
What is a deep neural network?
- hidden layer가 2개 이상이면 deep neural network임
→ hidden layer 없거나 1개면 “shallow” network
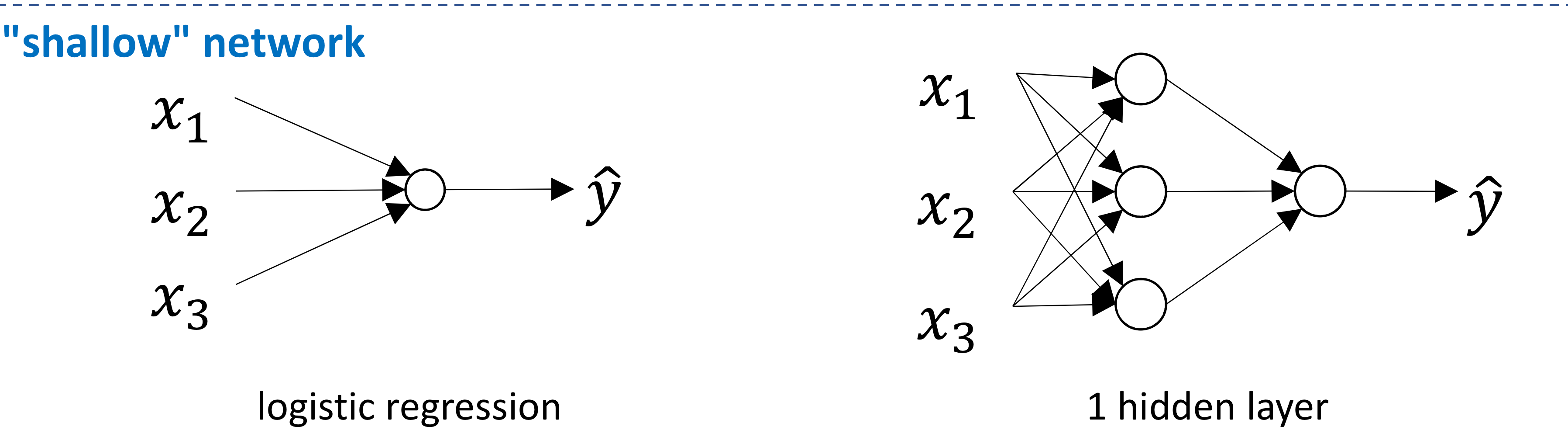
→ hidden layer 2개 이상이면 “deep” network

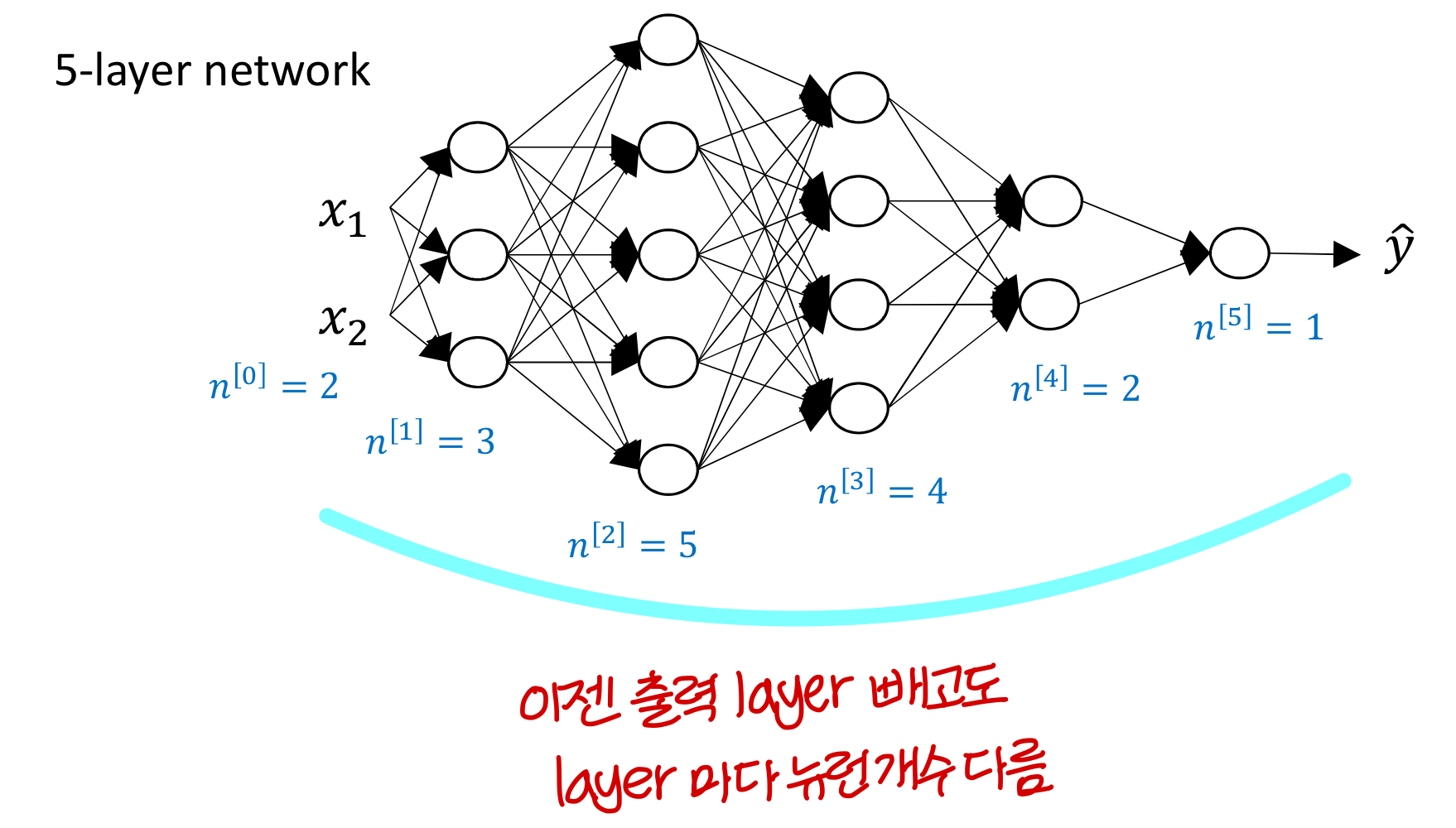
Deep neural network notation
