
- effectiveness 와 efficiency는 다름
→ effectiveness는 quality를 의미
→ efficiency는 서비스 수행하는데 필요한 자원의 양(시간, 메모리)을 따지는거
빠른데 메모리 엄청 많이 필요하고 이러면 efficiency 안좋은거
사람 인식 진짜 정확하게 하는데 1년 걸리고 이러면 efficiency 안좋은거
→ 오늘 배우는 regularziation은 effectiveness를 위한거
즉 퀄리티를 높이기기 위한거!
Train/Dev/Test Sets

→ 만약 training할 때 쓴 data로 성능평가하는데 사용한다면 성능이 왜곡될거임
feature를 학습한게 아니라 그냥 외운건데 성능이 좋게 평가되니까
→ 학습이란 어떤 data에 대해서라도 올바른 결과를 내게 하는거임
- development set(”dev set”)
idea → coding → experiment → idea → coding → experiment ....
반복 중에(개발 중에) experiment에서 사용하는 data set을 의미
- test set
다 만들고 최종 결과물의 quality를 평가하는 data set을 의미
그럼 데이터를 어떻게 나눠서 써야할까?

→ 이렇게 data가 적으면
70/30, 60/20/20 이런식으로 나눠서 씀

→ 이렇게 data가 많으면
98/1/1 이런식으로 dev와 test에서 퍼센트 작게 가져가도 됨
Mismatched train/test distribution
- Cat detector를 만들거임

→ low-density cat pictures에서 동작하는걸 만든다 해서
high-density data가 있는데 low-density로 학습시킬 필요는 없음
학습은 high-density로 해도 됨!!
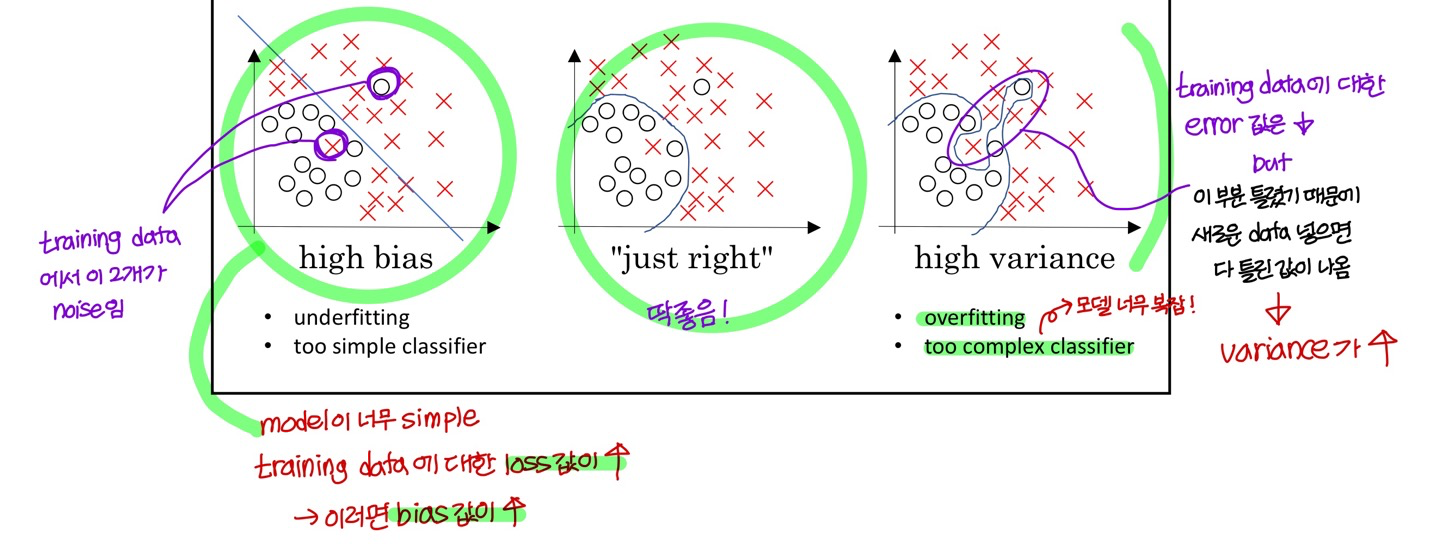
Bias and Variance
- Bias: training data에 대한 error 값
→ training data set에 대한 loss값이 0일 때 bias도 0임
→ 근데 training data 중에서는 측정기기에 오류 있어서 튀는 값, noise 끼인 값 섞여있음
