
Transition Sampling
Real-time Controllable Motion Transition for Characters(1)에서 배운 CVAE를 통해서 motion manifold를 학습할 수 있긴 하지만 uncontrolled generation만 할 수 있다. CVAE에 해당되는 식을 보면,
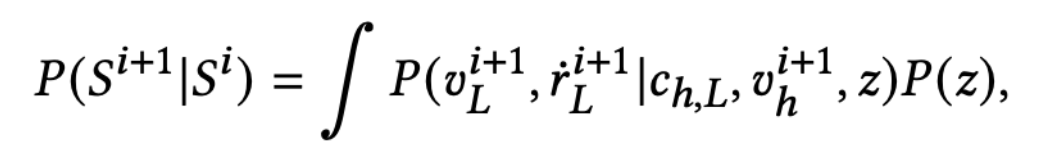
distribution이 S^t(target frame)와 z_dt(transition duration)에 conditioned 되어있지 않다.
따라서 S^t, z_dt에 conditioned된 P(M)을 Explicitly하게 학습하기 위해선 모든 possible duration동안 reverse Markov chain을 학습해야하는데, 이건 매우 까다로운 과정이다. 그래서 이 모델에서 택한건 neural network를 통해서 implictly하게 학습하는 방법이다.
S^i는 주어진 상황에서 S^(i+1)를 생성하기 위해선
S^t(target frame)과 z_dt(trainsition duration)을 constraints로 사용하면서 z와 v_h^(i+1)를 샘플링해야한다.
따라서 neural network는 learned manifold로부터 frame을 sampling하는 샘플러 역할을 해야한다.
sampler의 architecture는 아래와 같다.

Encoder
3가지의 Encoder가 있는데
* state encoder: current state of pose를 encoding함. sampler가 state encoder를 통해 current state of pose를 알수있음
frame을 Encoder로 넘길 때 state S를 dimension을 줄이기 위해 hip velocity, lower joint's velocity, upper joint's rotation으로 표현한다. (v_h, v_L , r_U)
* target encoder: target frame을 encoding함
* offset encoder: offset between the current and the target frame를 encoding함
offset을 계산할 때는 lower joint's position p_L을 사용한다. upper joints와 lower joints에 대한 attention을 balance 맞춰주기 위해 offset encoder를 통과시키기 전에 p_L을 z-score normalization 시켜준다.
세가지의 encoder는 모두 two-layer feed forward networks with 512 units이며 first hidden layer 와 second layer에 256 units이 있다. 각 layer의 activation function은 PLU activation이다.
z_target
time-varying noise z_target를 사용한다.
z_target은 (zero-centered Gaussian distribution with variance equal to 0.5)에서 샘플링 된 값이다. 여기서 너비 lambda는 target frame에 frame이 가까워질수록 감소하게 된다. 따라서 z_target을 사용하게 되면 target frame이 가까워질때만 sampler의 attention이 target에 집중된다는 효과가 있다. 또한 새로운 conditioning information에 robustness를 향상시키는 효과가 있다.
z_target이 decrease 되는 식은 다음과 같다
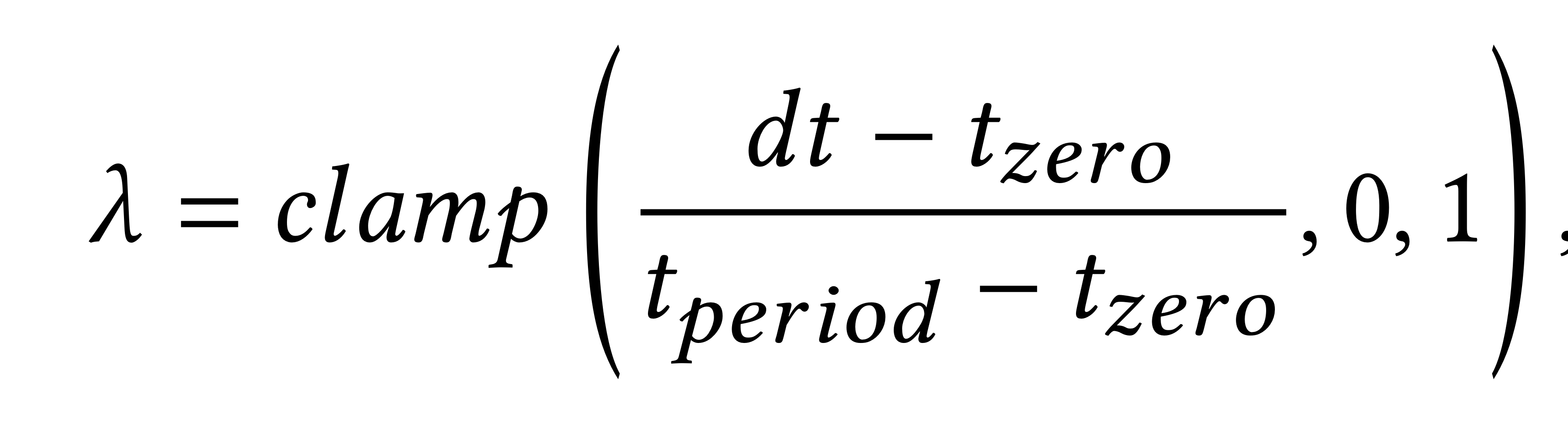
dt: current time의 frame과 target frame의 difference를 의미한다. 이 값이 커질수록 lambda 값이 커지므로 sampler의 attention이 target으로부터 멀어질 가능성이 높아지게 된다.
t_zero: frame duration without nosie
t_period: period of linear decrease of the noise(? 뭘 의미하는지 모르겠네..)