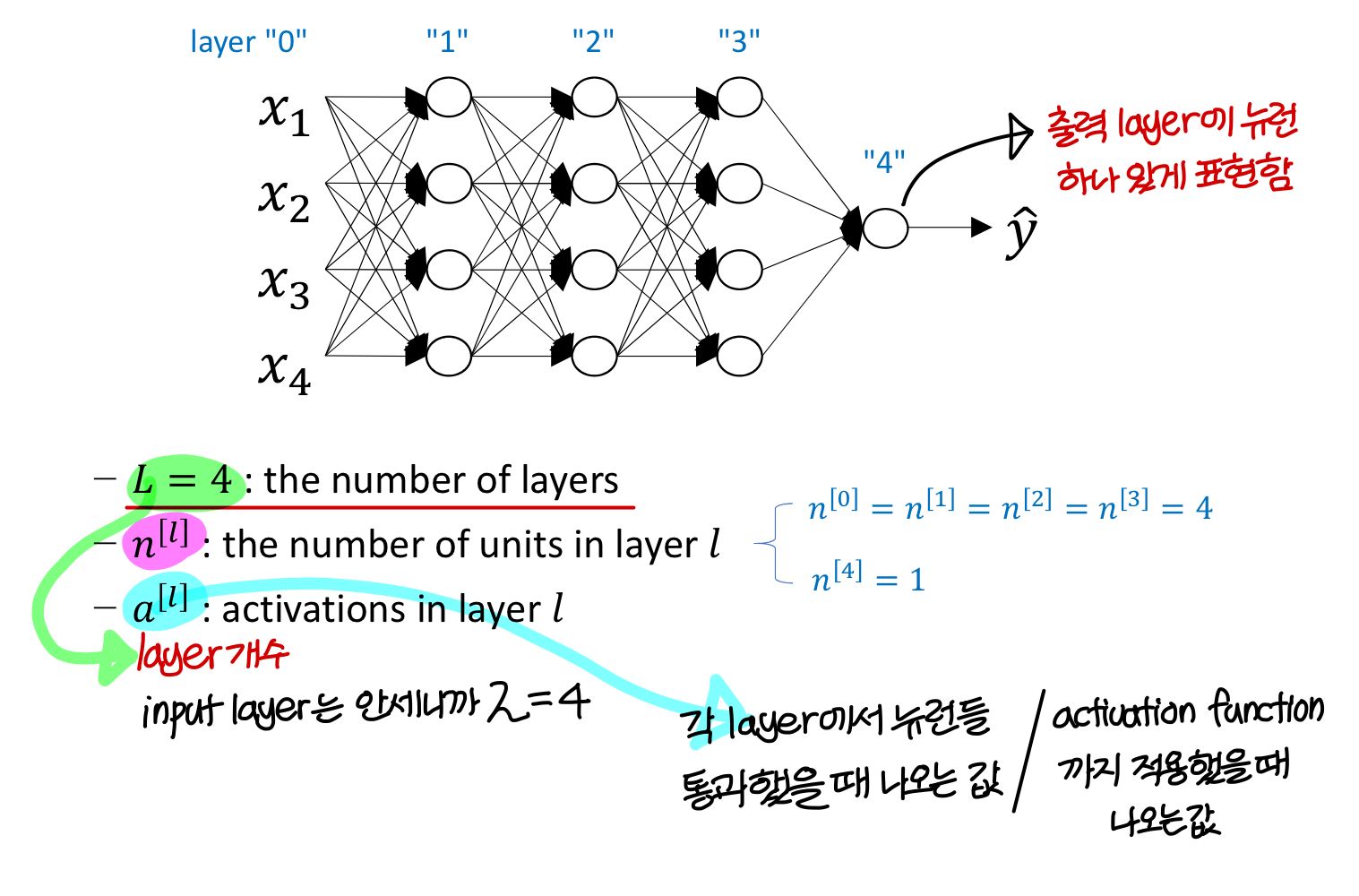
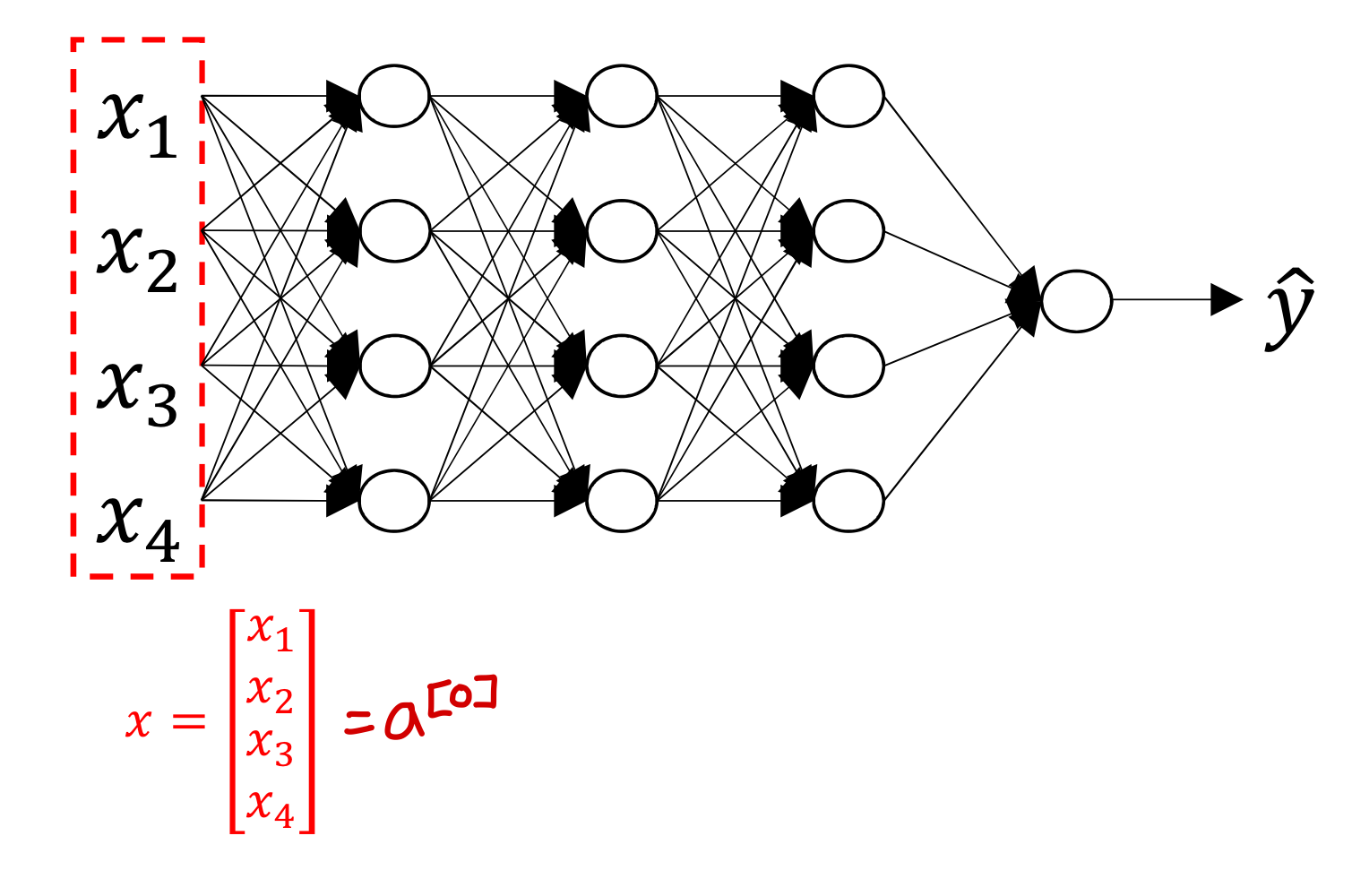
→ 이때 input data를 가상의 뉴런의 출력값으로 봄
→ 마지막으로 출력되는 값은 이렇게 표현
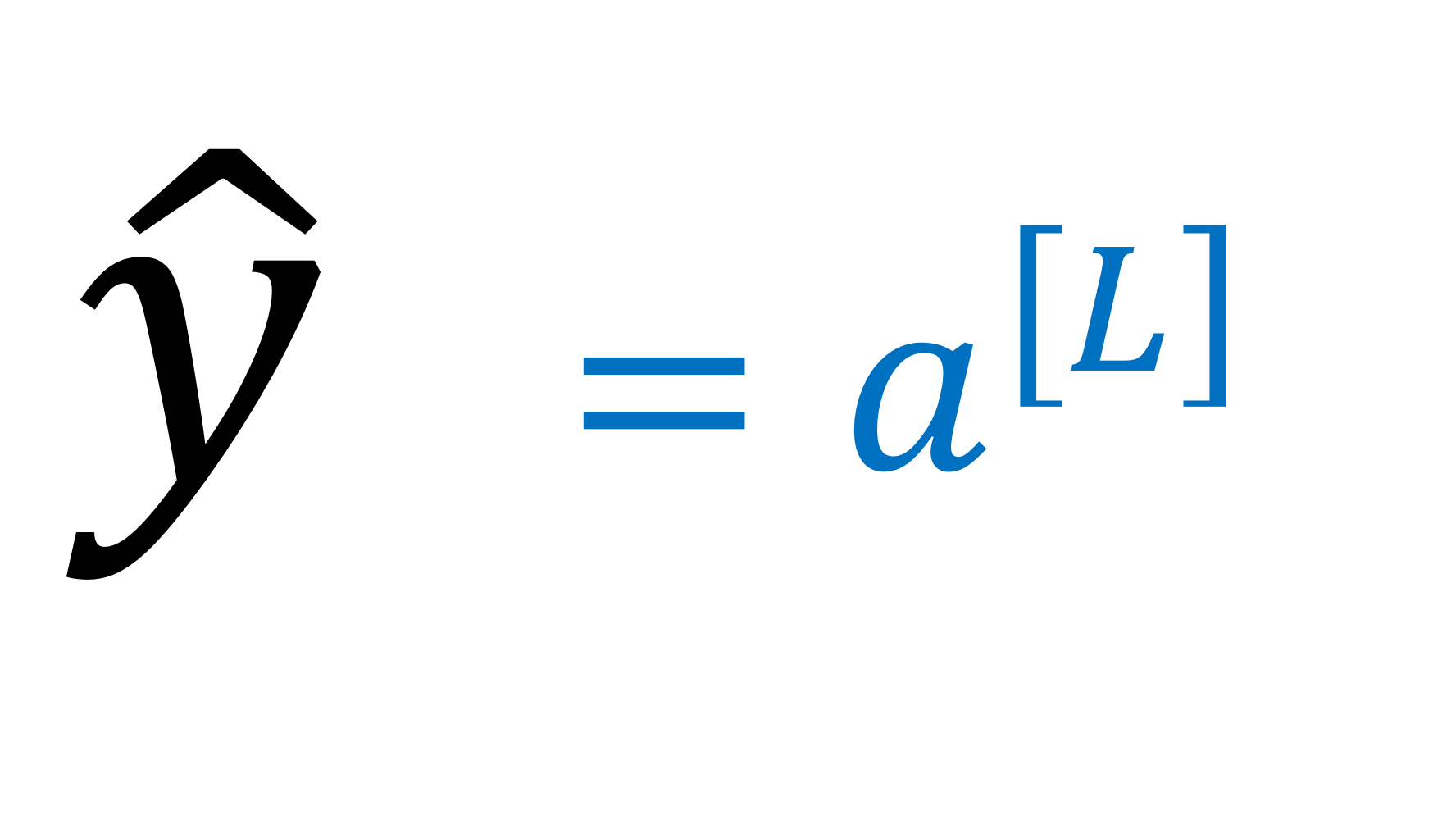
Forward propagation in deep neural network
Forward propagation in deep network
training data 하나에 대한 forward propagation