→ 이런 상황에서 loss 0 만들어야한다고 억지로 끝까지 학습시키면 model 이 이상해짐
→ 이런 경우에 variance가 높아짐
→ 이게 높다는건 underfitting 되었다는거
💡즉, bias값이 0이라고 능사가 아님
- Variance: Training set error와 Dev set error의 차이
(Dev set error - Training set error)→ 이게 크다는건 overfitting 되었다는거

→ 아님! 사람이 봐도 틀리는걸 어떻게 맞추냐고~
제일 좋은 지능이 사람 지능이라 가정하고 인공지능 연구하는거임

→ 즉 bias 판단할때는 human error랑 값을 비교해야함
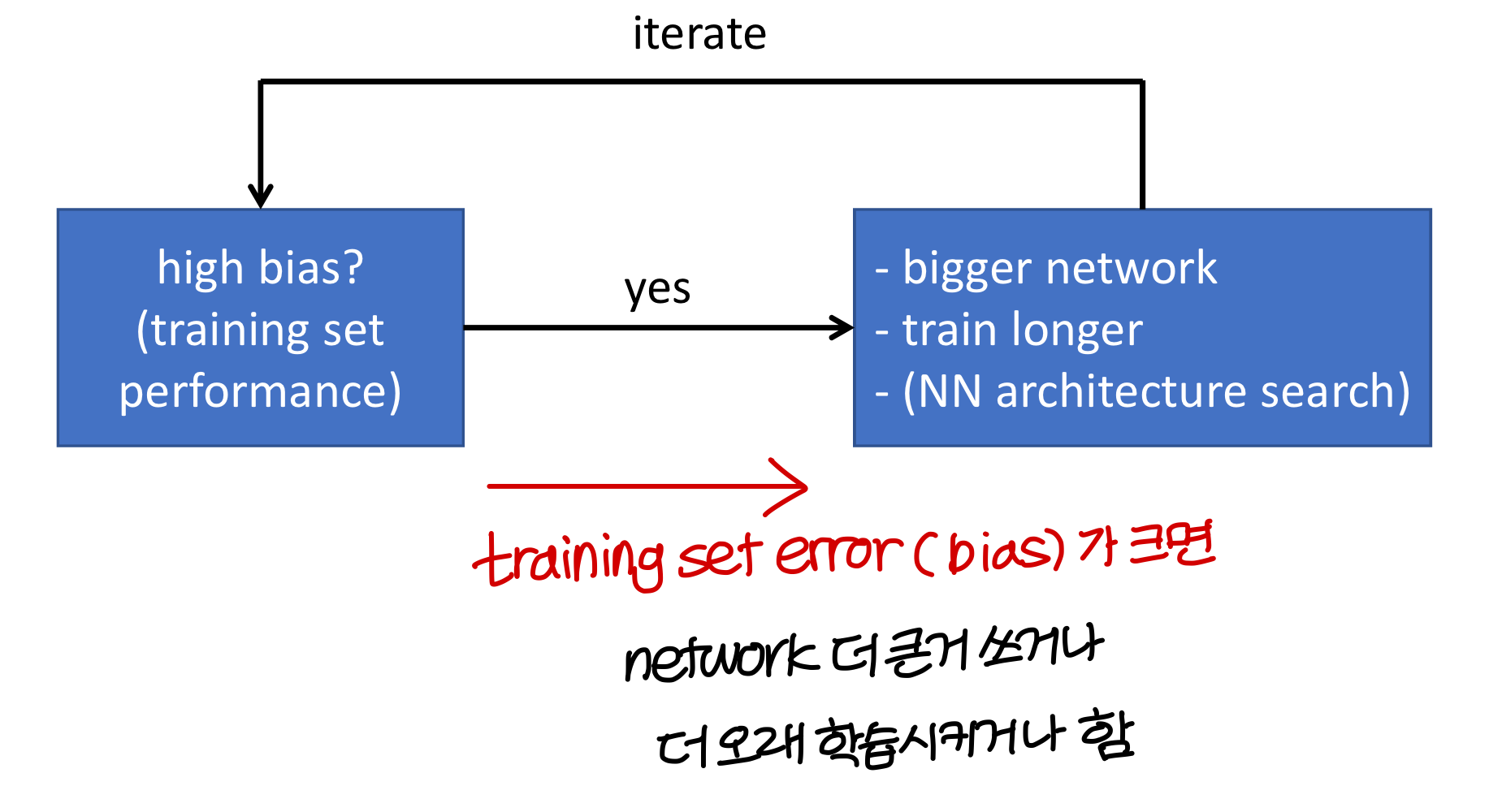
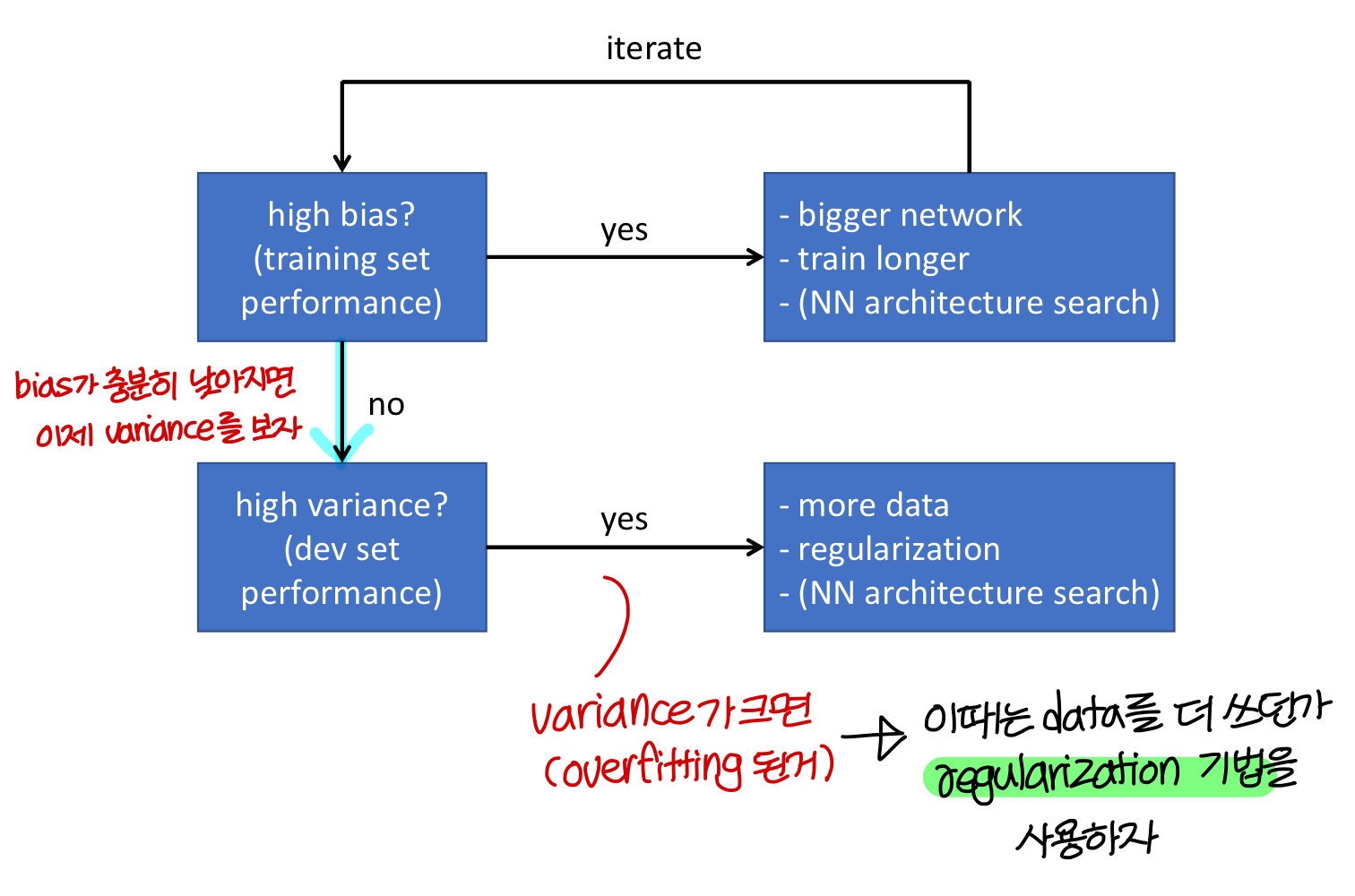
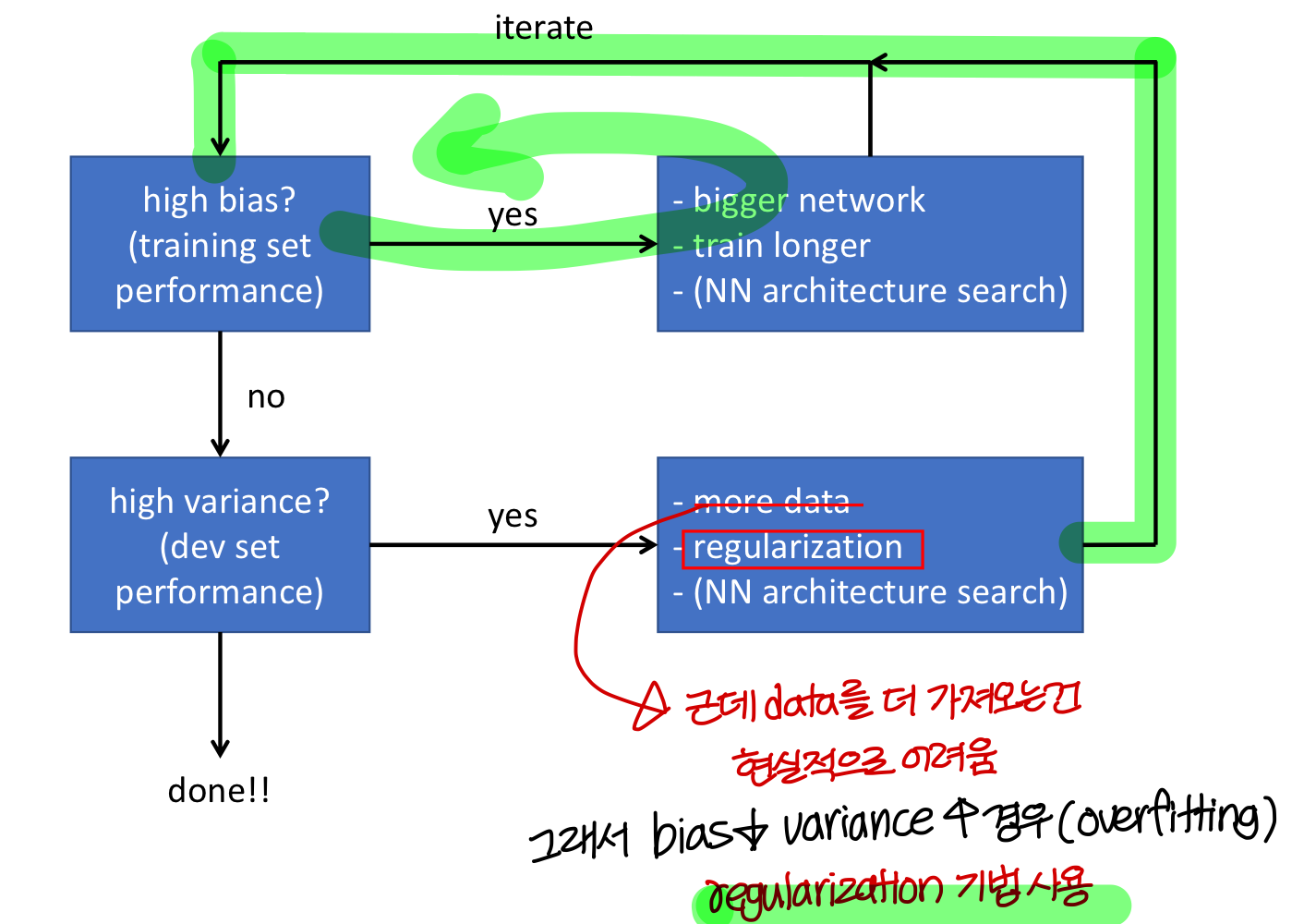
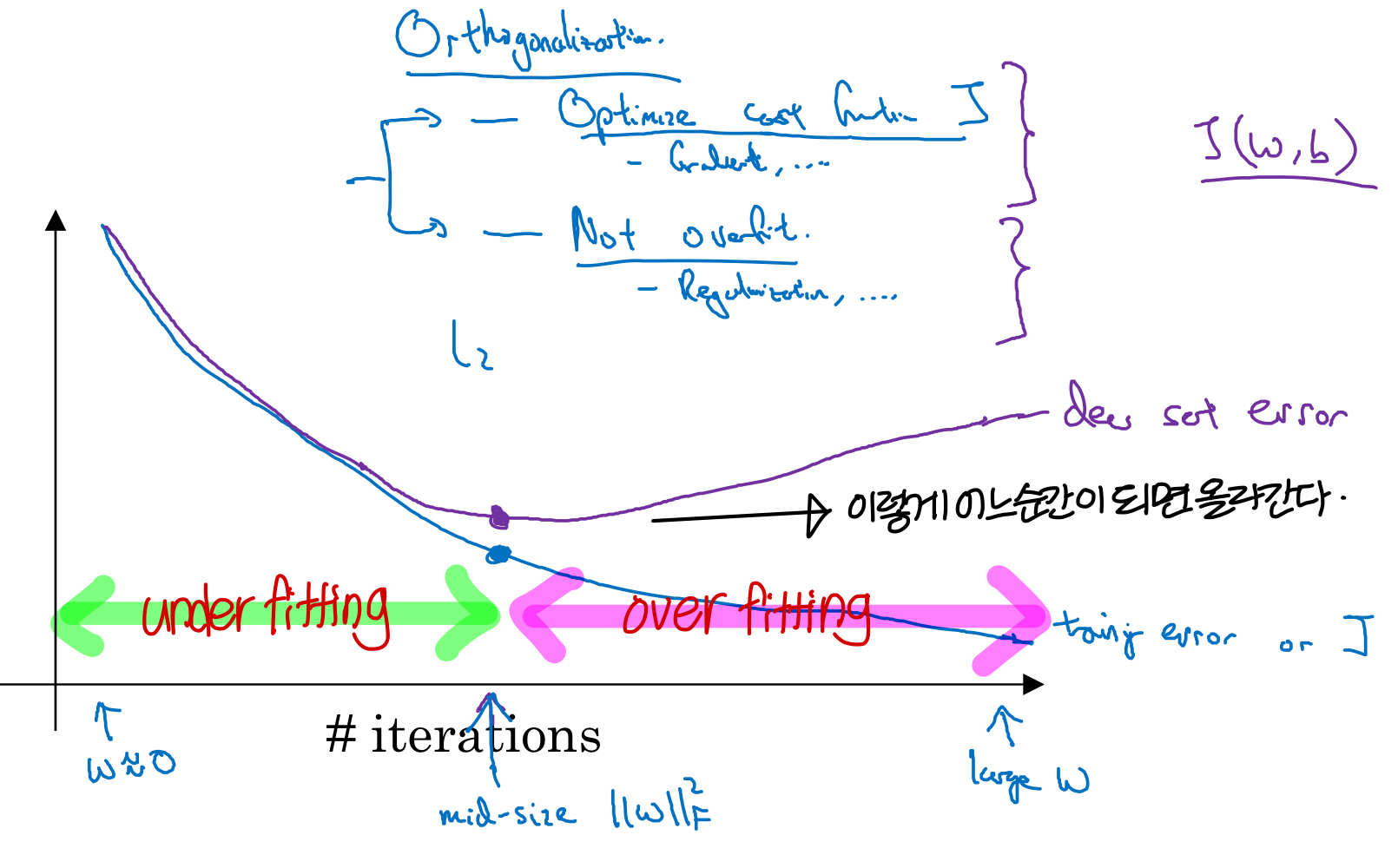
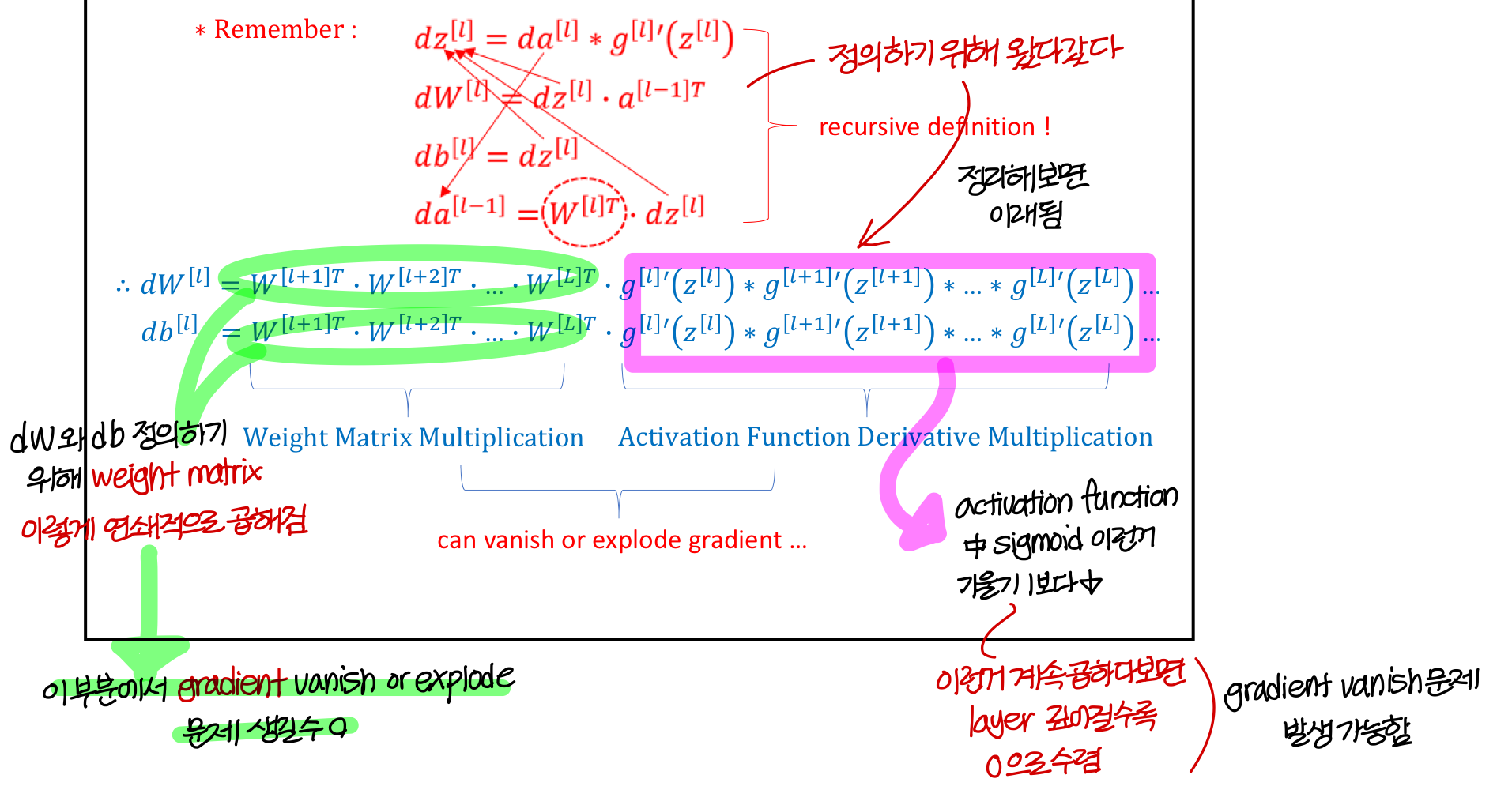
Basic recipe for machine learning
