
Implemenation
Data formatting
본 연구에서는 LaFAN1 dataset과 Human3.6M dataset을 사용하였다.
Human3.6 dataset을 사용할 때는 wrist 와 thumb joints를 제거하여 21 joints만 남겨두었고
Lafan1 dataset은 그냥 사용하였다. (Lafan1 dataset의 joint 수는 22개)
그리고 joint마다 다른 representation을 사용하였다.
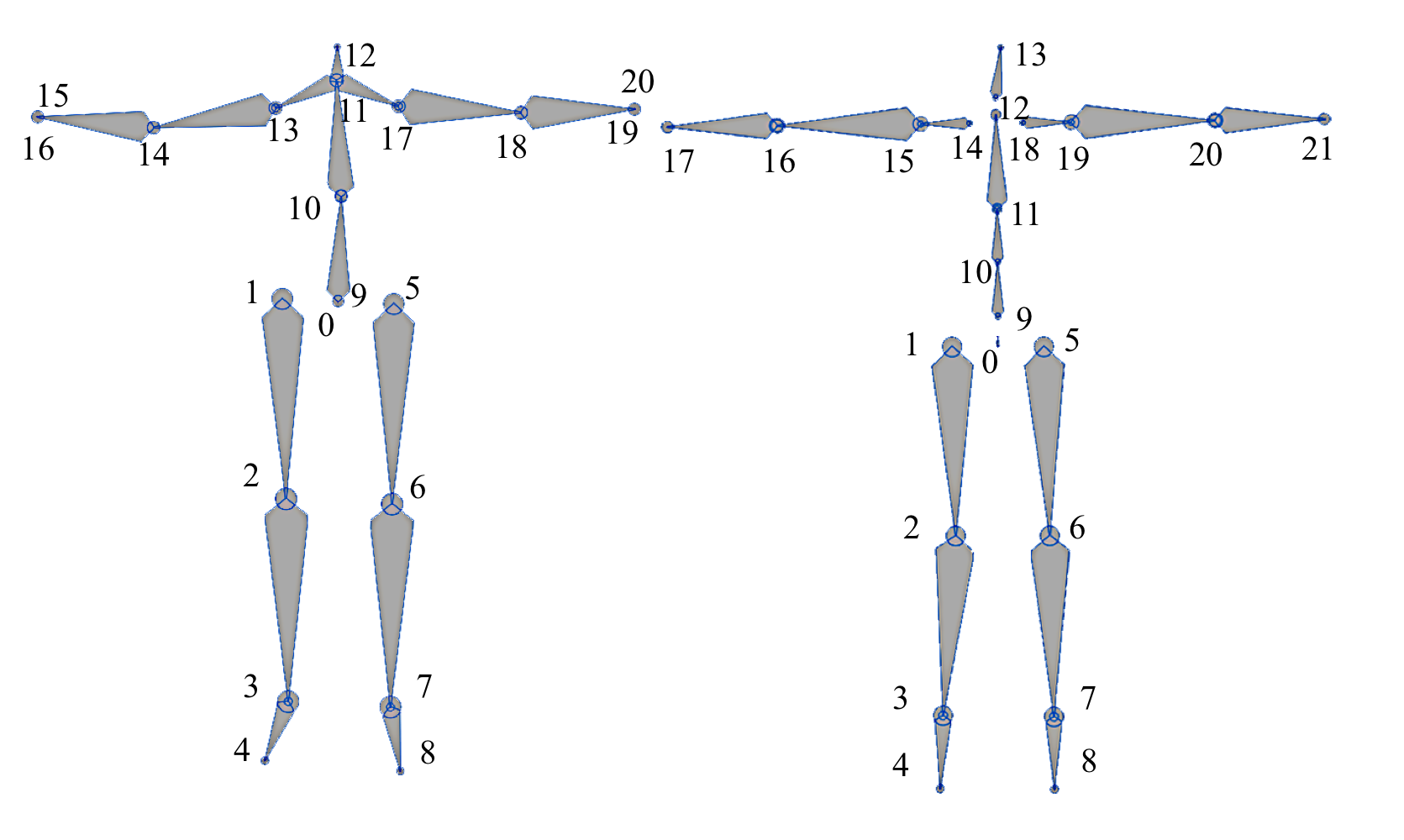
아래의 8개 joint(Lower body joint)에 대해서는 position-based representation을 사용하였고
위의 joint(Upper joints)에 대해서는 rotation-based representation을 사용하였다.
모든 lower joint는 2개 미만의 joint와 연결되어 자신의 orientation을 결정하고 있다.
Zhang et al[2018]에서는 6개의 숫자로 이루어진 2-axis rotation matrix를 사용하여 joint rotation을 표현하는 방법을 제안했었다.
-> 여기서도 joint rotation을 2-axis rotation matrix로 나타낼거임
joint position j는 joint velocity를 의미하는 3D vector와 up-direction을 의미하는 3D vector로 표현되었었다.
--> 우리는 여기서 3D up vector 정보는 2-axis rotation matrix에 포함되어 있으므로 생략가능하다.
