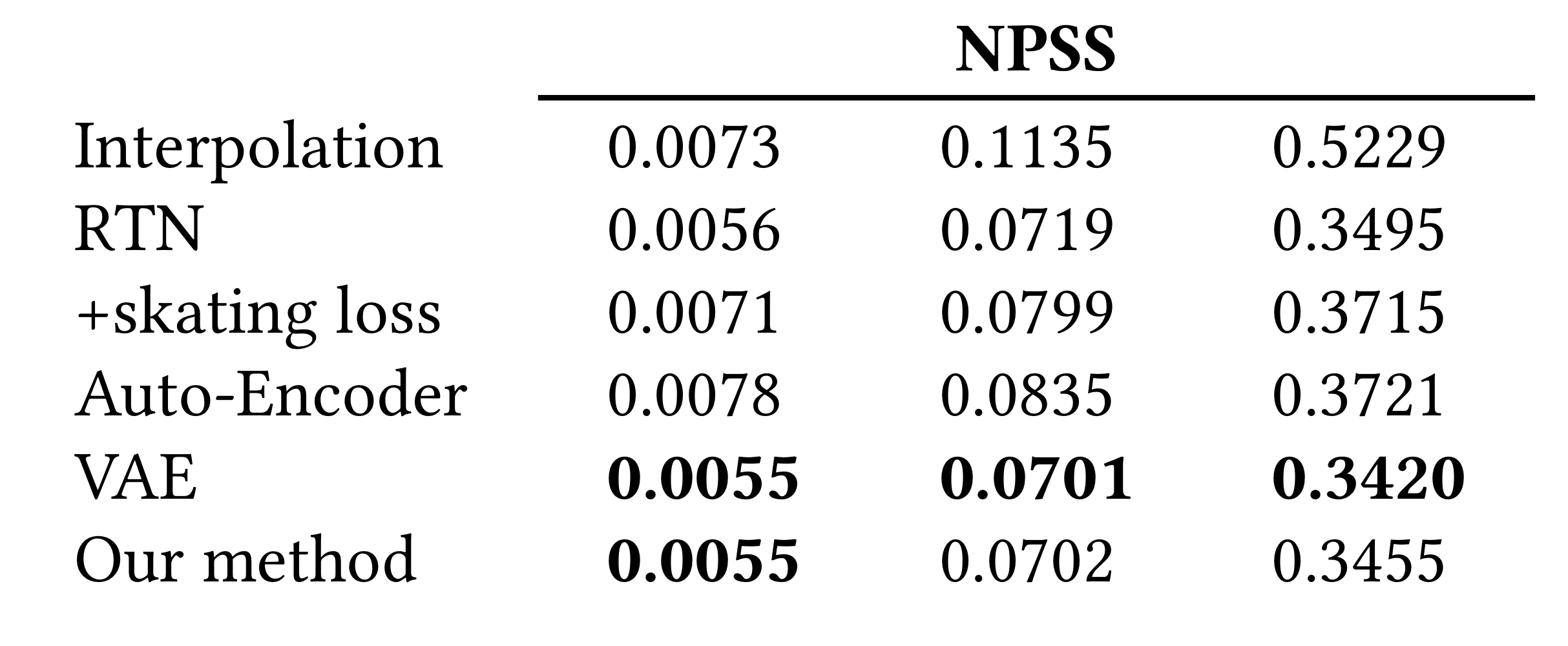
L2 norm과 NPSS는 transition quality를 측정하는 metric, Foot skate는 motion quality를 측정하는 metric
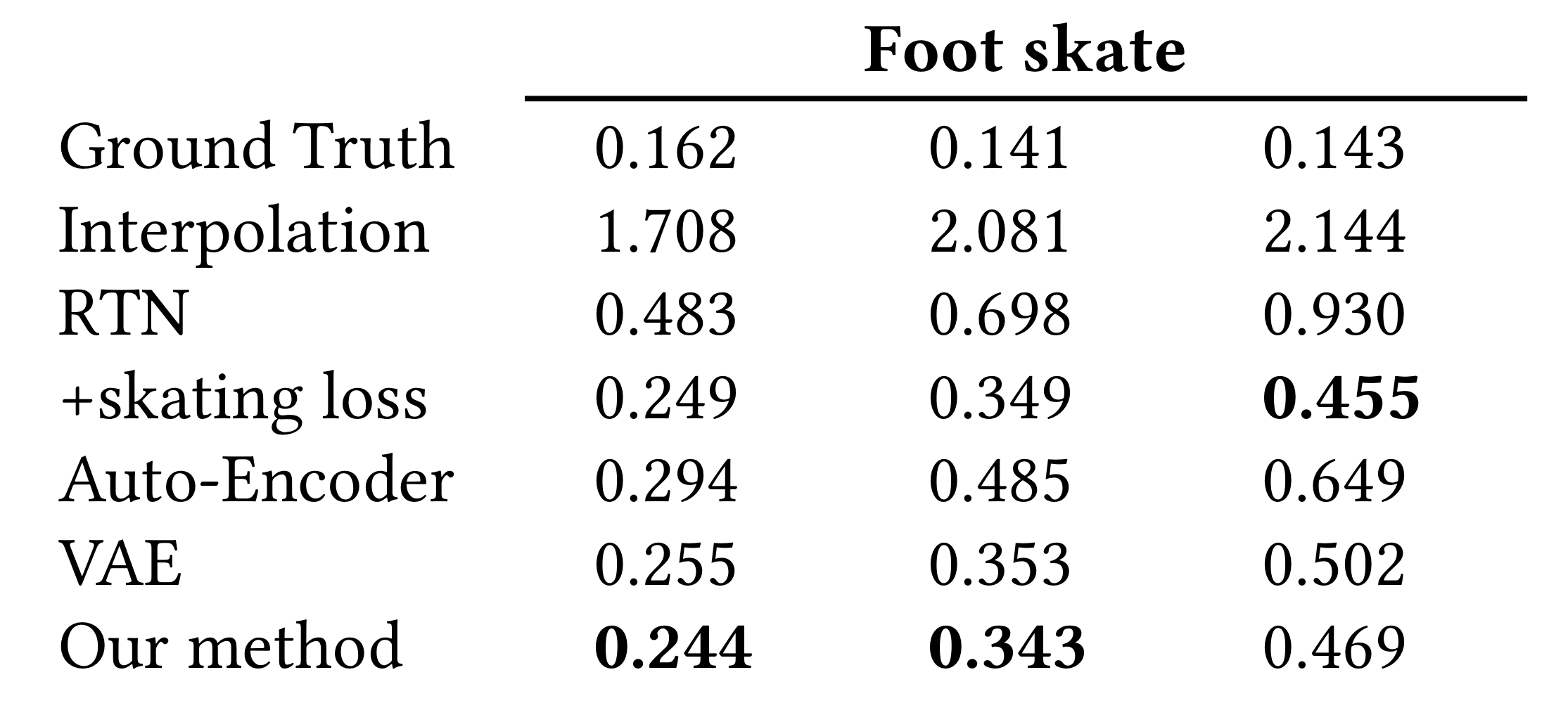
<RTN+foot skating vs Our Method>
-> RTN에 foot skating을 추가하니까 추가하니까 foot skating을 줄여줌. 하지만 이건 reconstruction accuracy를 나쁘게 만든다.
-> foot skating loss를 추가하면 contact step을 predict해서 loss를 적용하게 되는데, 만약 predicted contact step이 ground truth와 달라지면 이 loss가 incorrect backward를 유발하고 이게 pose를 unnatrual하게 만든다.
-> 비디오를 보면 RTN에 foot skating loss를 추가했을 때 start frame과 end frame 근처에서 transition이 unsmoothed 해짐
우리의 method는 foot skating loss를 적용하니까, 즉 foot contact step을 예측하지만 pose를 unnatrually하게 만들지 않는다. 오히려 hip velocity를 조정하는데 도움을 준다. 이 이유는 pose가 manifold에서 sampled되기 때문!
<AE, VAE vs Our method>
motion dynamics latent distribution을 controlling하는 것의 중요성을 보여주기 위해 1) CVAE를 autoencoder로 대체해서 실험하였다. 이때 plain autoencoder를 사용했기 때문에 z의 distribution은 조정되지 않았다. 따라서 KL-divergence loss도 사용하지 않았다. 또한 hip velocity를 condition으로 사용하는 것의 중요성을 보여주기 위해 2) CVAE를 VAE로 대체하여 실험하였다. 즉, latent distribution은 unconditional 하게 만들어주었다. (참고로 VAE랑 AutoEncoder는 motion manifolds를 학습할 때 많이 사용된다.)
