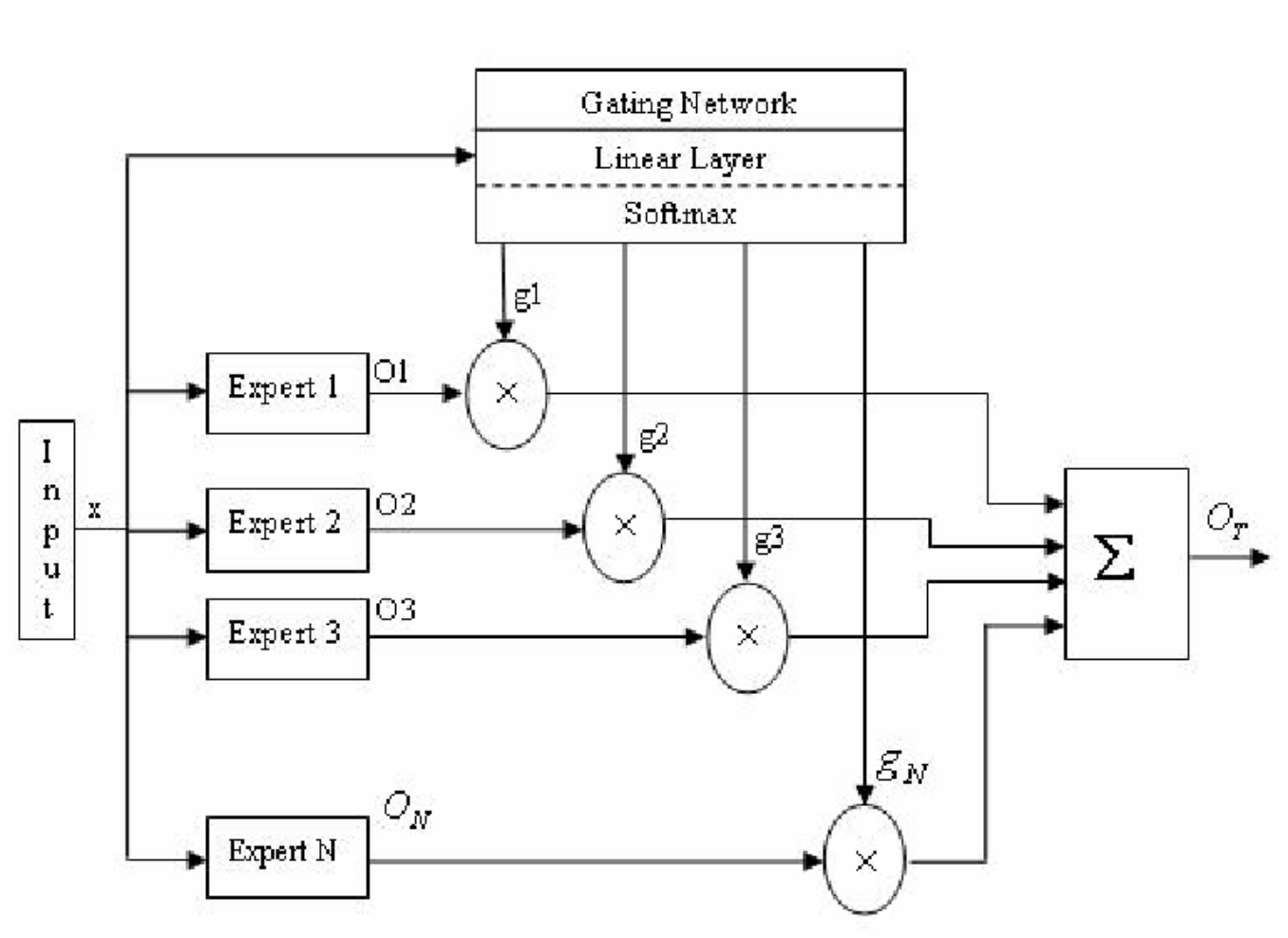
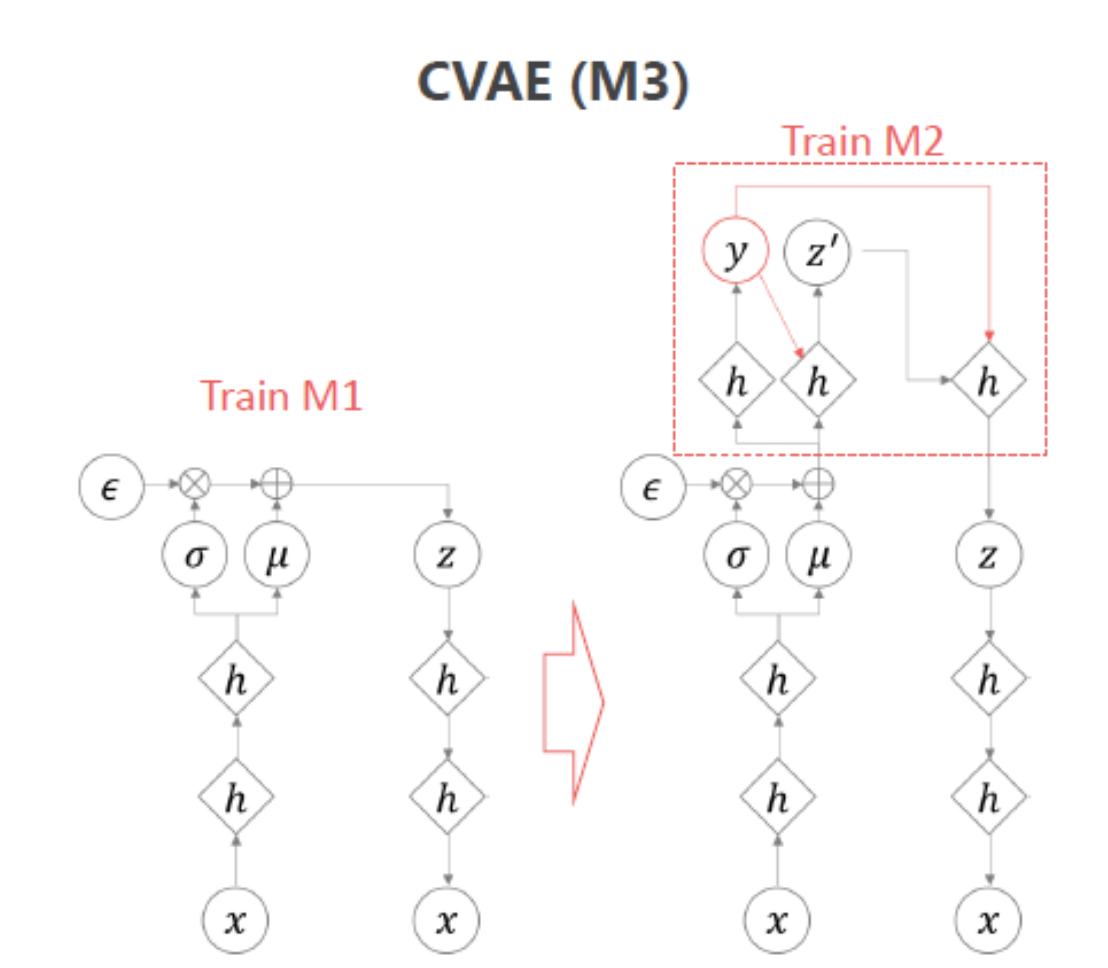
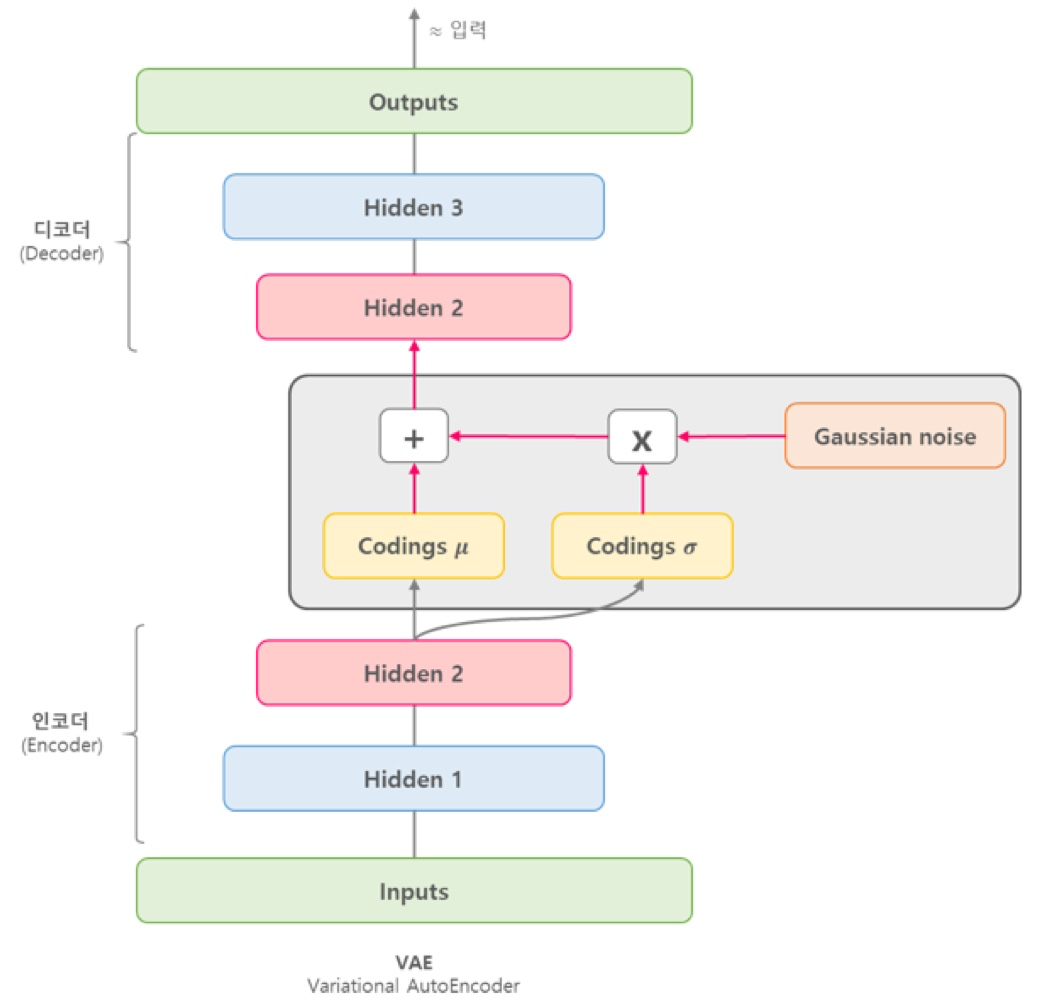
HyperparmetersTry random values: Don’t use a grid→ 왼쪽처럼 grid 형태로 parameter를 발생시키지 마라!→ 오른쪽 처럼 random하게 parameter를 발생시켰을 때 성능 좋은 parameter를 더 빨리 찾을 수 있다.💡이유: parameter마다 민감도가 다르기 때문!Coarse to fineAppropriate scale for hyperparameter💡그래서 이 부분에서는 log scale에 uniform하도록 랜덤하게 해주는 것이 좋다! Hyperparmeters for exponentially weighted averages → β 가 0.9~0.9005 사이일 때는 별로 안중요함. 정밀하게 세팅할 필요가 없음→ β 가 0.9990~0.99..