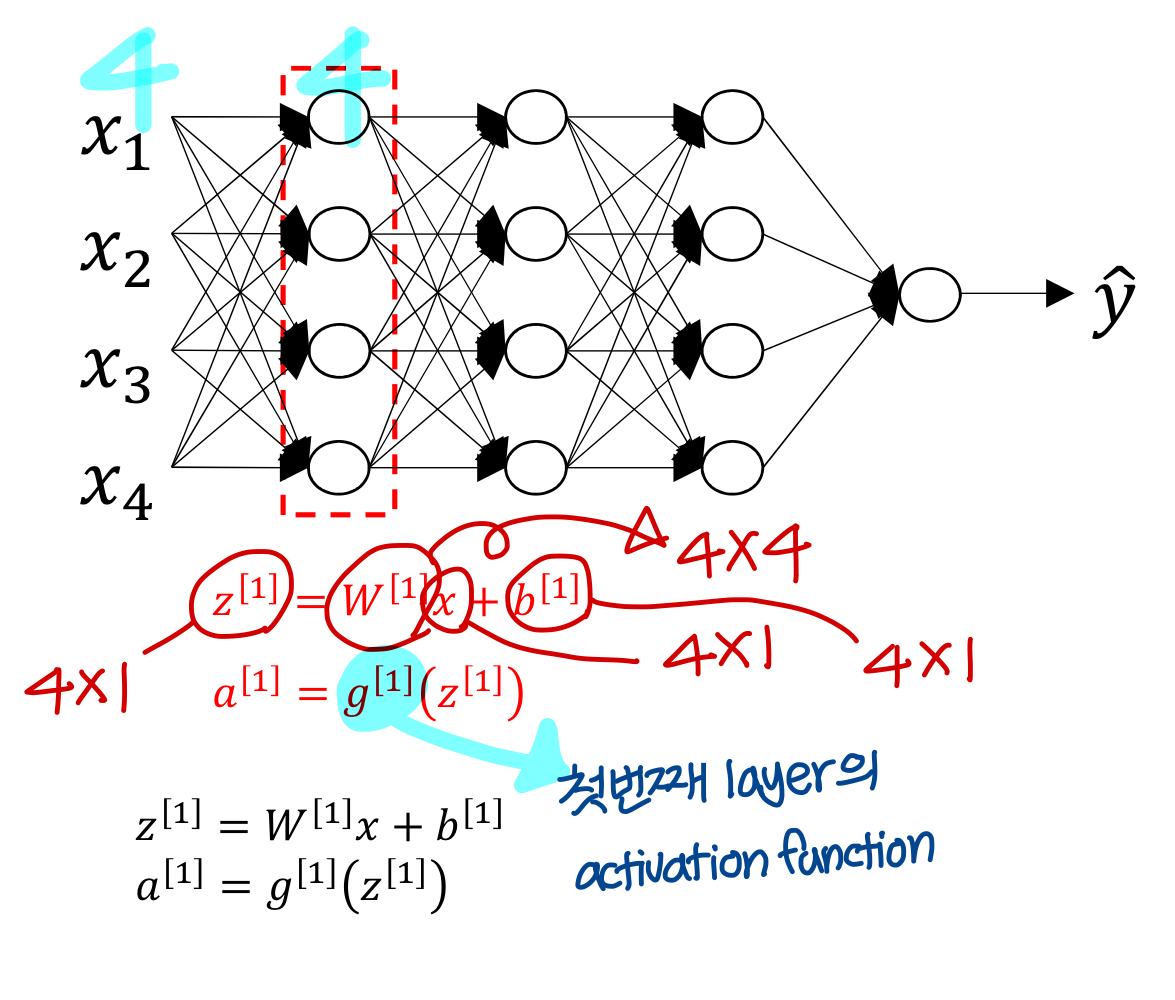

→ 그냥 이런식으로 우리가 알던대로 진행
→ 그리고 이건 training data 하나에 대해 진행한거
training data 여러개에 대한 forward propagation

→ 주의해야할게
activation function
weight
bias
는 training data 1개일 때랑 차이가 X
즐 알았는데 bias는 차이가 있음
근데 bias는 같은거 m개 가져다 붙인거
→ X, Z, A는 matrix로 바뀜
Parameters and