위의 표를 보면 hip velocity를 conditioned decoding하여 z를 명시적으로 조절해주었을 때, 우리의 방법은 VAE와 reconstruction accuracy가 비슷하고 Auto-encoder보다는 훨씬 뛰어난 성능을 낸다.
하지만 VAE보다 우리 방법이 foot skating 면에서는 더 낫다. 또한 VAE와 비교했을 때 우리 방법이 30번째 frame부터 foot skating을 큰폭으로 향상시켜서 motion quality 면에서 더 좋은 모습을 보여준다.
우리 방법과 RTN을 Human3.6M dataset을 사용해서도 비교하였다.
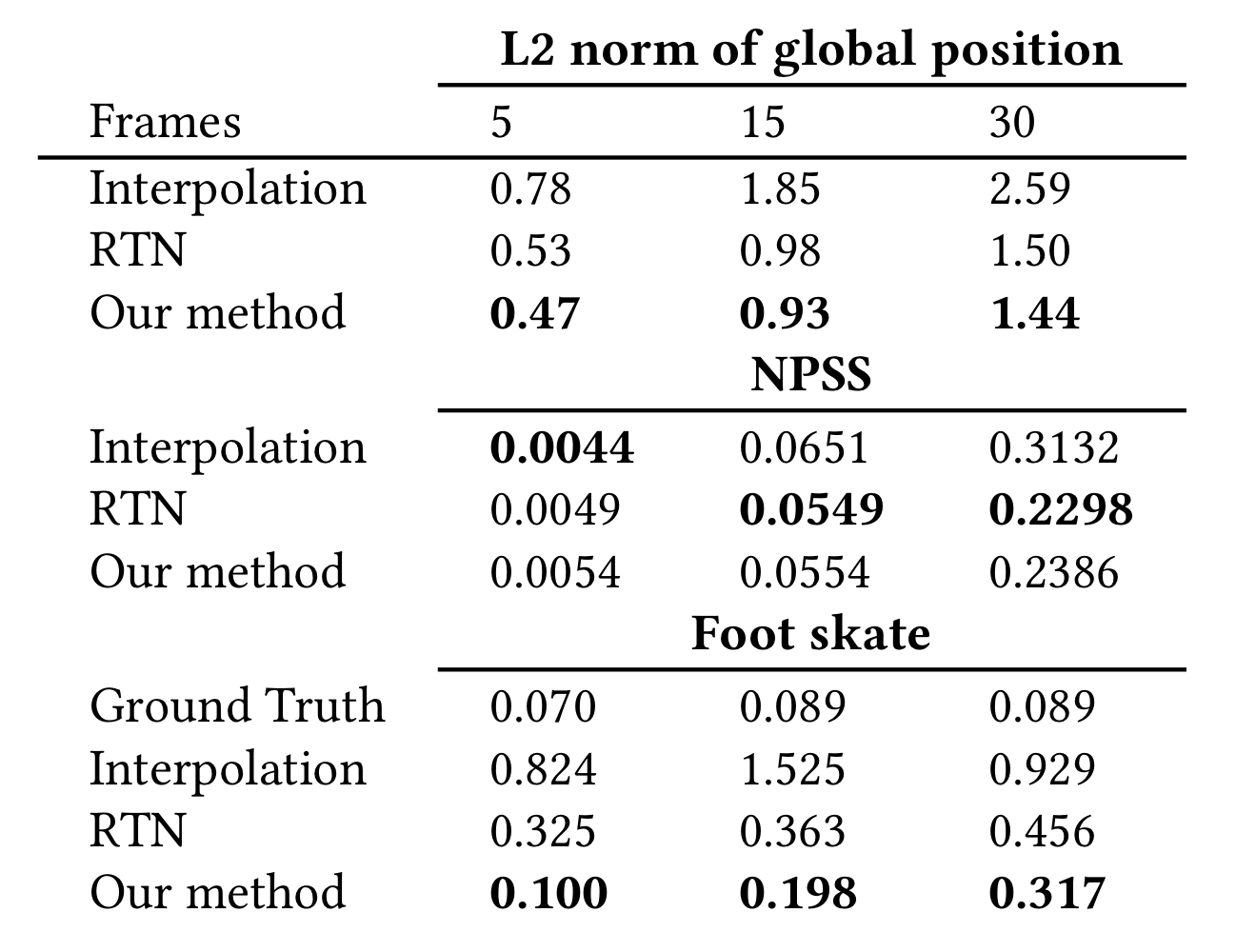
NPSS에서 RTN이 최대 7.6% 우리 방법보다 낫긴 하지만 L2 norm은 우리 방법이 10.3% 낫고, foot skate는 우리 방법이 69.2% 낫다.