따라서 lower joints X^i_L은
* 8개의 joint's rotation(8*6차원: lower joint가 8개이고, 2-axis rotation matrix가 6개의 숫자로 이루어져있으니까)
* 6개의 joint's position(6*3차원: 원래 position은 joint velocity와 up-direction으로 나타나는데 up-direction은 joint's rotation 정보에 포함되어 있으니까 joint velocity만 나타내면 됨 따라서 3차원으로 표현가능)
* 6개의 joint velocity(6*3차원)
-> 1번과 5번의 joint velocity는 생략가능하다. 0번 Joint(hip)의 rotation으로 인해 결정되기 때문에
두 dataset은 모두 multiple subjects를 가지고 있는데 우리는 test set에 포함된 subjects와 training set에 포함된 subjects를 다르게 했다. 그리고 두 dataset에 대해서 training set을 50-frames window로 split하였고, 연속적인 두 consecutive window가 25개의 overlapped frame을 가지도록 하였다.
training을 할 때 current step의 Input은 last step의 output으로부터 온다. 따라서 생성되는 sequence가 증가함에 따라 error가 accumulate된다. 이 효과는 network의 robustness를 향상시키는데 도움이 된다.
Training of Motion Manifold
training set을 50-frame window로 split하기는 했지만, 50 frame sequence는 motion manifold를 효율적으로 학습시키기엔 너무 긴 길이임. 그래서 50 frame sequence를 25 frame 씩 2개로 나눠 training 시키게 된다.
bone length loss는 joint의 velocity를 0으로 만들고 이상한 motion sequence를 만들게 함
이 문제를 해결하기 위해, 우리는 motion manifold 아키텍쳐를 2번 학습시키게 된다.
1) 처음에는 reconstruction loss와 KL-divergence loss만 가지고 학습을 하고
2) 다음으로 foot skating loss와 bone length loss를 더해서 학습시킨다.
그리고 posterior collapse(후방붕괴)를 피하기 위해 latent variable z와 future hip velocity v_h^(i+1)를 expert network의 모든 layer에 다 전달한다.
posterior collapse (후방붕괴): prior를 그대로 "mimic"하며, model은 latent variable을 무시한 상태에서 학습이 진행되는것을 의미합니다.
출처: https://wain-together.tistory.com/8
CVAE의 encoder는 2개의 hidden layers와 256개의 Unit을 가지고 activation function으로 ELU를 사용한다.
gating network는 2개의 hidden-forward layers로 이루어져있고 activation function으로 ELU를 사용한다.
gating network의 output layer에는 Softmax activation을 사용한다.
각 expert network는 hidden layer에 256개의 unit이 있고 activation으로 ELU를 쓰는 3-layer-feed-forwrad netowrk이다.
실험에서 6개의 expert networks를 사용할 때 가장 결과가 좋았고 6개보다 더 적은 수의 networks를 사용할 때는 정확도가 떨어졌다. 그래서 실험적으로 6개의 expert networks를 사용하게 되었다.
scheduled sampling strategy는 처음부터 사용하게 된다.
scheduled sampling strategy: y_t를 예측할 때 network를 통해 만들어진 y hat_(t-1)를 사용할지 실제 데이터로부터 만들어진 y_(t-1)를 사용할지 랜덤하게 선택하는 전략
출처: https://ai-information.blogspot.com/2019/03/scheduled-sampling.html
network는 last timestep에서 만들어진 predicted pose를 확률 p 만큼 input으로 받아들이고, 나머지 경우에는 dataset으로부터 온 ground truth를 input으로 받아들인다. 확률 p는 처음 k epoch동안은 0에서 시작해서 다음 k epoch동안 1로 linearly하게 증가한다.
Lafan1에서는 k=5, Human3.6M에서는 k=20으로 세팅하였다.
parameter를 조정하기 위해 AMSgrad optimizer(beta_1 = 0.5, beta_2 = 0.9)를 사용하였다.
motion manifold를 2차례에 걸쳐서 학습시킨다고 했는데,
first training time에는 learning rate를 1e-4로 세팅한 다음에 1e-5로 linear하게 decrease시킨다.
Second training time에는 0에서 시작한다음에 1e-4로 ten epoch동안 증가시킨다. 따라서 더해지는 loss term(foot skating loss, bone-length loss)가 parameter 조정에 아주 큰 영향을 미치진 않는다.
Training of Transition Sampler
CVAE를 training한 후, encoder를 제거하고 decoder를 고정시킨 뒤, transition sampler와 연결시켜 sampler를 training 시킨다.
Sampler를 구성하는 모든 encoder는 feed-forward network로 512개의 unit을 가지는 hidden layer로 구성되어있고 output layer는 256개의 unit을 가진다. 모든 layer는 activation function으로 PLU를 사용한다.
LSTM은 hidden layer에 1024개의 unit을 가지고 있고, pares decoder는 2개의 hidden feed-forward layer로 구성되어 있는데 첫번째 layer는 512개의 unit을 가지고 2번째 layer는 256개의 unit을 가진다. 두 layer 모두 ELU를 activation function으로 사용한다.
training 중에, 각 learning step마다 window로부터 5~30개의 length를 가지도록 sampling하여 network를 학습시킨다. 따라서 network는 다양한 길이의 transition length와 target frame을 학습할 수 있다.
AMSgrad optimizer는 transition architecture를 training할 때도 사용된다. learning rate는 1e-3이고
L_rot, L_leg의 weight는 1, L_pos, rot, L_bone, L_foot는 0.5이다.
본 연구에서는 transition architecture를 300000 iterations 동안 학습시켰으며 학습시키는데 거의 하루가 걸렸다고 한다.