training data 하나에 대해 생각해보면
→ input 2차원이니까 라고 표현
matrix랑 vector 크기는 이럼
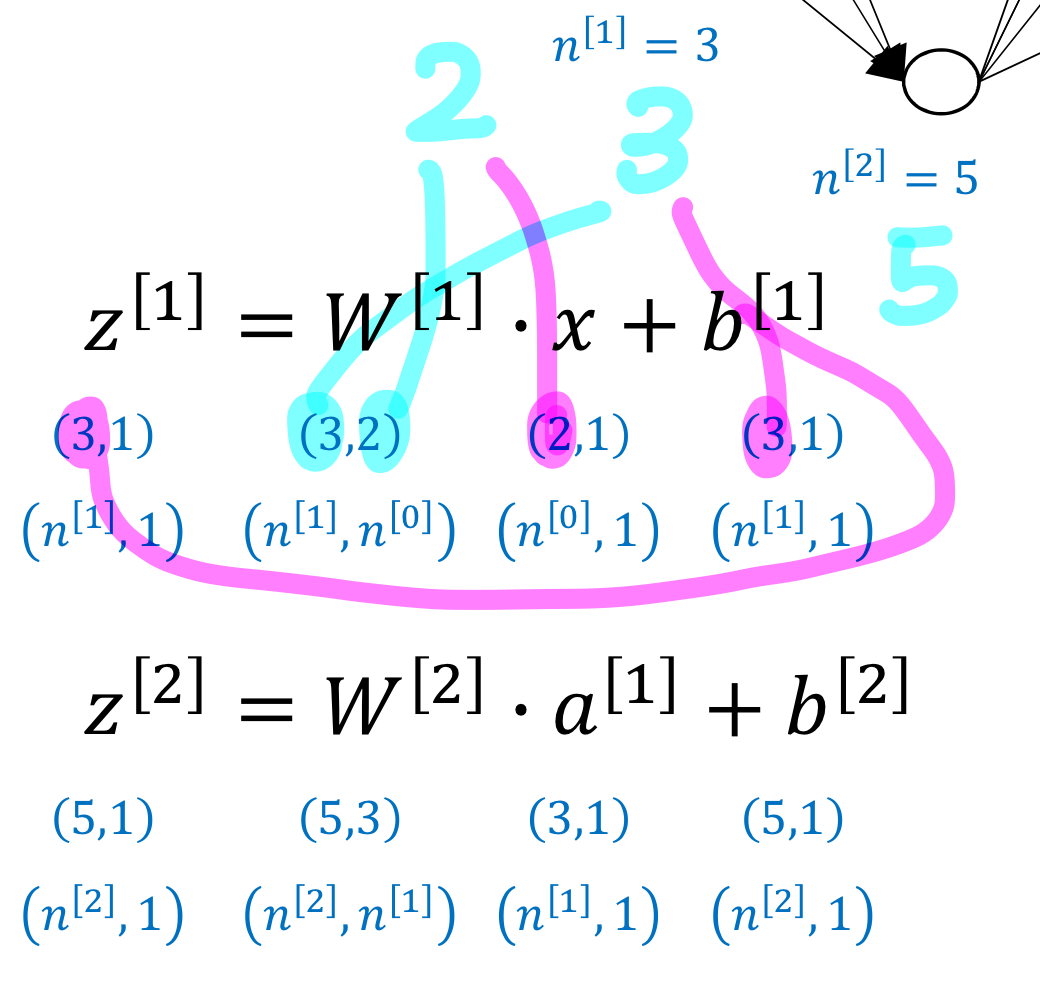


→ 랑 랑 똑같음
training data 여러개에 대해 생각해보면

Intuition about deep representation

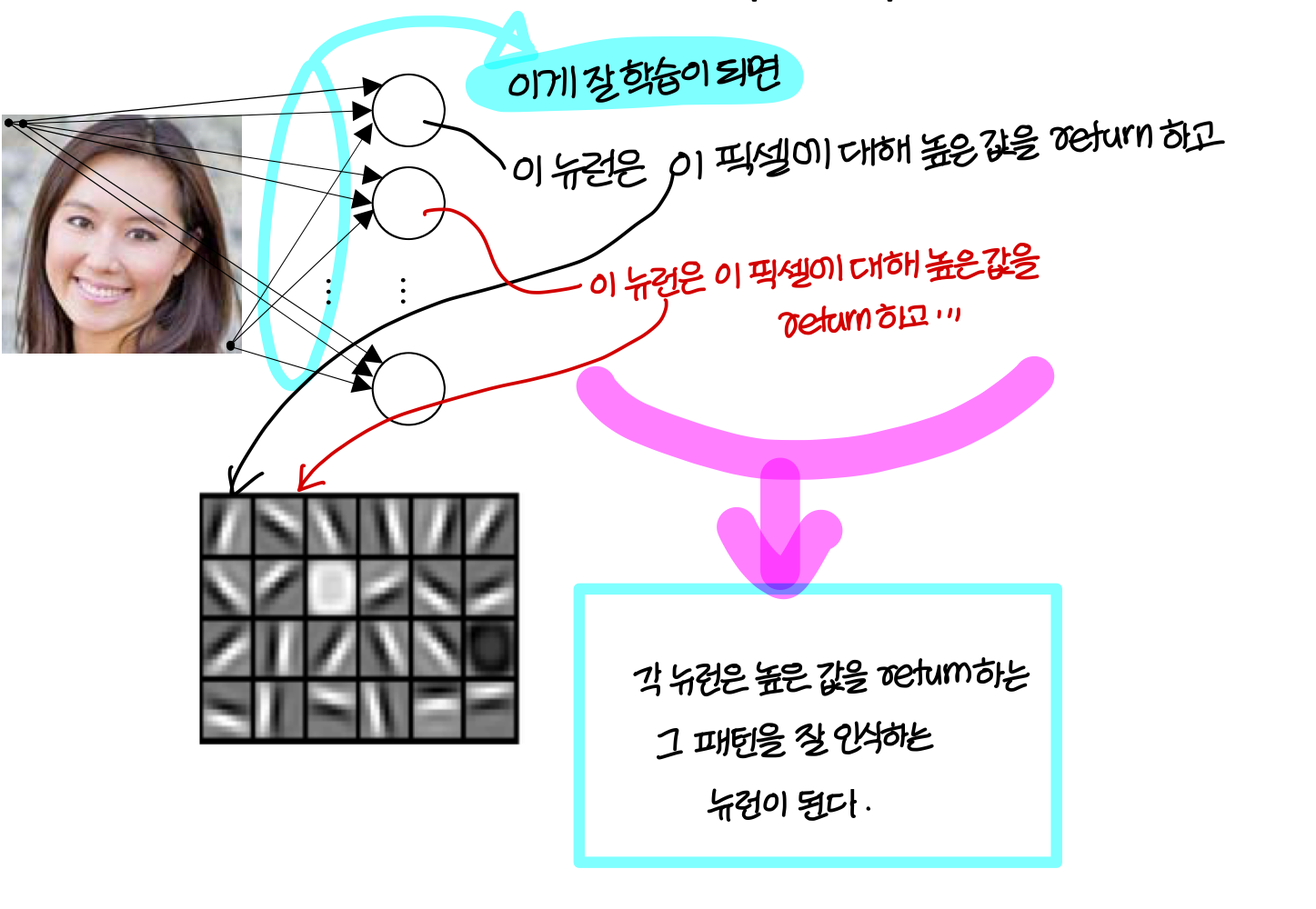
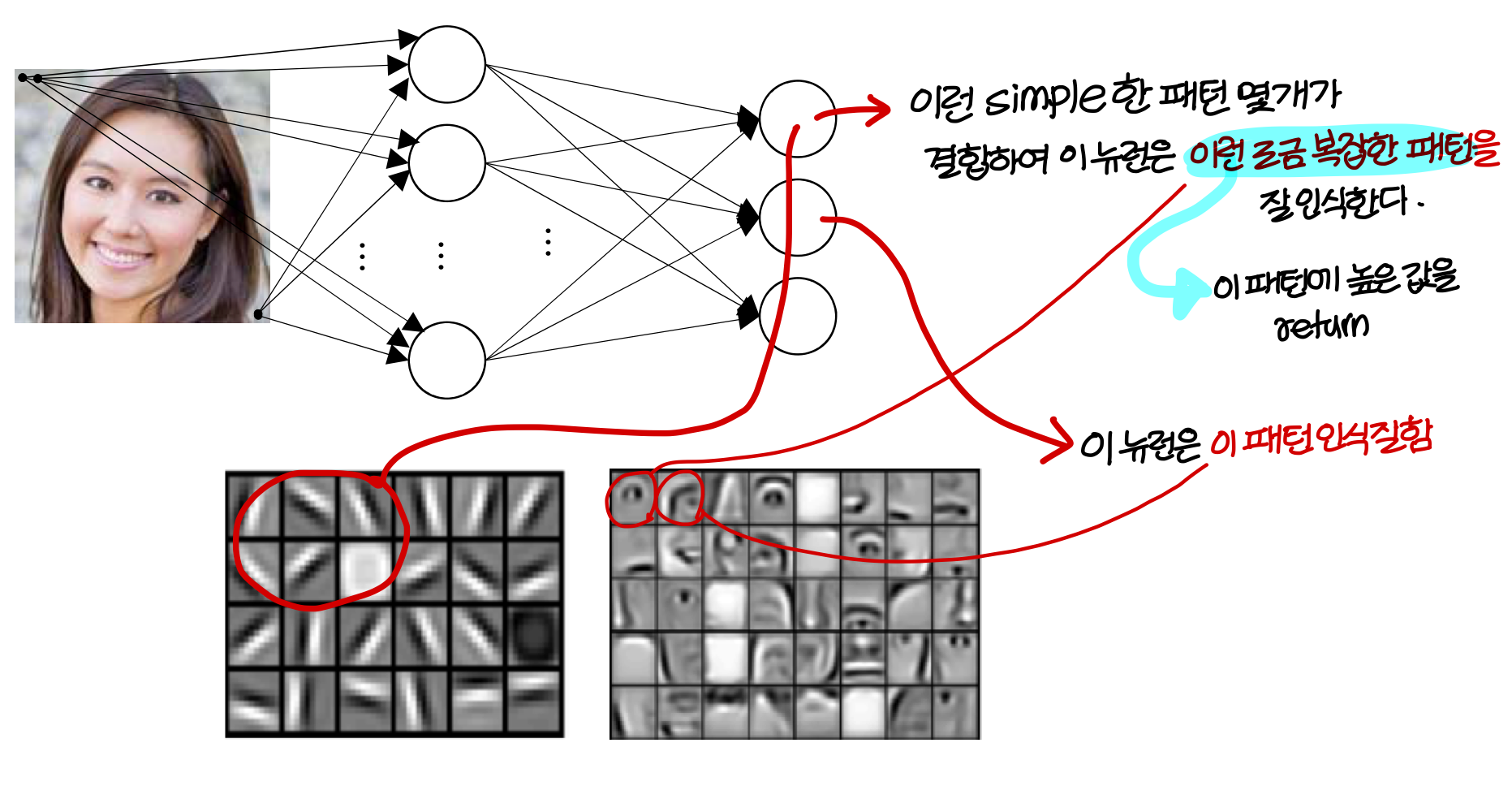
결론적으로...