Human3.6M이랑 Lafan1의 가장 큰 차이는 subject간의 skeleton variation인데 Human3.6M에서 variation이 더 크다.
이게 NPSS 측면에서 결과가 나쁜지, 그리고 frame 5개일 때 Interpolation이 두 methods보다 나은지에 대한 이유라고 생각된다.
어쨌거나, 두 방법 모두 different skeleton을 generalize하는 것이 목표는 아니므로 이건 future work로 남겨두었다.
또한 transformer를 기반으로 하는 state-of-the-art offline motion completion method 와도 비교를 진행해보았다.

-> 둘은 유사한 결과를 만들어낸다.
Generalization
target frame과 transition duration이 control signals로 사용되기 때문에 본적 없는 user control, exterm user control 하에서 model을 평가하는 것이 중요하다. 우리는 다양한 측면에서 method를 증명했다.
-> 1) motion style, 2) aimed transition duration, 3) distance between the start and end frame
Different motion styles
Lafan1을 motion style에 따라서 여러개의 subsets으로 나누었다.
-> walking이랑 running sequence들은 "walk" set으로 분류했고
-> dance sequence들은 "dance" set으로 분류했고
-> jump sequence들은 "jump" set으로 분류했고
-> obstacles를 accross하는 sequence들은 "obstacles" set으로 뷴류했다.
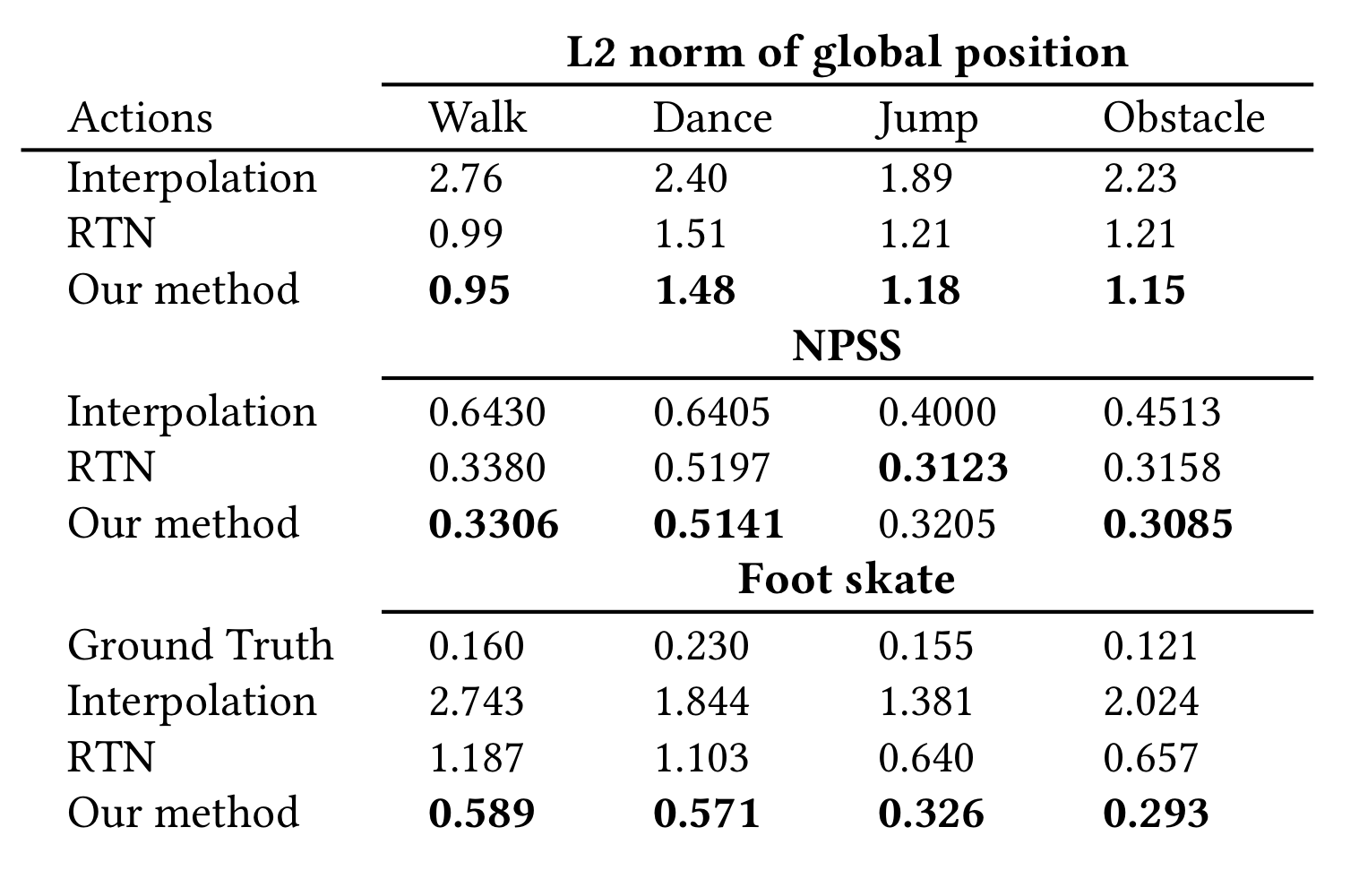
-> ground truth도 foot skating을 가지고 있어서 이걸 baseline으로 사용하였다.
-> 실험 결과 우리 방법이 reconstruction(L2, NPSS)를 더 잘하면서도 foot skate 측면에서도 더 결과가 좋았다.
Different transition duration
aimed transition time으로 다양한 duration을 다룰 수 있는지 테스트하기 위해 각 sample에서 1 second(30 frames)를 제거하고 network에게 2배(15 frame), 4배(8 frame) 0.5배(60 프레임) 의 speed를 가지는 sequence를 만들도록 하였다.
그리고 극단적인 case로 0.01배(100 frames)의 speed를 가지는 sequence도 만들도록 하였다.
결과는 다음과 같다.
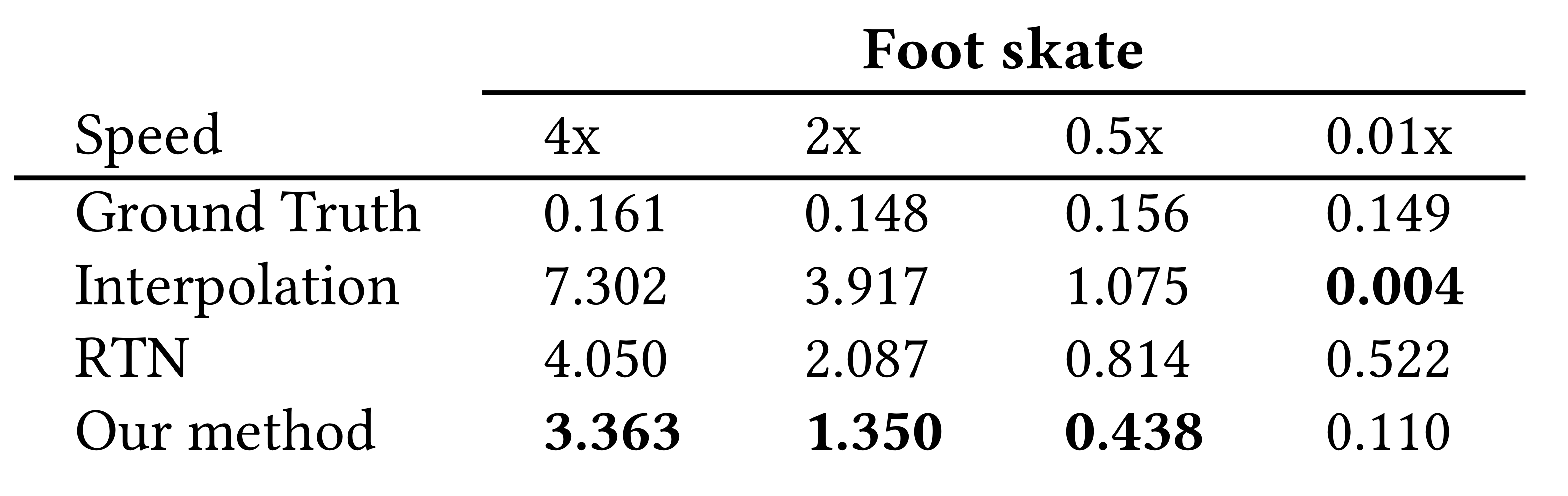
0.01배로 scale했을 때는 interoplation이 가장 결과가 좋았다. drifiting이 100으로 나눠어지기 때문에..하지만 interpolation의 결과에는 valid한 pose change가 없다.