이 논문에서는 t_zero = 5, t_period = 30을 사용하였다.
z_dt
constraint z_dt(transition duration 의미)는 time embedding z_dt를 통해 표현되고 모든 encoder의 latent vector에 더해진다. time embedding z_dt는 positional encoding과 유사하다.

LSTM & Parse decoder
LSTM은 next state를 예측하기 위해 Encoder들을 통과한 모든 latent vectors를 받아들인다.
Parse decoder는 LSTM에서 만들어낸 next state를 취해서 sample (z, v_h^(i+1))과 upper joints의 r dot_U^(i+1)를 만들어낸다. Parse decoder에서 genearte하는 (z, v_h^(i+1))의 경우 CVAE decoder의 input으로 필요로 하는 값이고
r dot_U^(i+1)는 CVAE decoder에서 만들어내는 정보만으로 next frame을 만들어내기 부족하기 때문에 추가적으로 만들어낸다.
parse decoder는 3개의 layer로 이루어져있는데 첫번째 layer에는 512개의 unit이 있고 2번째 layer에는 256개의 unit이 있다. 두번째 layer의 activation function은 ELU activation function이다.
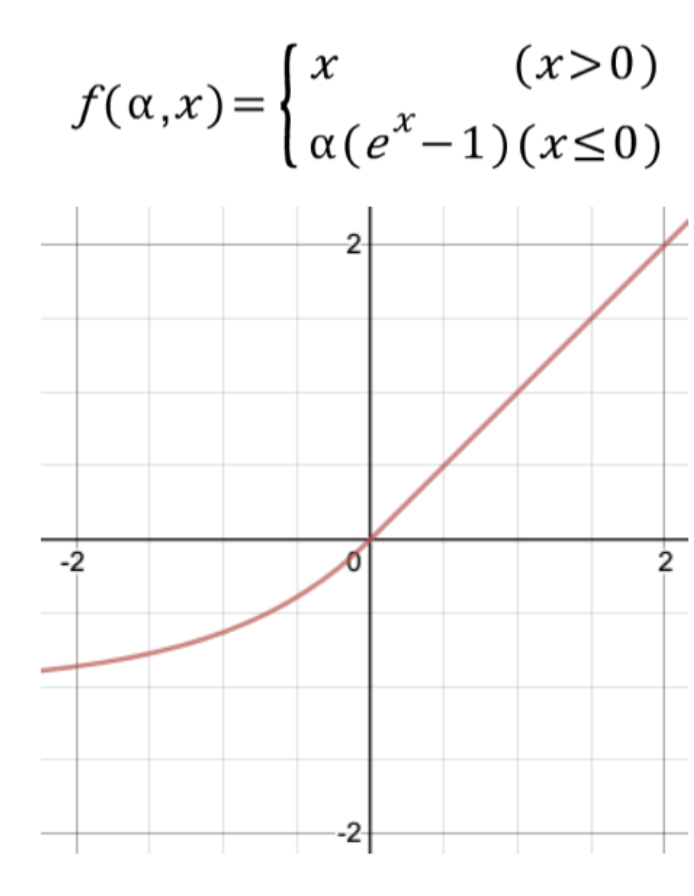
next frame을 sample하기 위한 CVAE의 key input인 z를 계산하기 위해 우리는 tanh activation function을 적용하고 정규분포에 가깝게 하기 위해 output을 4.5만큼 scale 시킨다.
Losses: Sampler를 어떻게 훈련시킬까?
transition sampler를 훈련시키기 위해 CVAE의 encoder를 제거하고 CVAE의 decoder를 고정시킨뒤 transition sampler로 고정된 CVAE decoder를 연결시킨다.
sampler를 train 시키기 위한 loss function은 다음과 같다.