Regularization for Logistic Regression
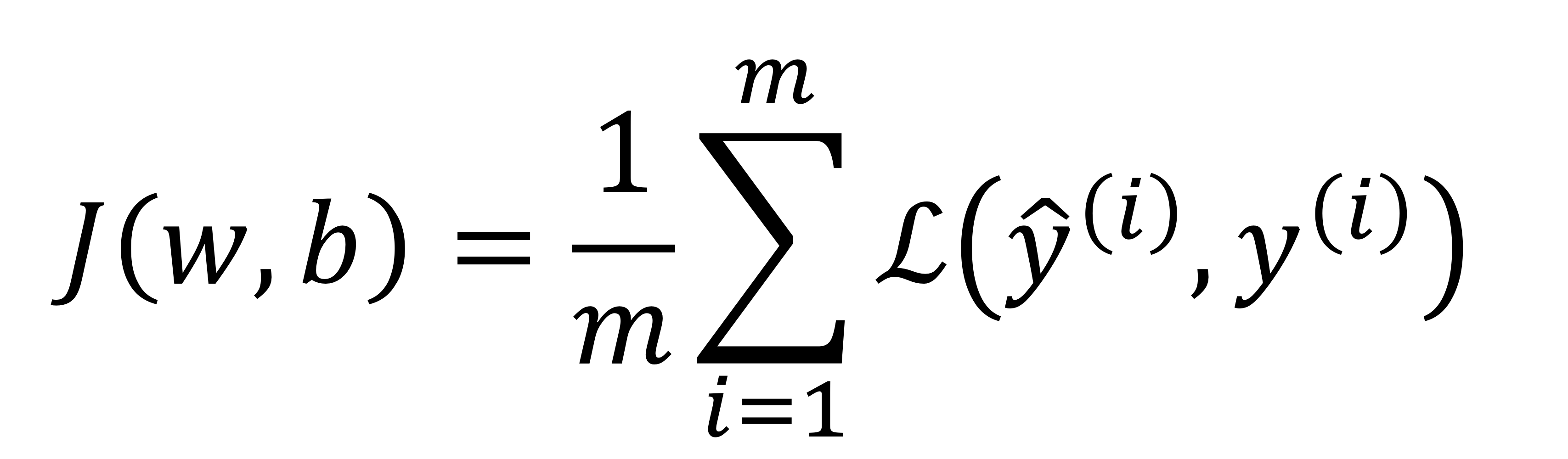
→ 우리가 원래 배운 cost function은 여기까지였음
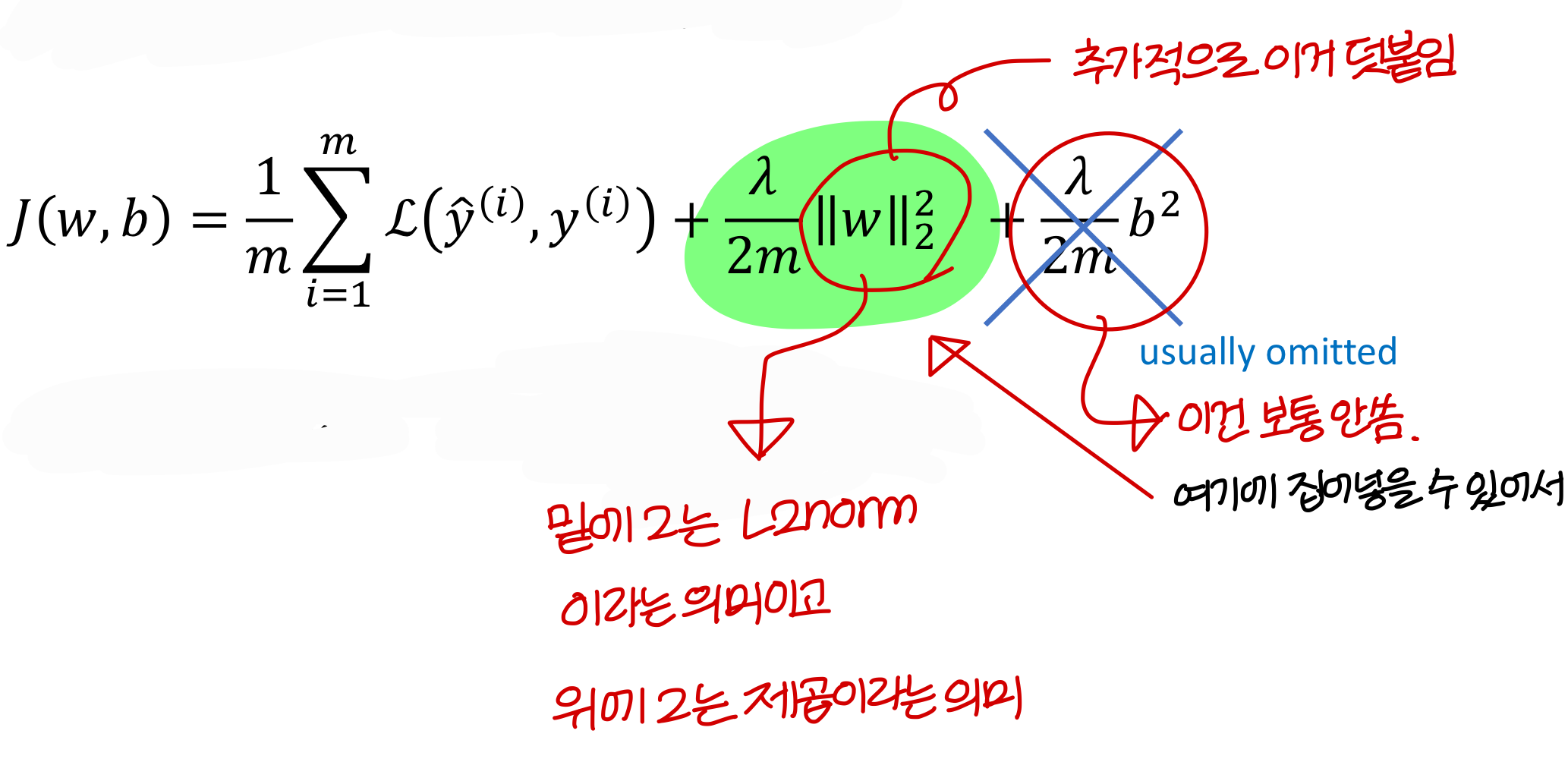
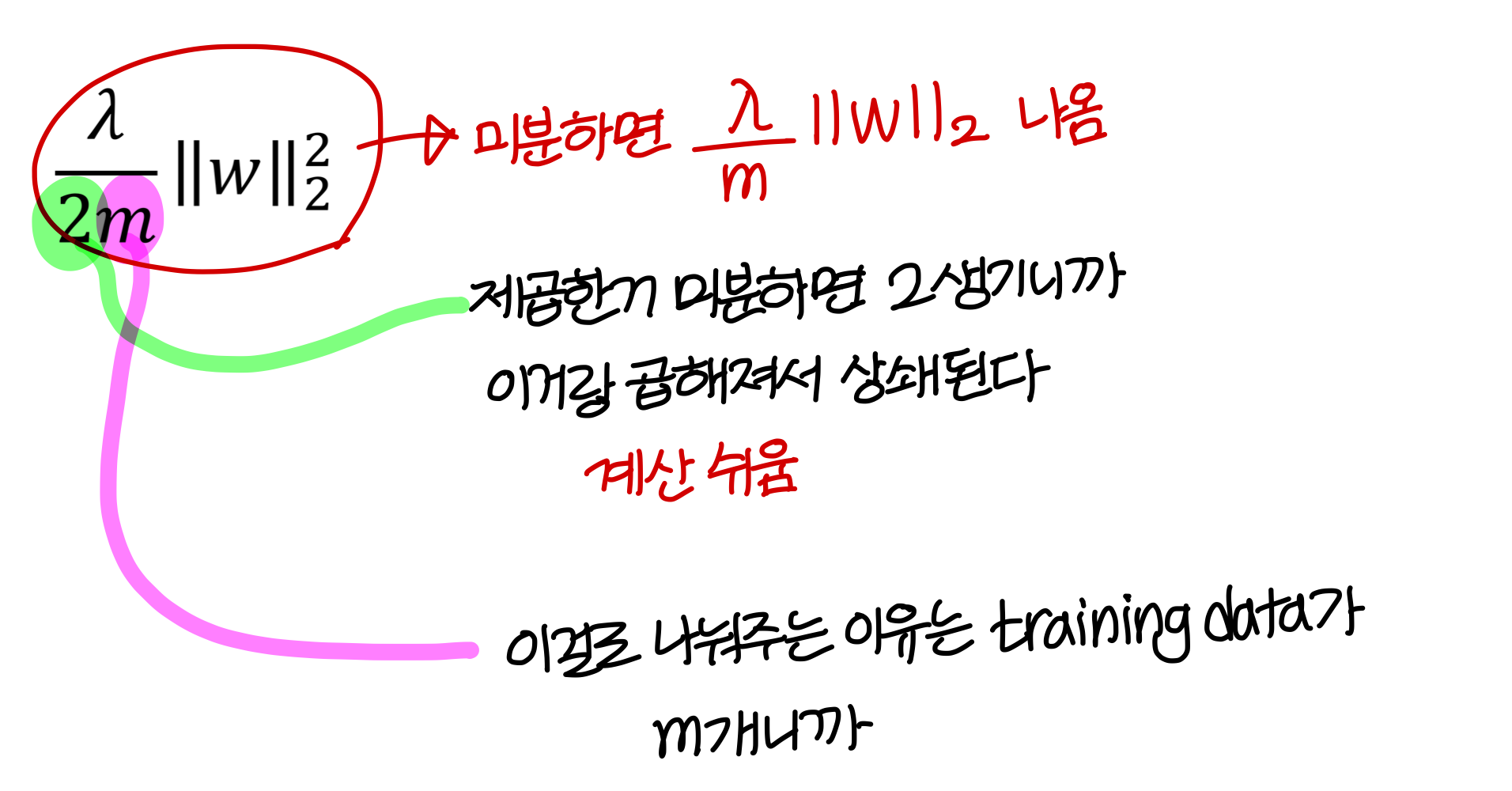
→ 그냥 초록색 항 덧붙여주는게 regularization 기법
→ 는 regularization 얼마나 해줄지 가중치값
- L2 regularization은 이렇게 계산
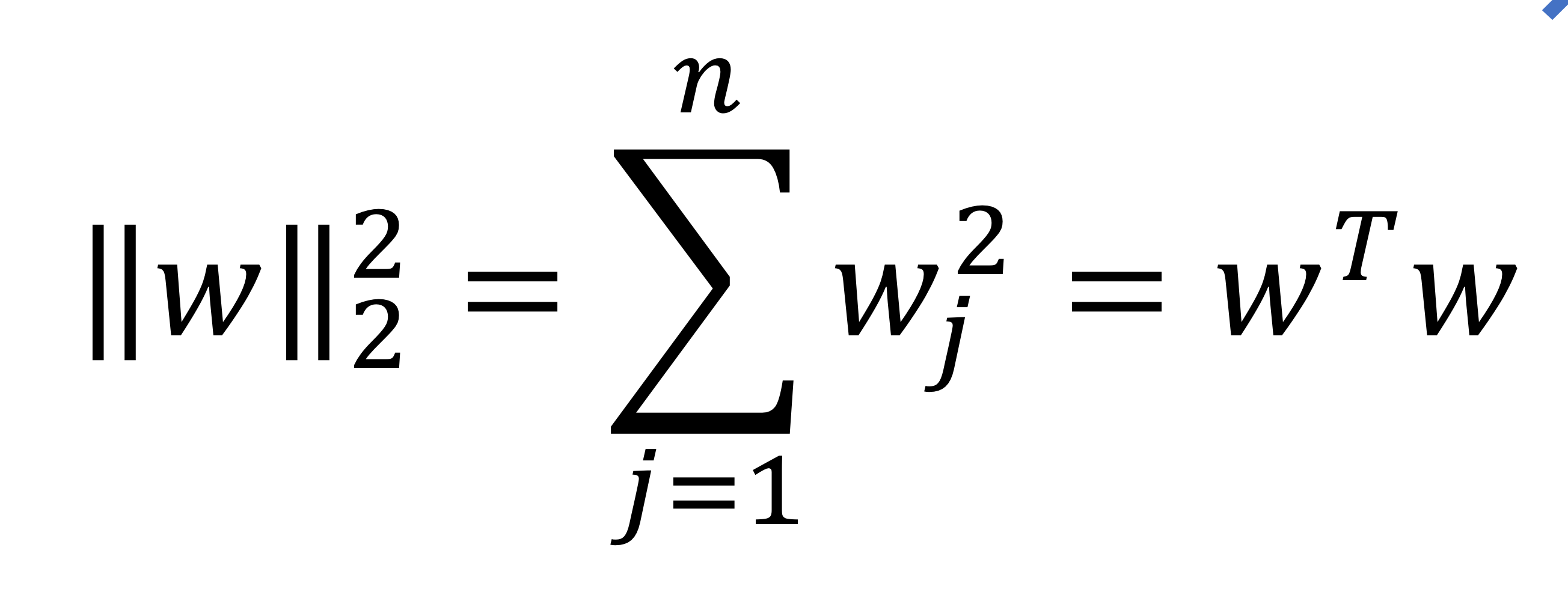
→ weight 제곱해서 다 더하면 된다.
→ 제곱할때 앞에껄 transpose하는거 잊지 않기
→ 여기서 layer 1개고, 뉴런 개수 n개
- L1 regularization도 있음
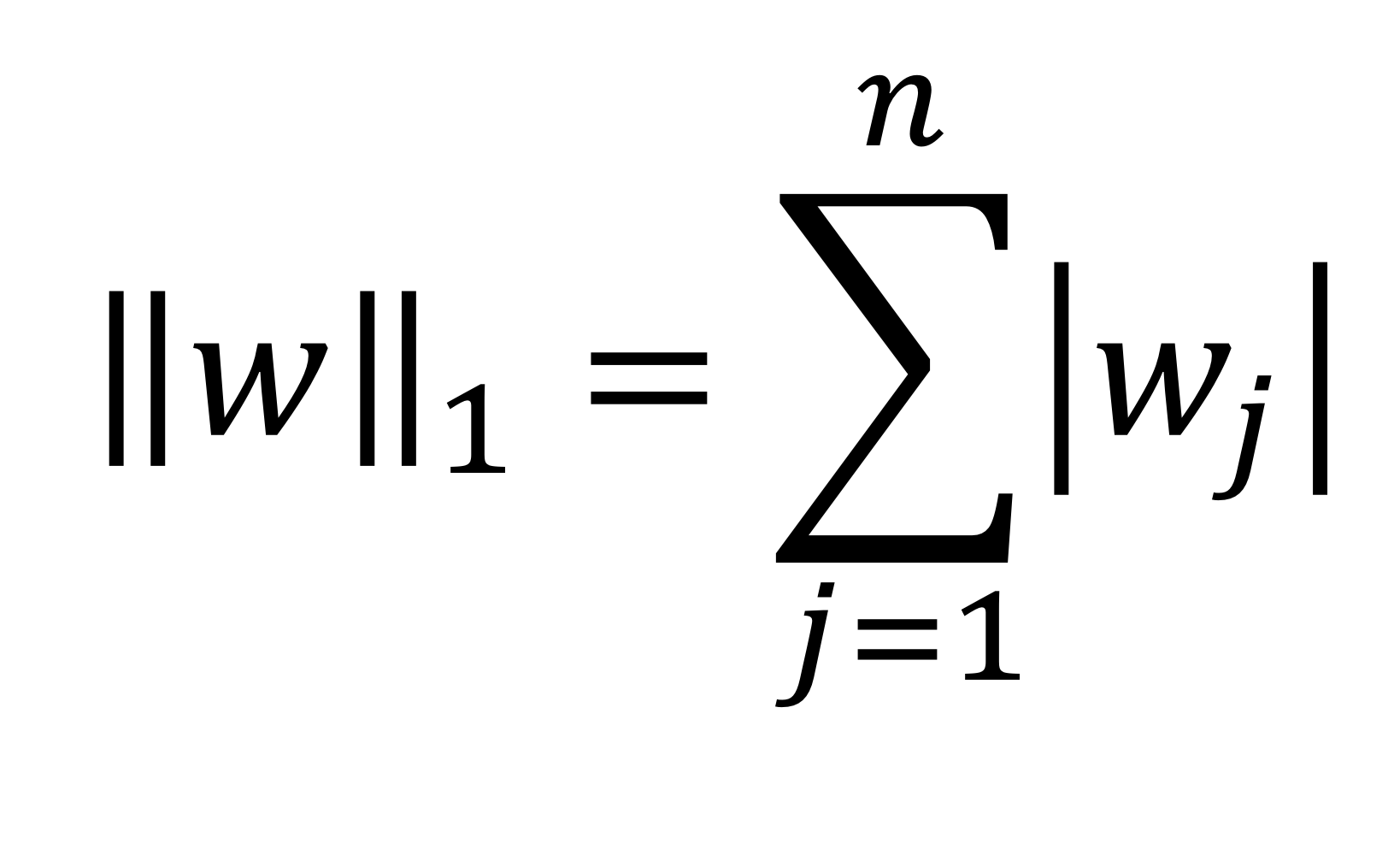
→ 이건 제곱이 아니라 절댓값 쓴거
→ 제곱이든 절댓값이든 어쨌든 크기를 의미하는거
- 를 미분하면?