이론적으로 motion을 slowing down 하는게 더 쉽다. foot conact이 유지될 수 있기 때문에..
우리의 방법은 RTN보다 발 접촉을 더 잘 유지한다.
그리고 motion을 speeding up 하는 것은 target에 짧은 시간동안 도달하는게 불가능할 수도 있기 때문에 더 어렵다. 이때문에 위의 표를 보면 4x, 2x의 결과가 일반적으로 더 나쁘다. 하지만 우리 방법이 가장 좋은 결과를 만들어낸다.
그리고 만약 start frame과 end frame이 walking cycle 내에서 phase가 같으면, RTN은 pose를 안바꾸고 그대로 drift하는 경향을 보였고, 우리 방법은 fast footstep을 만드는 결과를 보였다.
Different target locations
target location을 바꾸면서 2가지 실험을 진행하였다.
1) target frame을 direction을 유지하면서 멀리 보내버리는 실험(Forwarding)
2) target frame을 direction을 반대로 해서 start-target 거리가 2배가 되도록 만드는 실험(Backwarding)
<Forwarding>
Our method: visual 결점 없이 step을 크게 하거나 많이 밟아서 gap을 채움
RTN: ground truth와 같은 step을 pace를 가지고 gap을 drifting으로 채움
<Backwarding>
: 이건 좀 극단적인 testing case라 두 방법 모두에게 challenge임
: start frame이랑 target frame의 orientation이 같은데 두번 회전할 시간은 부족하기 때문에 두 방법모두 backwrad로 걸음
-> RTN은 항상 visual 결점이 있는데 우리 방법은 그렇진 않음
-> data에 backwards로 움직이는 clip이 부족한데, 우리 방법에서는 motion manifold가 backward로 걷는 motion을 capture했기 때문에 natrual한 action을 성공적으로 학습한 것으로 보임.

위의 그림은 RTN, VAE, our method를 visual comparision한 것이다.
RTN: target frame이 너무 멀어서 goal을 향해 drift함
VAE: hip velocity가 condition으로 주어지지 않으니, movement를 합성하지 못하고, pose는 unnatrual함
Our method: 이런 극단적인 케이스에서도 most natrual motion을 만들어냄
Limitation
1) 여느 data-driven method와 마찬가지로 training data와 너무 다른 motion은 만들어내지 못함
-> target frame이 starting frame보다 뒤에 가있으면 motion 만드는게 힘들다.
빨리 turning하는 데이터나 backwrad로 걷는 data가 부족하기 때문에.
-> 그리고 target frame이 data와 너무 다르면 target frame에 100% achieve된다고 보장 못함
-> 하지만 이건 diverse data가 도입되면 해결될 문제
2) motion diversity의 부족
-> CVAE 기반 네트워크인 만큼, 동일한 control signal이 주어졌을 때 다른 motion을 생성할 수 있다.
-> 하지만 생성되는 motion의 차이는 작다. (특히 lower body 쪽!!)
-> 이건 motion quality를 높이기 위해 그런것도 있음. unseen control에 대해서도 high-quality의 motion을 만들기 위해서는 ground에 대한 contact position of each step을 많이 바꾸지 못할거임.
Future Work
1) duration을 자동으로 계산하도록 할거임.
-> 우리 모델이 다양한 duration에 견고하므로, 가능한 timing requirement의 distribution을 자동으로 모델링해서 가장 합리적인 duration을 찾아낼거임.
2) 더 많은 factor들을 고려할거임: motion styles, interactions with environment, various skeletal topologies