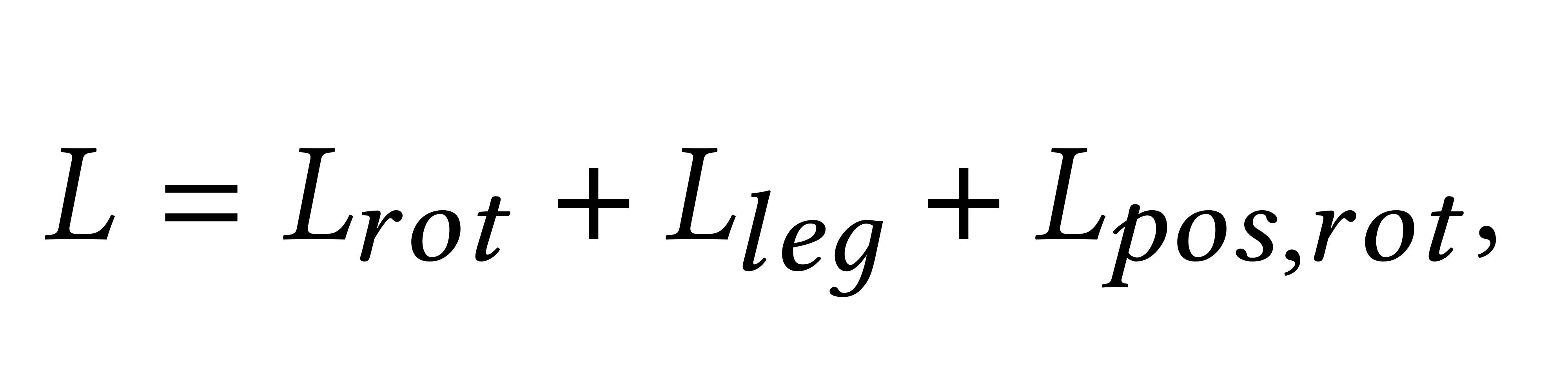
* L_rot: L1 norm rotation loss for all joints (모든 joint의 rotation loss를 L1 norm한거)
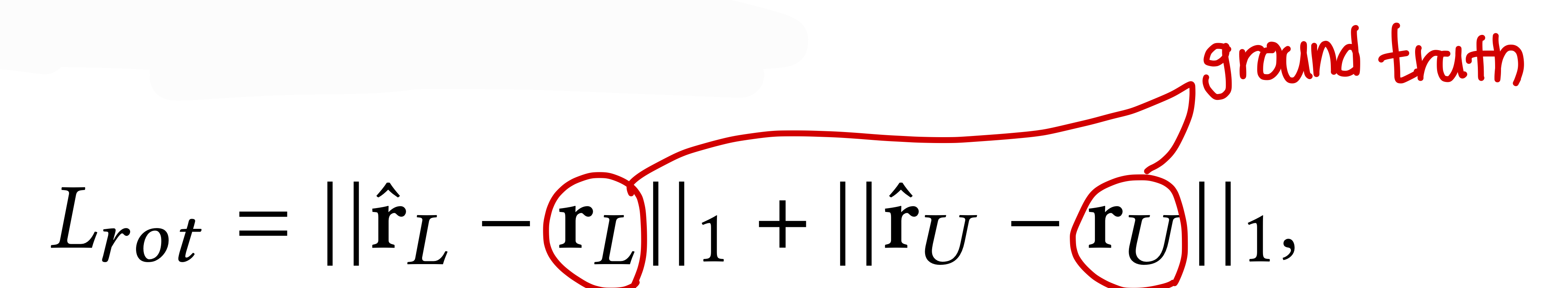
* L_leg: L1 norm position loss for lower-body joints
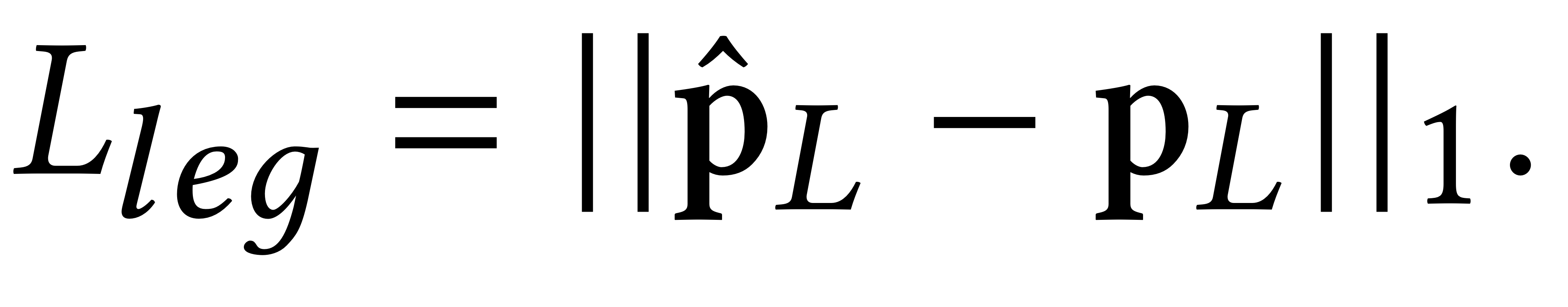
* L_pos, rot: 모든 joint에 대하여, Forward Kinematics(FK)를 통해 predicted rotation으로부터 구한 position과 ground truth
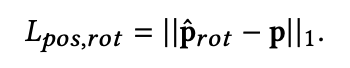
position과의 차이를 L1 norm한 loss이다. 이렇게 하면 implicitly하게 bone hierarchy의 rotation을 조정하여 더 나은 결과를 도출하게 하는데 도움이 된다.
더불어, CVAE를 training할 때 사용했던 bone length loss와 foot skating loss도 sampler를 training하는데 도움이 된다.