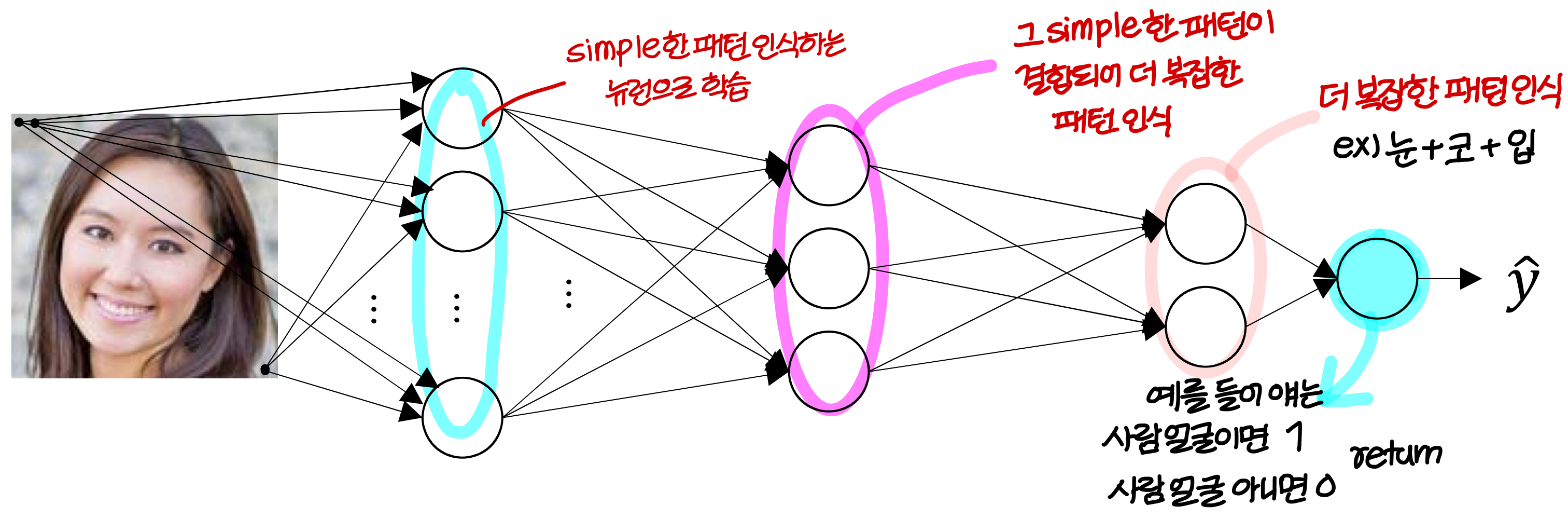
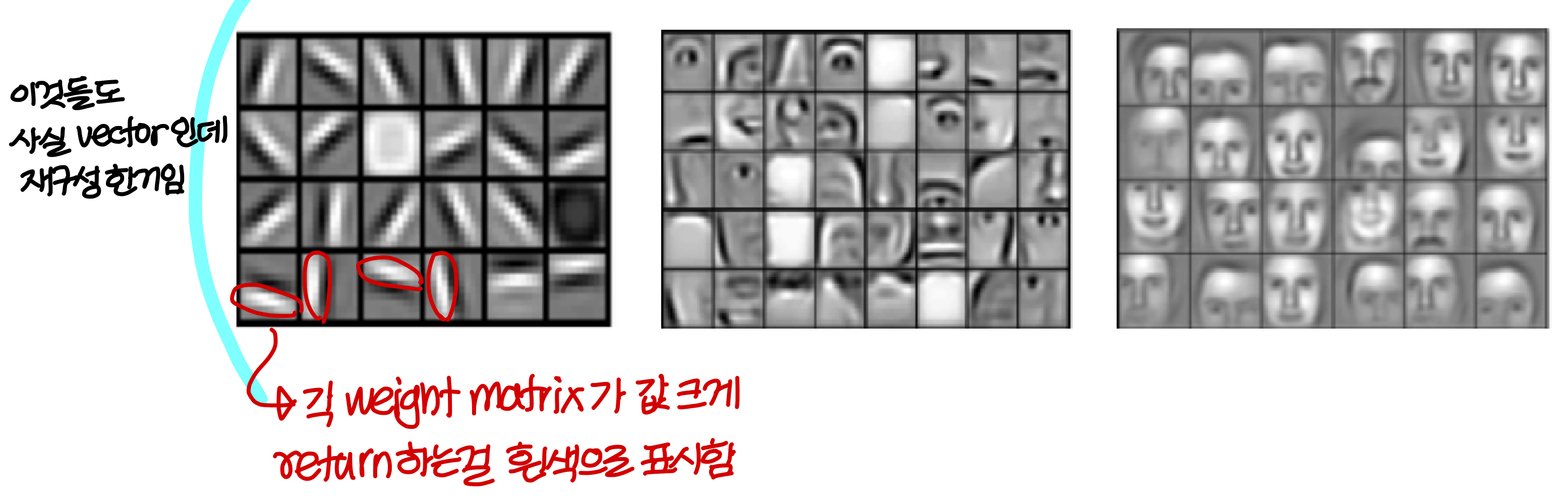
- deep neural network는 big data가 있을때 hand crafted filter를 만들 필요가 없음
→ 학습시키면 이런식으로 자동으로 만들어준다
→ 단, big data가 있을때만 가능하다
Circuit theory and deep learning → 왜 layer를 깊게 가져가야할까?

→ 이런식으로 XOR n개를 연산하고 싶다고 하자!
layer를 깊게 가져갈 경우