Regularization for Neural Network

- 미분하면 이런 꼴로 나타남

- 식을 정리하면 이렇게
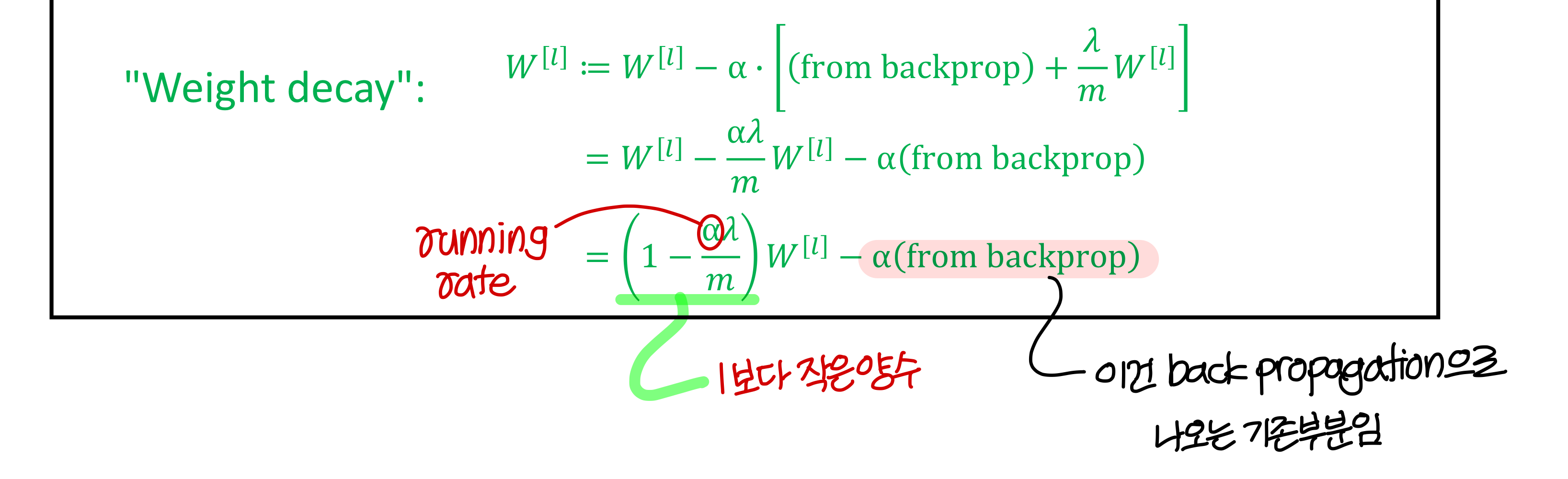
→ weight 값에 1보다 작은 값을 곱해서 크기를 찔끔 줄여줌
→ 그런데 이게 학습이 계속되다보면 누적되니까 weight의 크기가 작아짐
학습이 진행될수록 weight 값의 크기를 상당히 작게 하는게 이거의 의도
→ 이러면 Overfitting을 막을 수 있음
weight 값의 절댓값(||w||) 을 줄여주니까 변화율이 작음
→ 극단적인 model이 만들어지지 않도록 도와주는거임
→ 학습을 오래하면 ||w||가 0에 가까워짐
의미있는 애들만 남고 나머지는 거의 0
How does regularization prevent overfitting?
→ weight가 과하게 크면 구불구불한 함수들이 만들어지게 되는데
regularization은 이런 weight의 크기를 줄여서 model이 linear에 가까워지도록함
Dropout Regularization
- 앞에서 배운 Regularziation을 하면 weight가 대부분 0이 되고, 의미있는 값만 남음
→ 그냥 이럴 바에
random하게 뉴런을 on/off 하자!는 생각에서 나온 아이디어
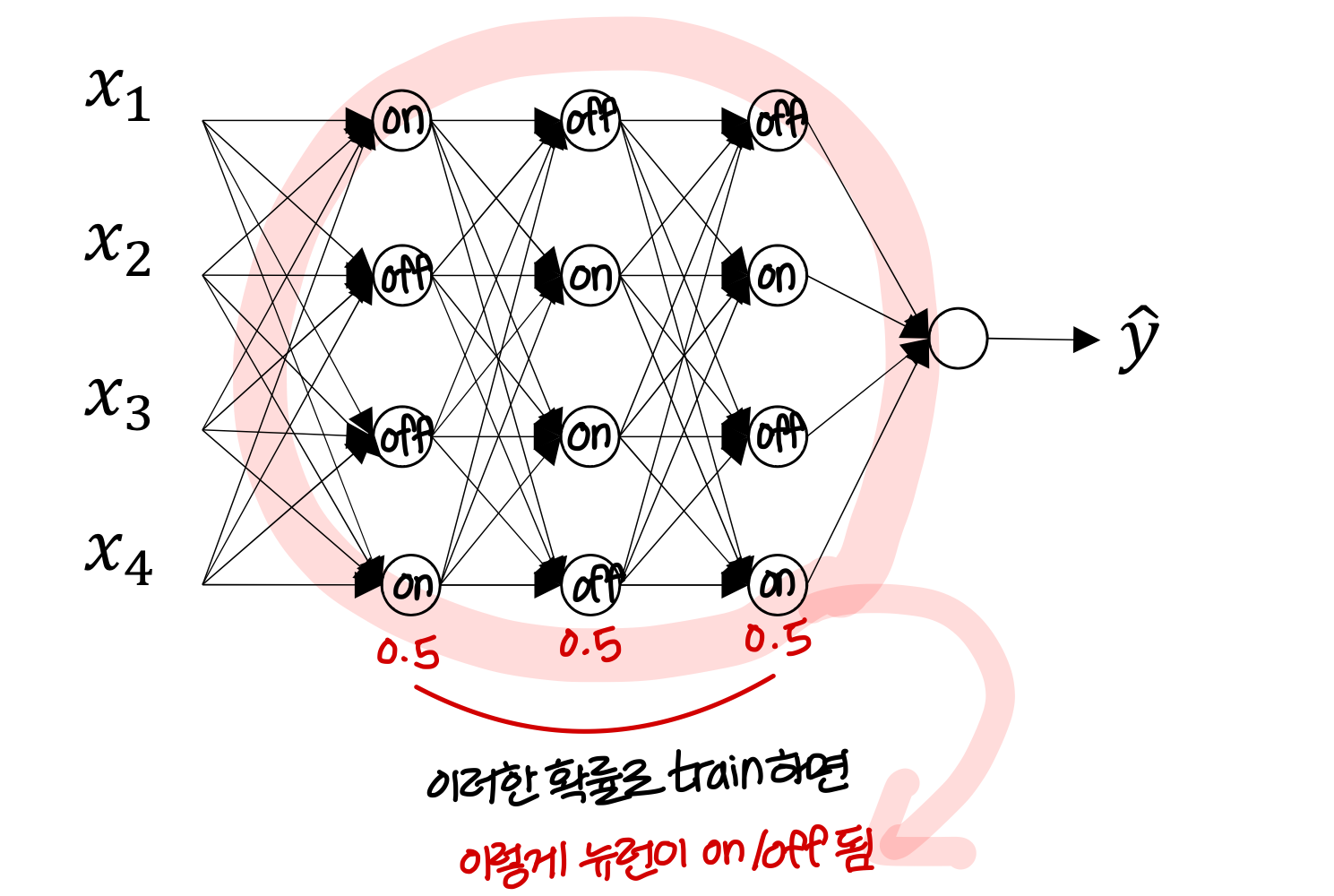
- Dropout Regularziation의 효과
- 수렴이 빨리됨
- loss도 빨리 감소함
→ 간단하지만 효과가 좋음
- 랜덤하게 cross over해서 교배할 때, generation 거칠수록 유전자가 좋아짐
→ 왜? 강한 유전자가 잘 퍼뜨리니까
→ dropout도 비슷한 맥락임
왜 잘되는지 수학적으로 증명하기는 어려움
→ 모든 layer의 모든 뉴런이 유의미한 feature를 만들어내지는 X. 일부는 noise임 (이런게 존재하면 학습에 방해됨)
근데 dropout을 하게되면
(feature들을 골고루 사용하는 효과) + (꼭 필요한 feature들만 남김)
- layer 별로 확률 다르게 하는거 가능함
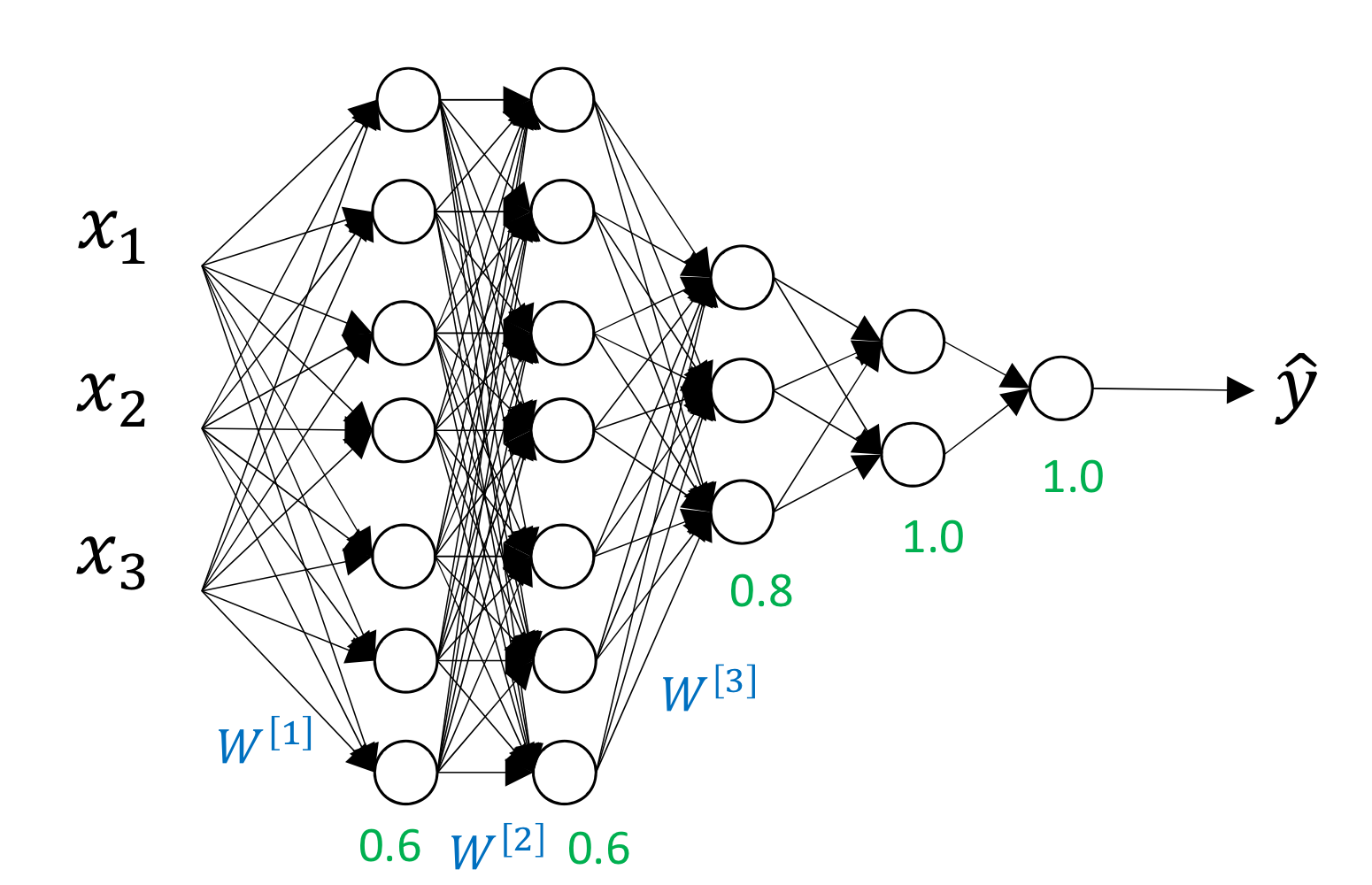
- training 할 때만 on/off하고 실제 수행시(test시)에는 on/off 안함
Data augmentation(데이터 증강)
- training data 만드는게 project의 80%
그러다보니 data 수를 뻥튀기하는 방법을 연구하게 됨
- 이미지, 동영상에서 많이 사용된다!