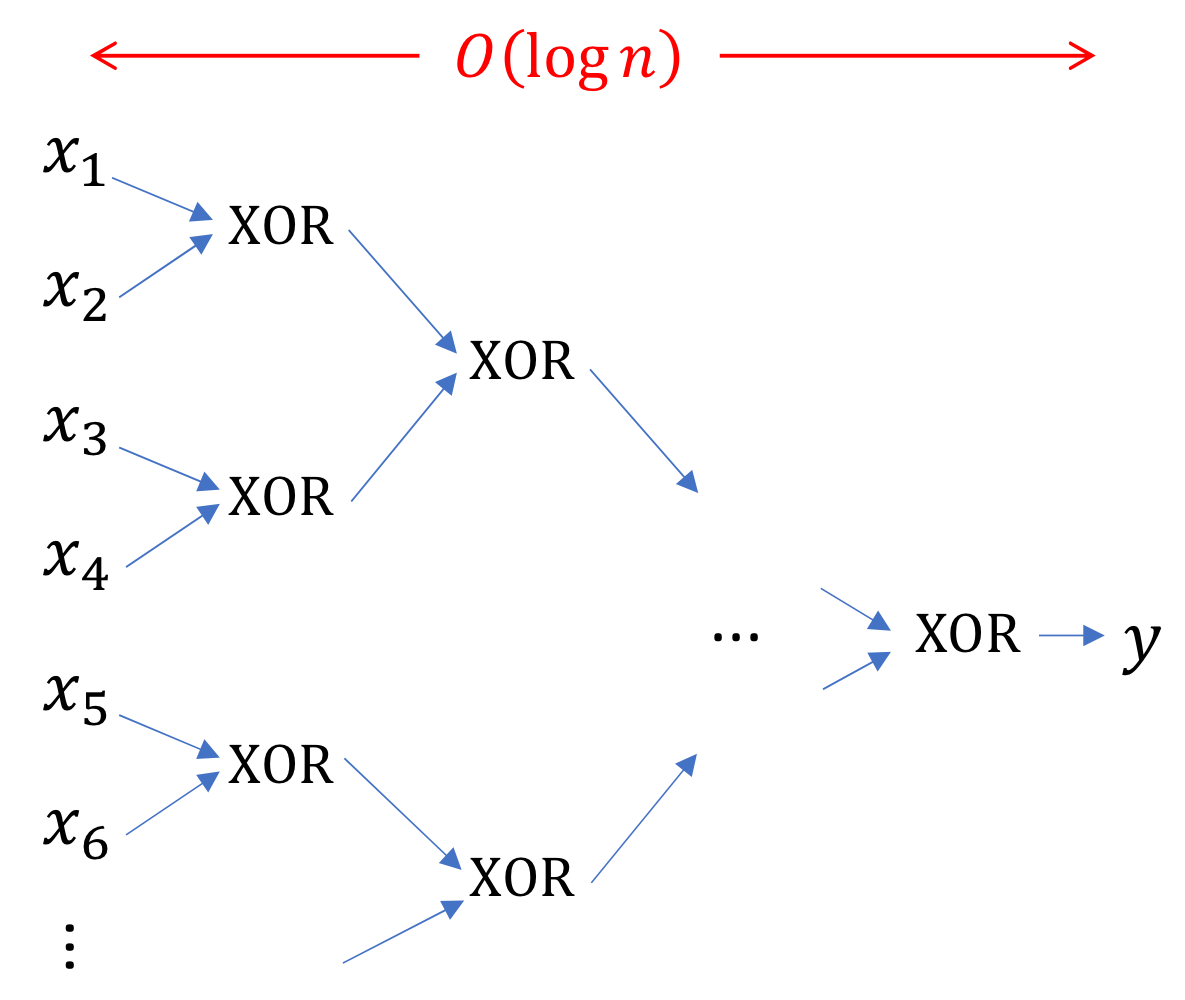
- layer 깊이
- 뉴런 개수 넉넉하게 잡아도
layer 얕게 가져갈 경우
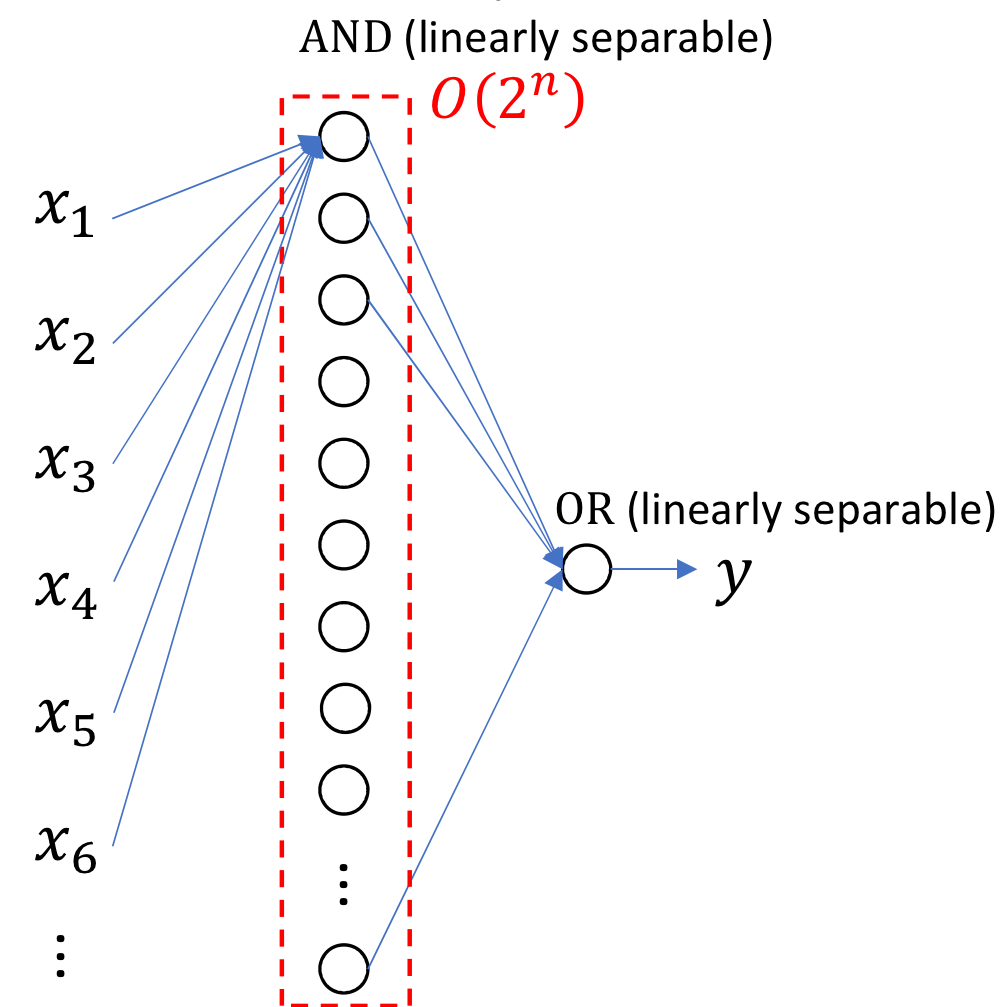
- 이런식으로 구현을 할 경우 간단한 문제인데도 뉴런의 개수가
exponential 하게 증가함
- 개의 뉴런을 사용해야함
Forward and backward functions → Caching을 하자!
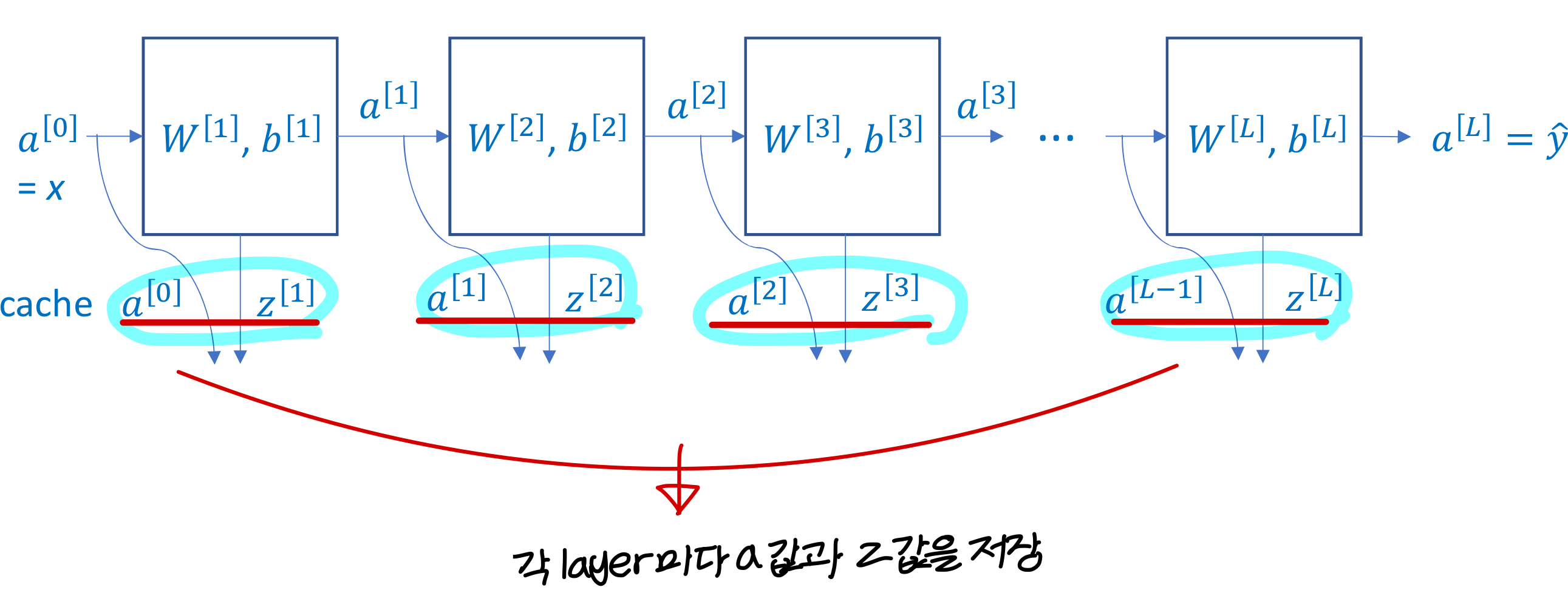
→ 그리고 back propagation 할 때 caching 된 값을 사용해 , , 값을 계산
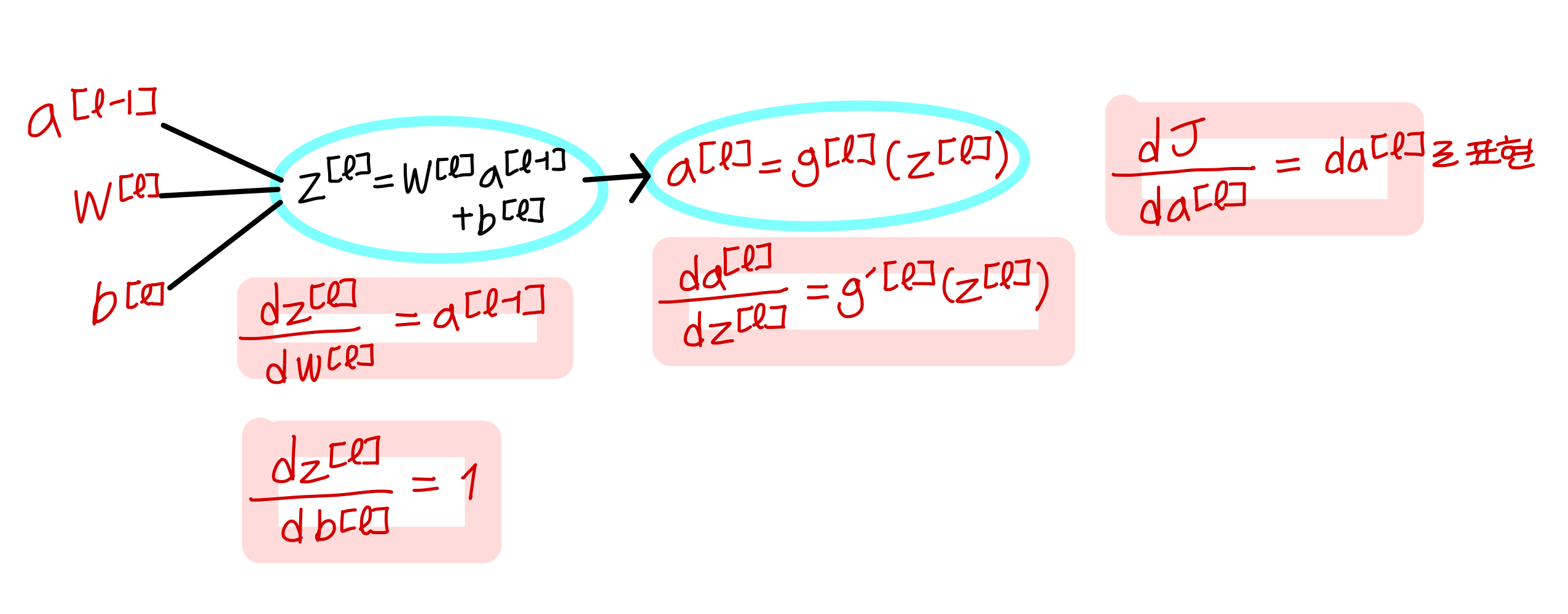
Forward propagation for layer l


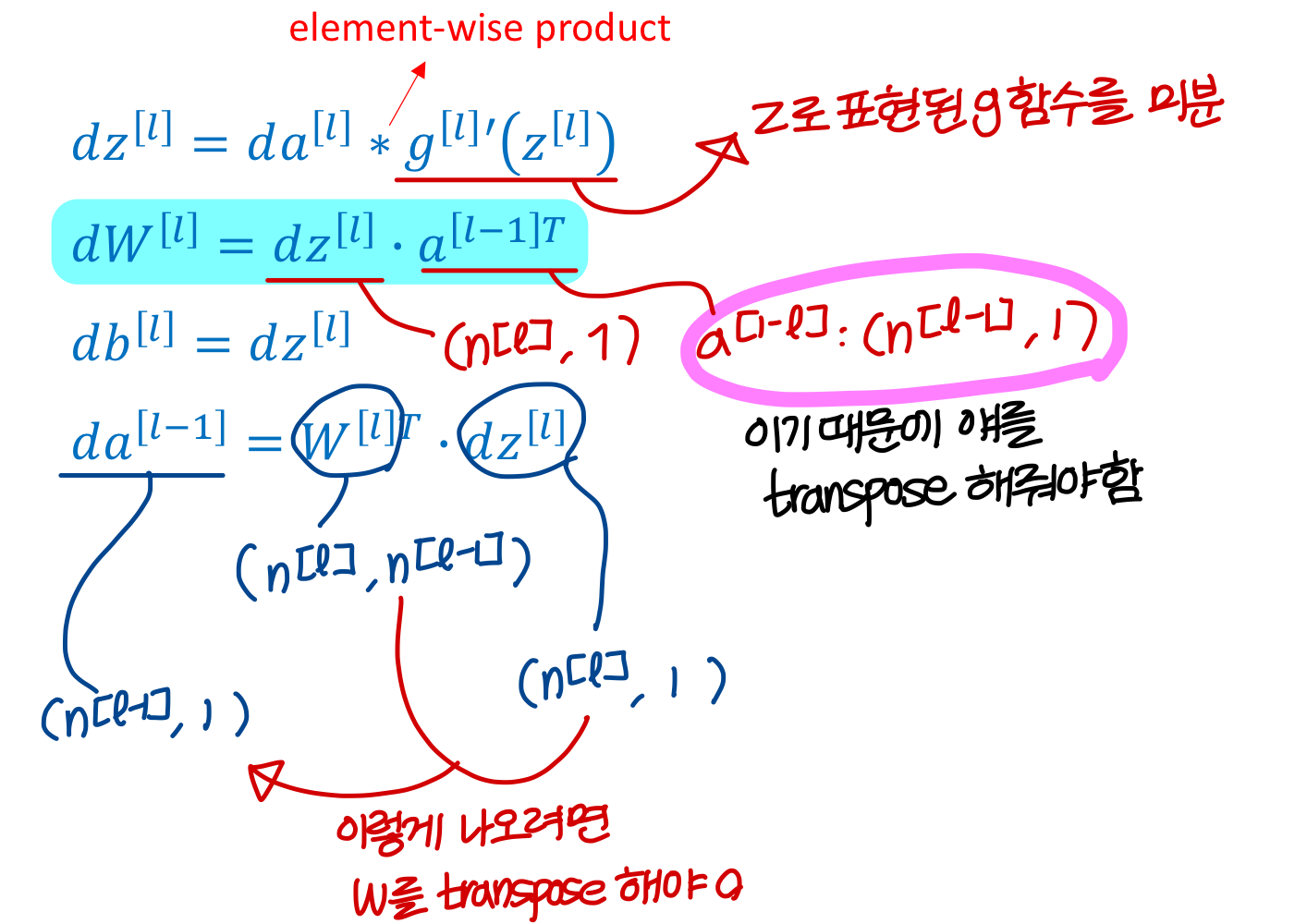
Back propagation for layer l

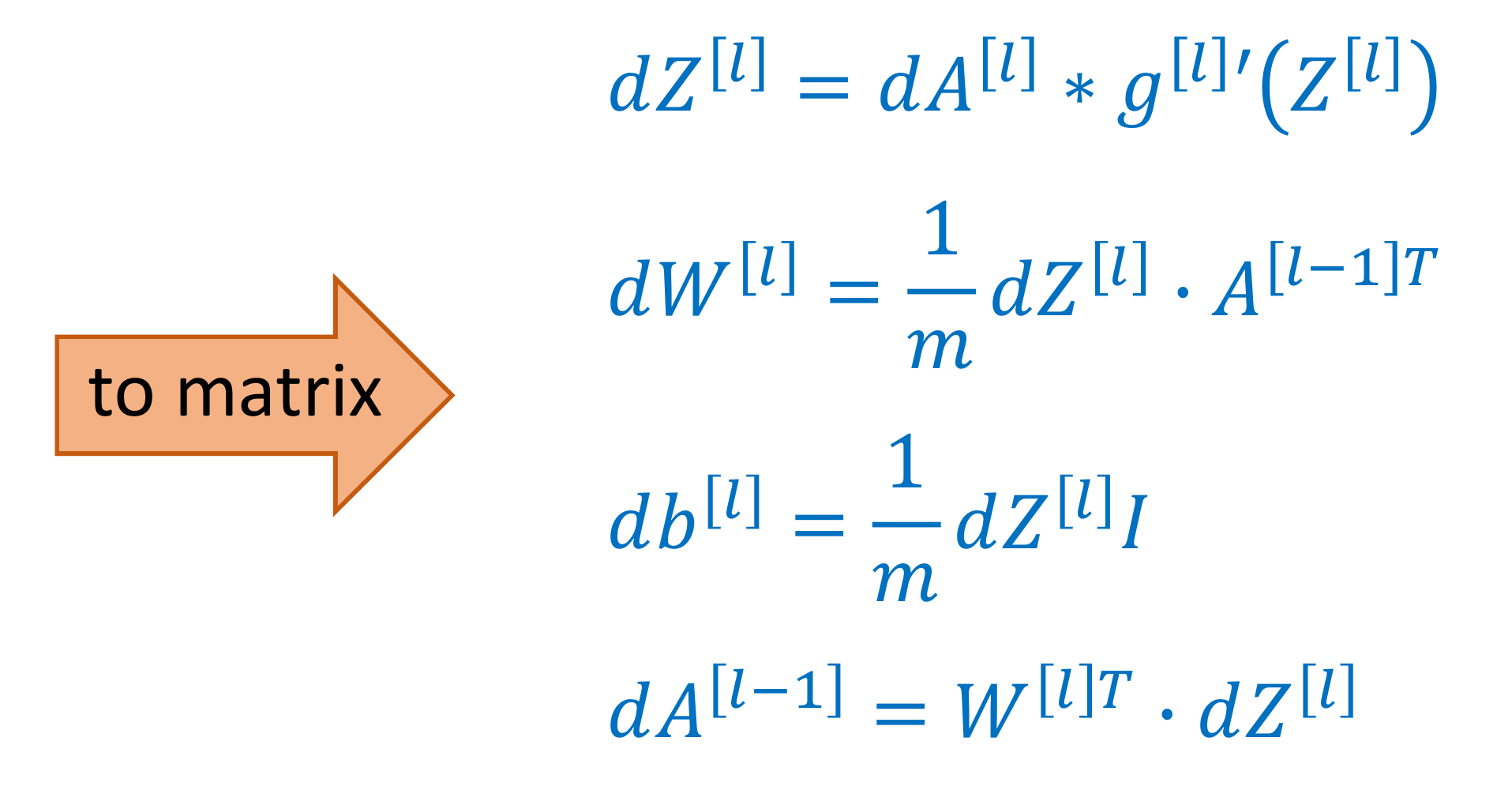
What are hyperparameter
Parameter
- 파라미터는 weight 값과 bias 값
- ex) ...
이건 학습되면서 자동으로 setting이 된다.