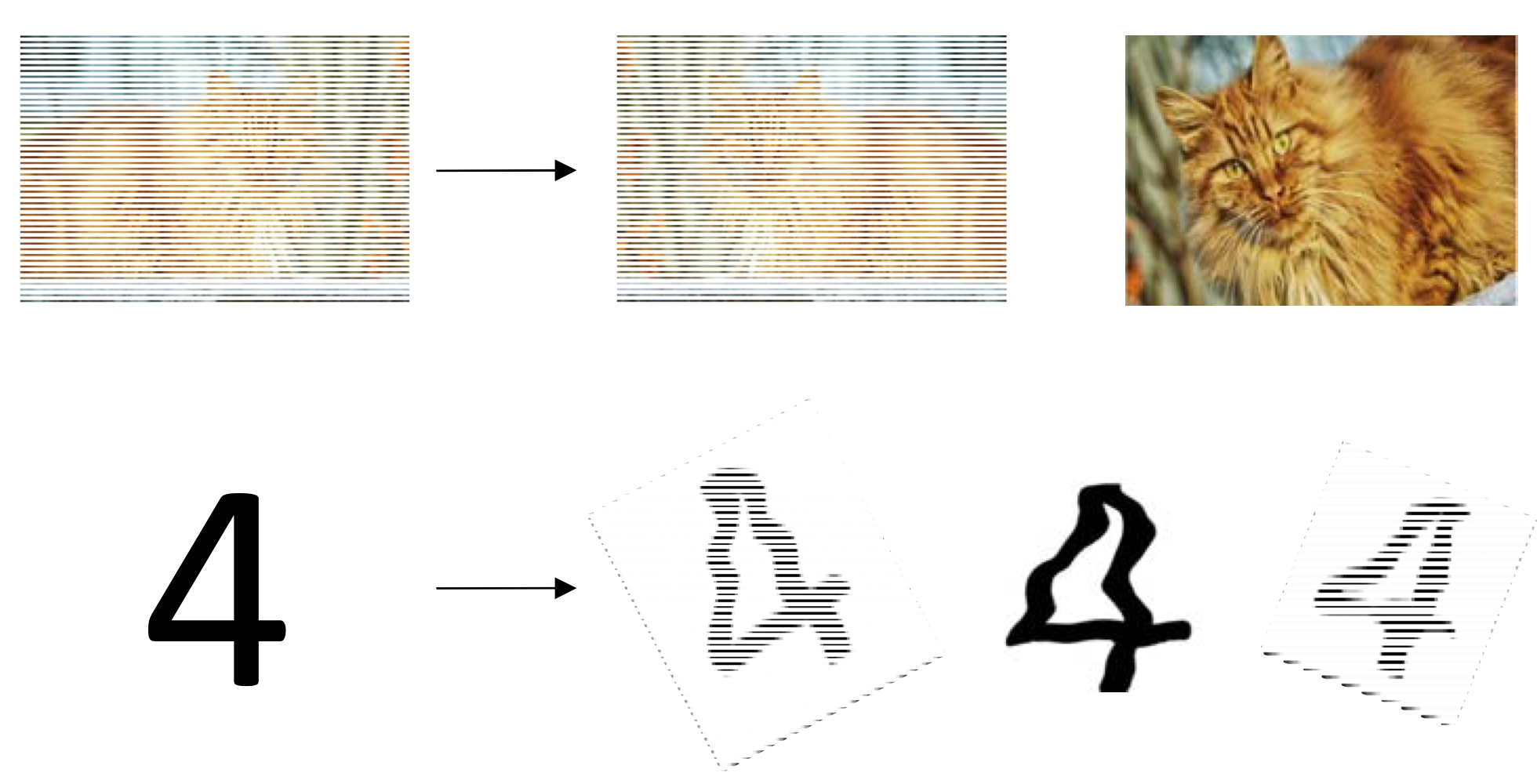
→ 이렇게 확대, 축소, noise 주기, 회전 등의 방법으로 한장을 수십장으로 만든다.
- 근데 자연어는 뻥튀기가 어려움
→ 이미지는 pixel 좀 잘못들어가도 고양이는 여전히 고양이
→ 근데 단어가 잘못 들어가게 되면 문장이 완전 이상
Early stopping
→ 이래서 dev set이 필요한거
계속 확인하면서 dev set error 올라가면 그만 학습시켜야함 ⇒ overfitting 되는거니까
Normalizing training sets
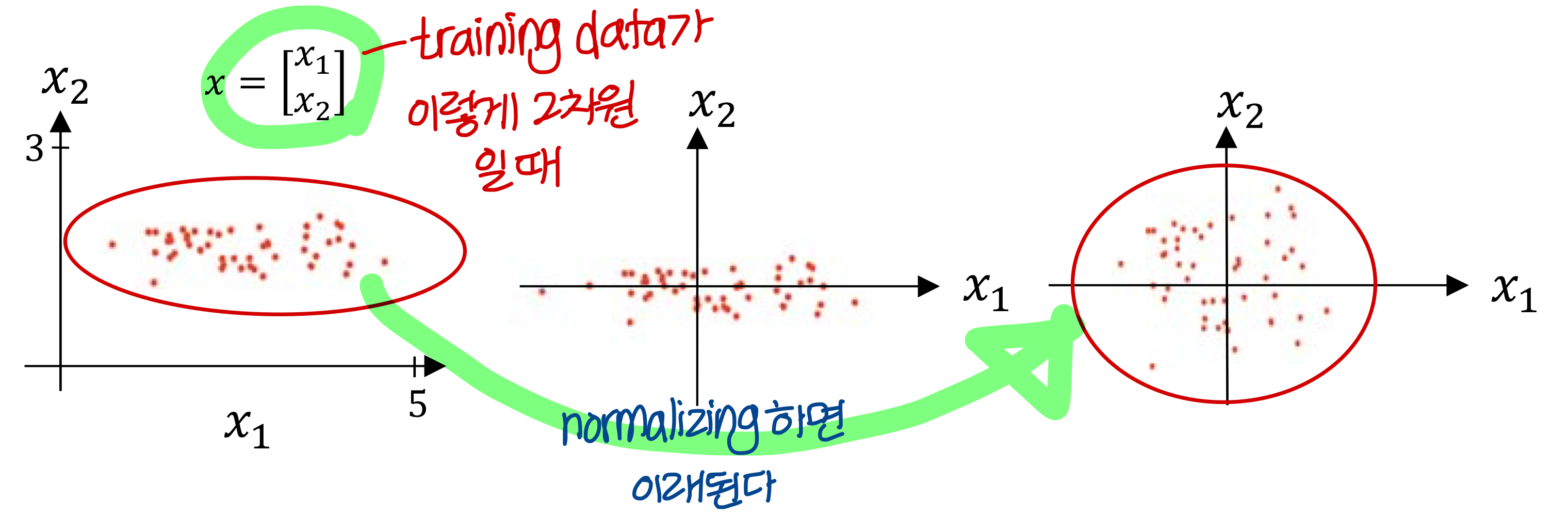
- 하는 방법
- subtract mean, 평균 빼기 → 이렇게 하면 training data set의 평균이 0이 됨
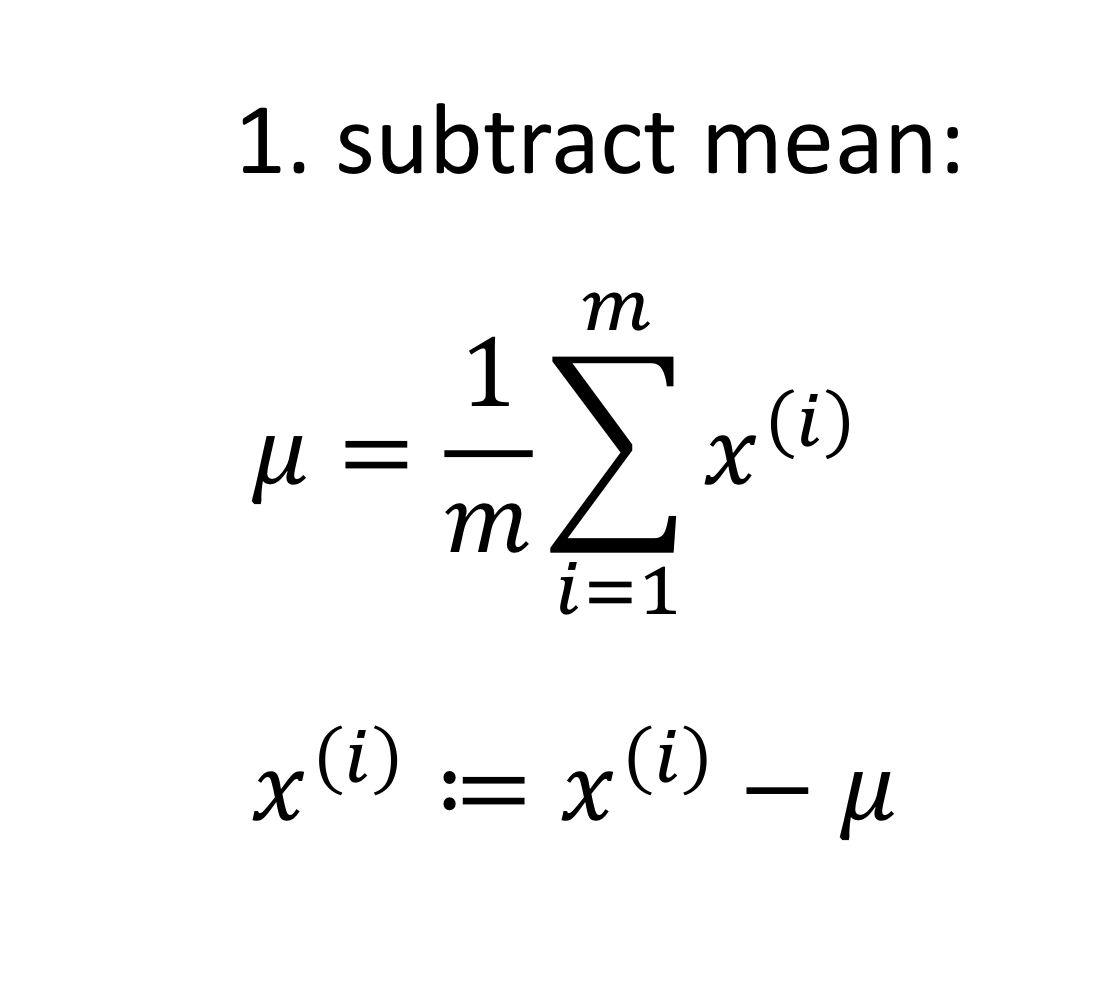
- normalize variance, 표준편차만큼 나눠주기
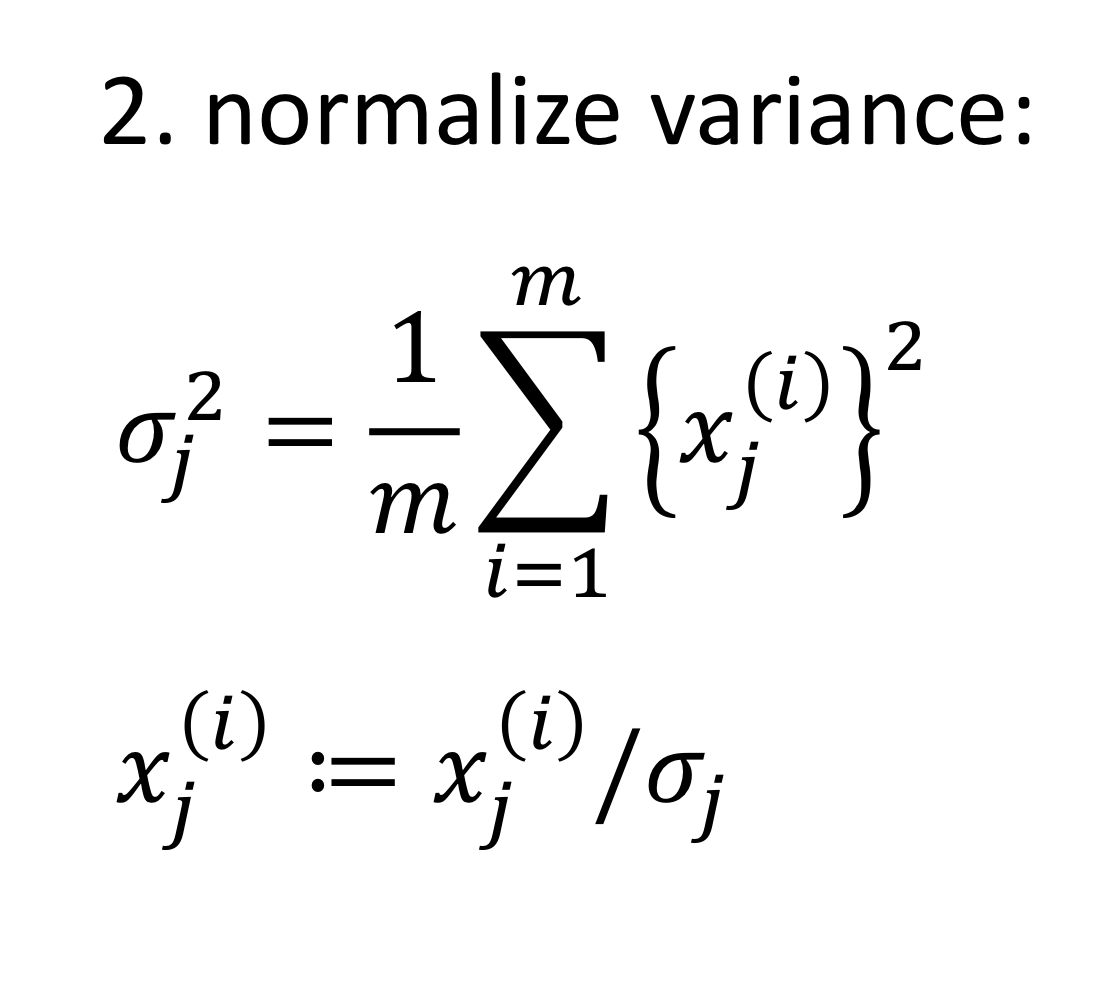
→ 표준편차 구하는 방법: 평균으로부터의 거리 제곱해서 루트 씌우기
여기서는 평균 0이니까 그냥 제곱해서 평균낸다음 루트 씌우면 됨
- subtract mean, 평균 빼기 → 이렇게 하면 training data set의 평균이 0이 됨
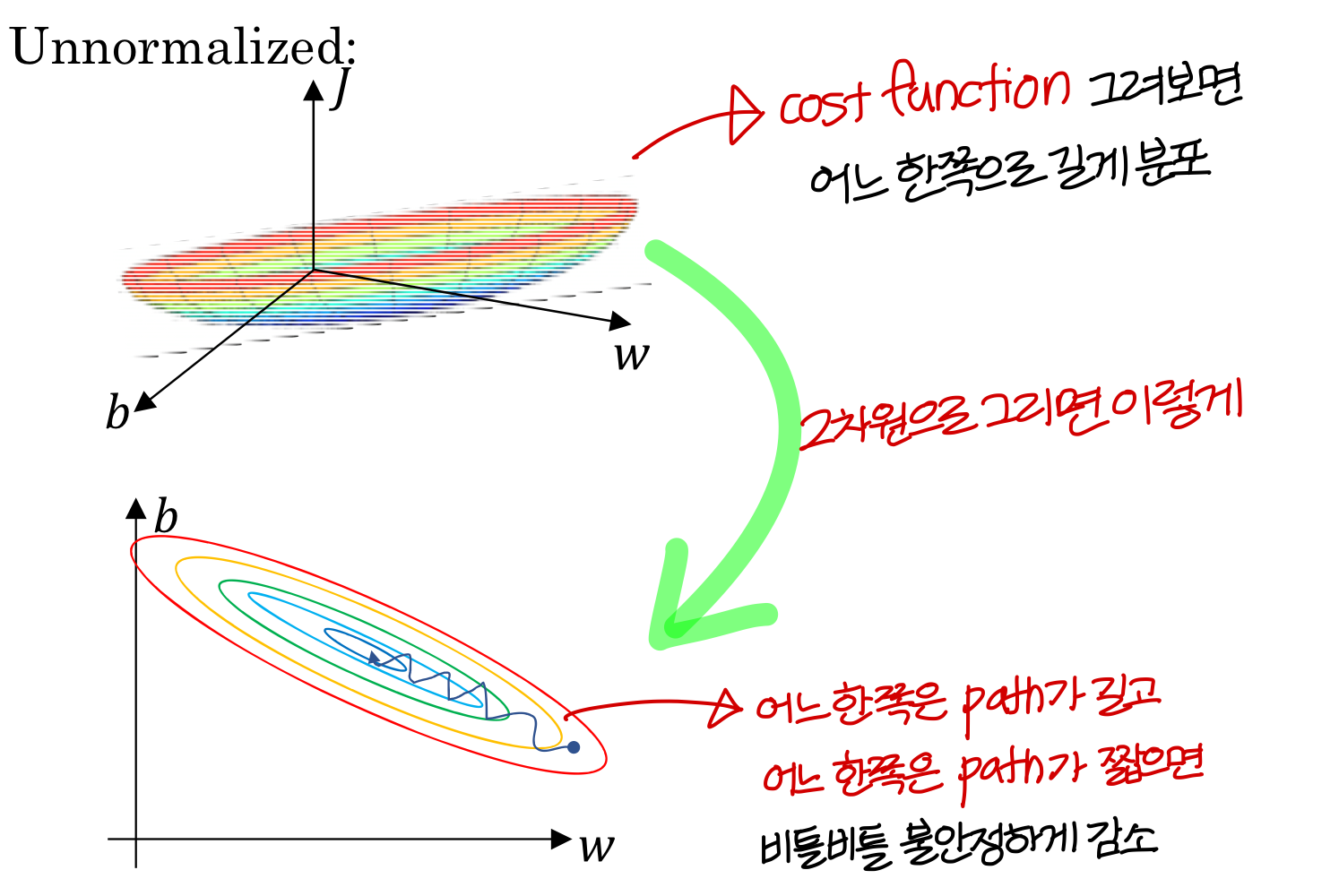
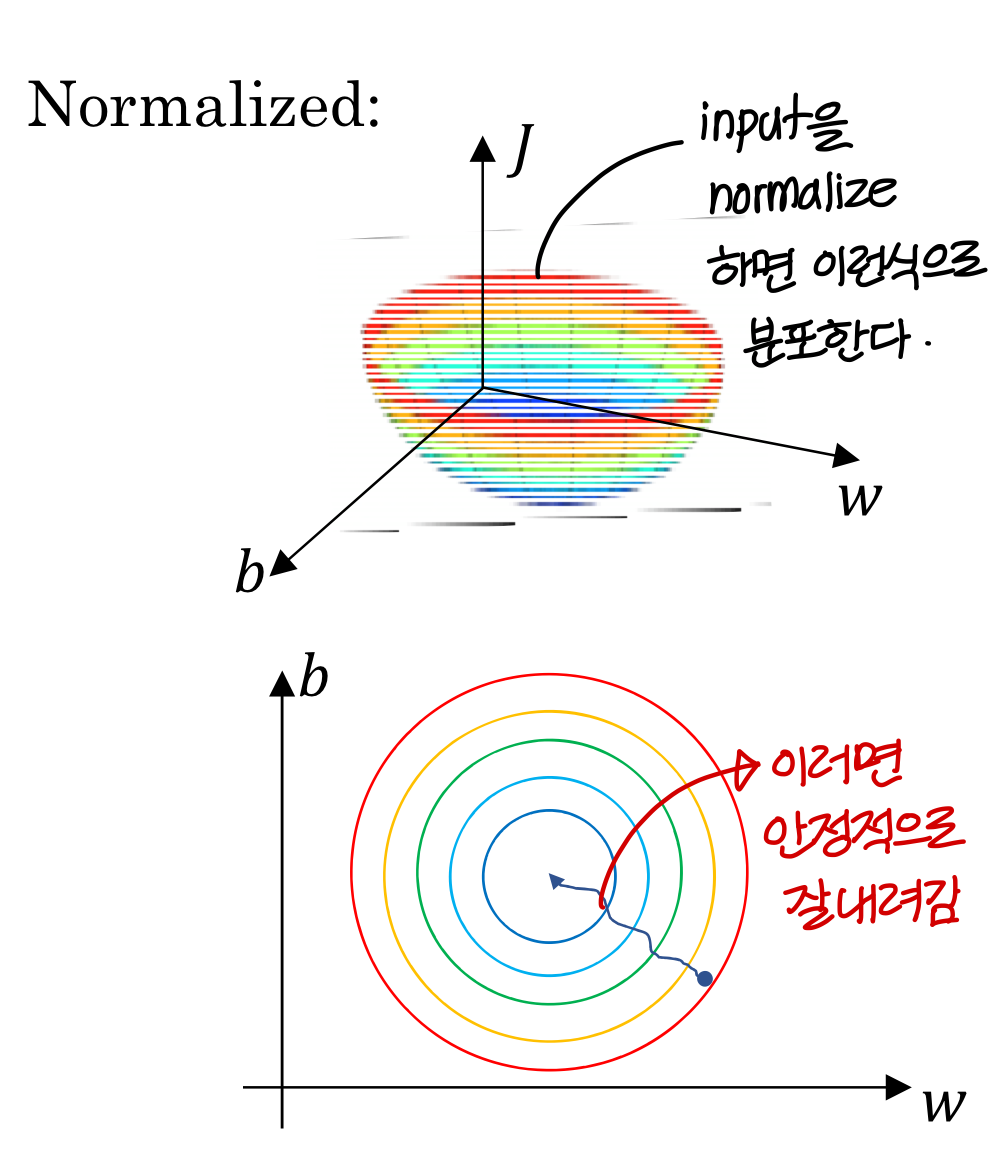
Why normalize inputs?
→ 지금은 Input normalization 살펴볼거임.
layer normalization, batch normalization 도 있음
- Unnormalized
- Normalized
Vanishing/exploding gradients

→ 이렇게 입력 2개, 출력 1개인 neural net이 있음
→ deep neural net이라서 엄청 깊음
- 만약 activation function을 안쓸 경우 값 이래 계산됨
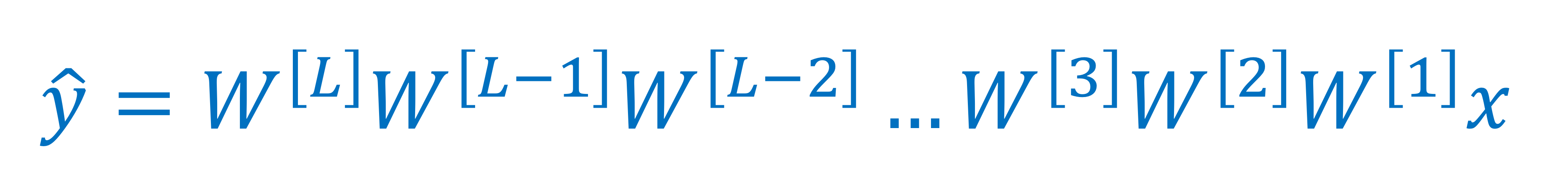
- 가 이럴경우 (1)
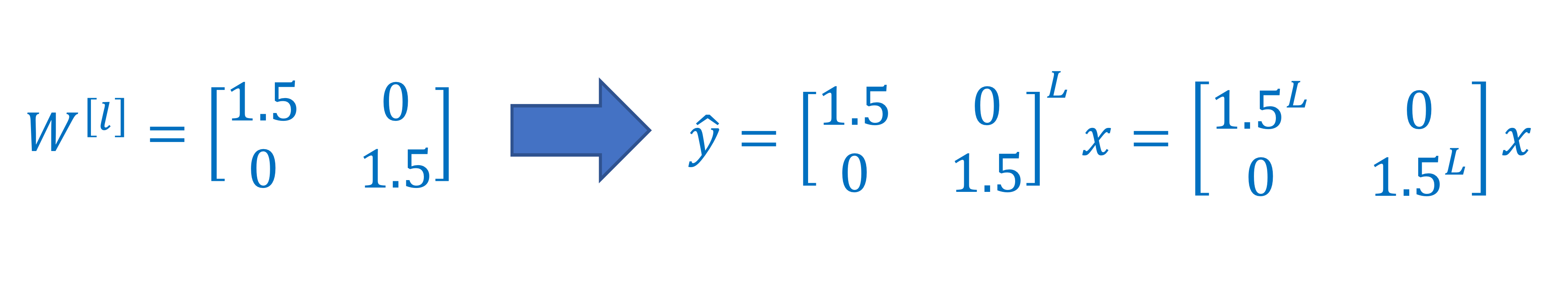