Hyperparameter
- neural network의 성능을 위해서는 parameter 뿐만 아니라 hyperparameters도 organize 해야한다
- parameter를 제외한 각종것들을 전부 hyperparameter라고 한다
- learning rate α
- iteration 몇번할지 (training data 전부 다 돌면 iteration 1번)
- hidden layer 개수
- hidden layer의 뉴런 개수 hidden units , , ...
- activation function 뭐쓸지 (ReLU, tanh, sigmoid...)
→ 이런걸 잘 선택하는 만병통치약은 없음
→ 케바케임. training data의 양의 영향도 받고...
이건 자동으로 setting이 안되고, neural net 디자이너가 정함. 그래서 사람이 필요한거임
Applied deep learning is a very empirical process
- hyper parameter 정하는 과정
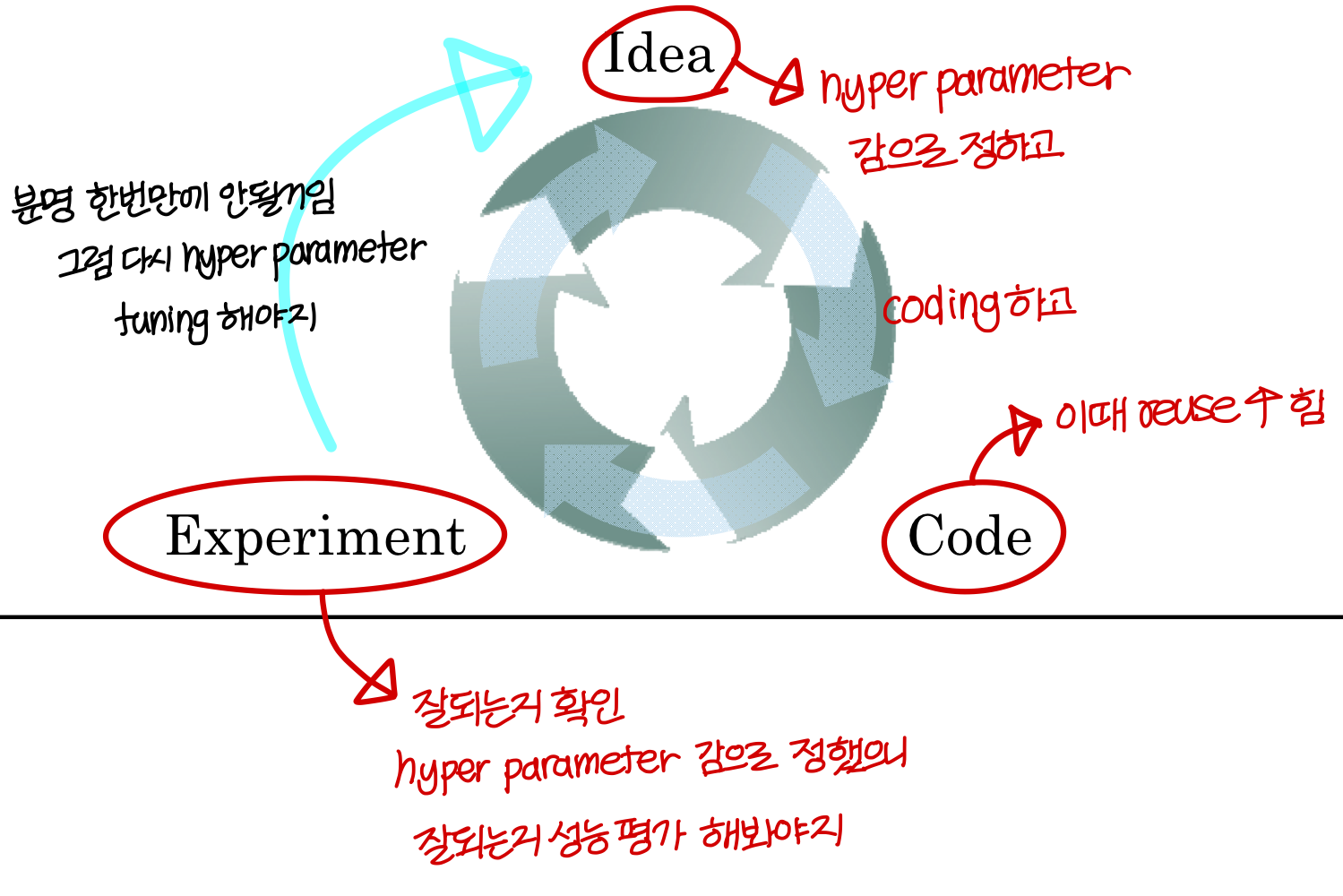
→ 이 과정을 만족스러운 결과가 나올 때까지 반복함
What does this have to do with the brain
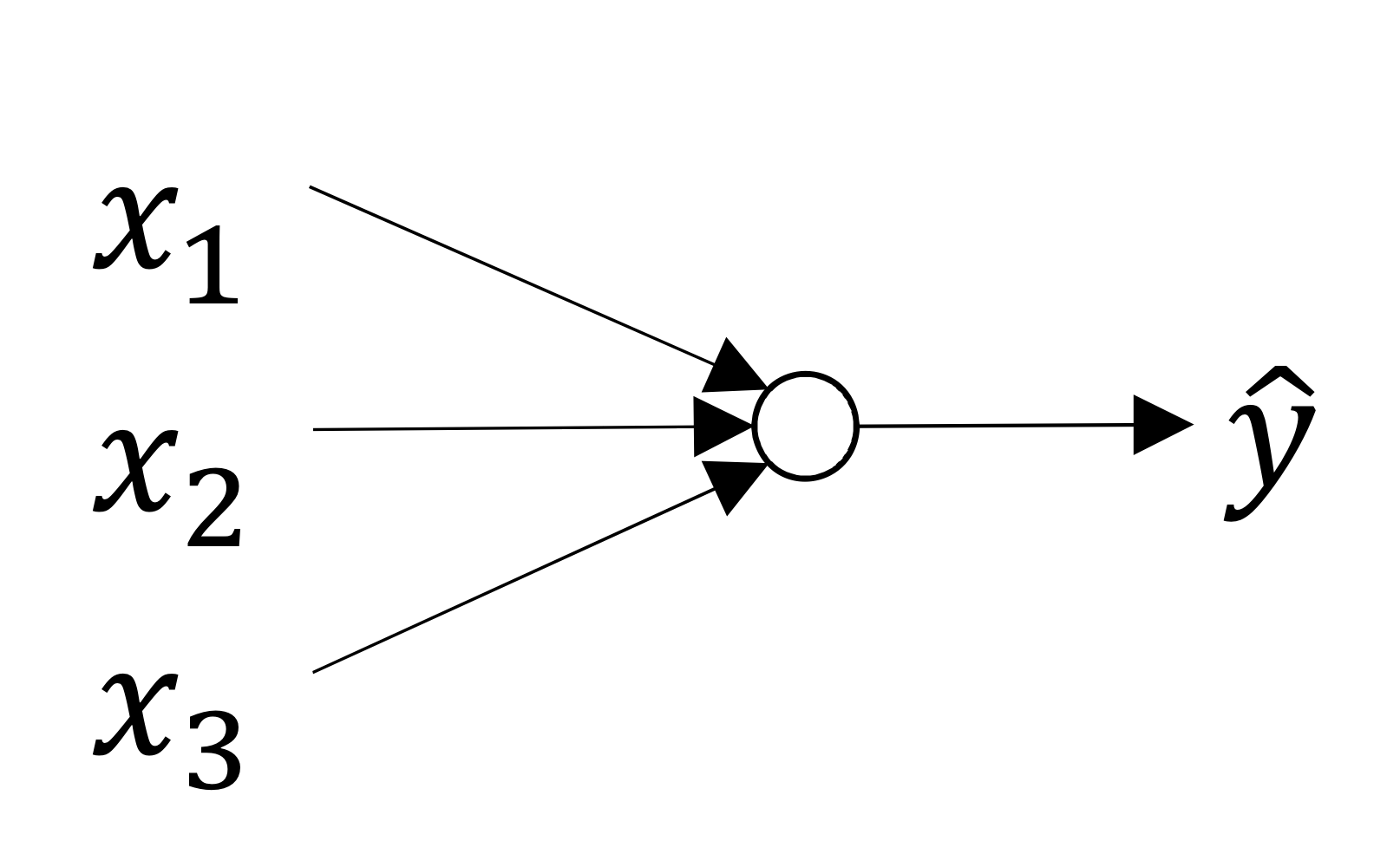
→ 얘는 weight sum 계산하고 activation function 적용하고 이러는거..

→ 얘는 에너지 축적되다가가 threshold 넘으면 푱 튀어나감
→ 이와 유사하게 동작하는 network가 “spiking neural net”
⇒ 이렇게 동작하는 방식이 조금 다르다!
Uploaded by N2T