→ 결과가 엄청나게 큰 숫자가 됨
→
explode된다고 표현
- 가 이럴경우 (2)
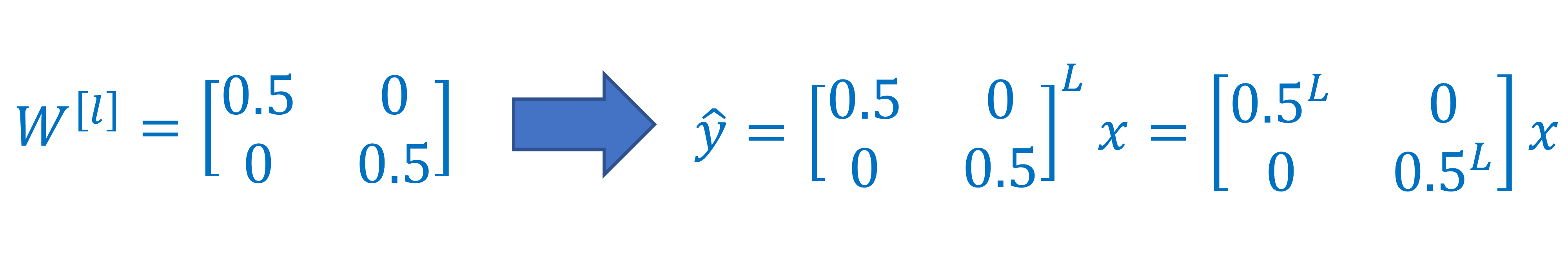
→ 결과가 엄청나게 작은 숫자가 됨. 0으로 수렴
→
vanish된다고 표현
⇒ 근데 RGB 값에는 음수가 의미가 없으니까 이렇게 하지만
다른 경우에선 음수가 의미있을수도 있으나 함부로 ReLU 사용하면 안됨
Weight Variance initialization for deep network
→ 이렇게 안하면 특정 Input에 의해 좌지우지 되는 현상이 발생할 수 있음
예를 들어 고양이 발톱이 잘나오는 사진으로만 학습시키면 ⇒ 발톱만 보고 고양이라 판단할 수 있음
→ weight의 variance를 이렇게 되도록 해야함
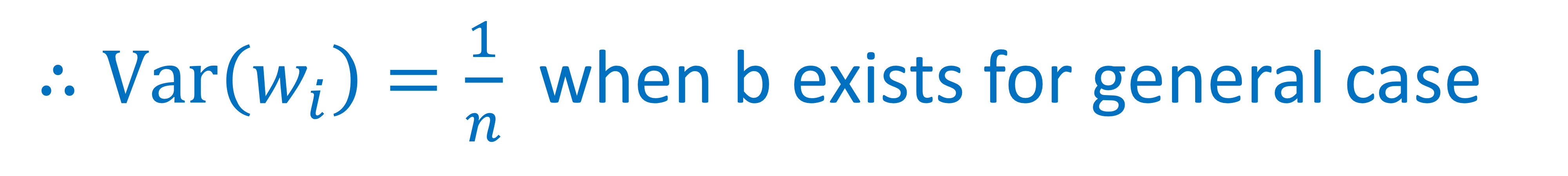
→ ReLU activation function을 쓸 경우 variance 이렇게 세팅하는게 더 잘됨 (실험결과)

→ tanh 쓸 경우에는

Uploaded by N2T