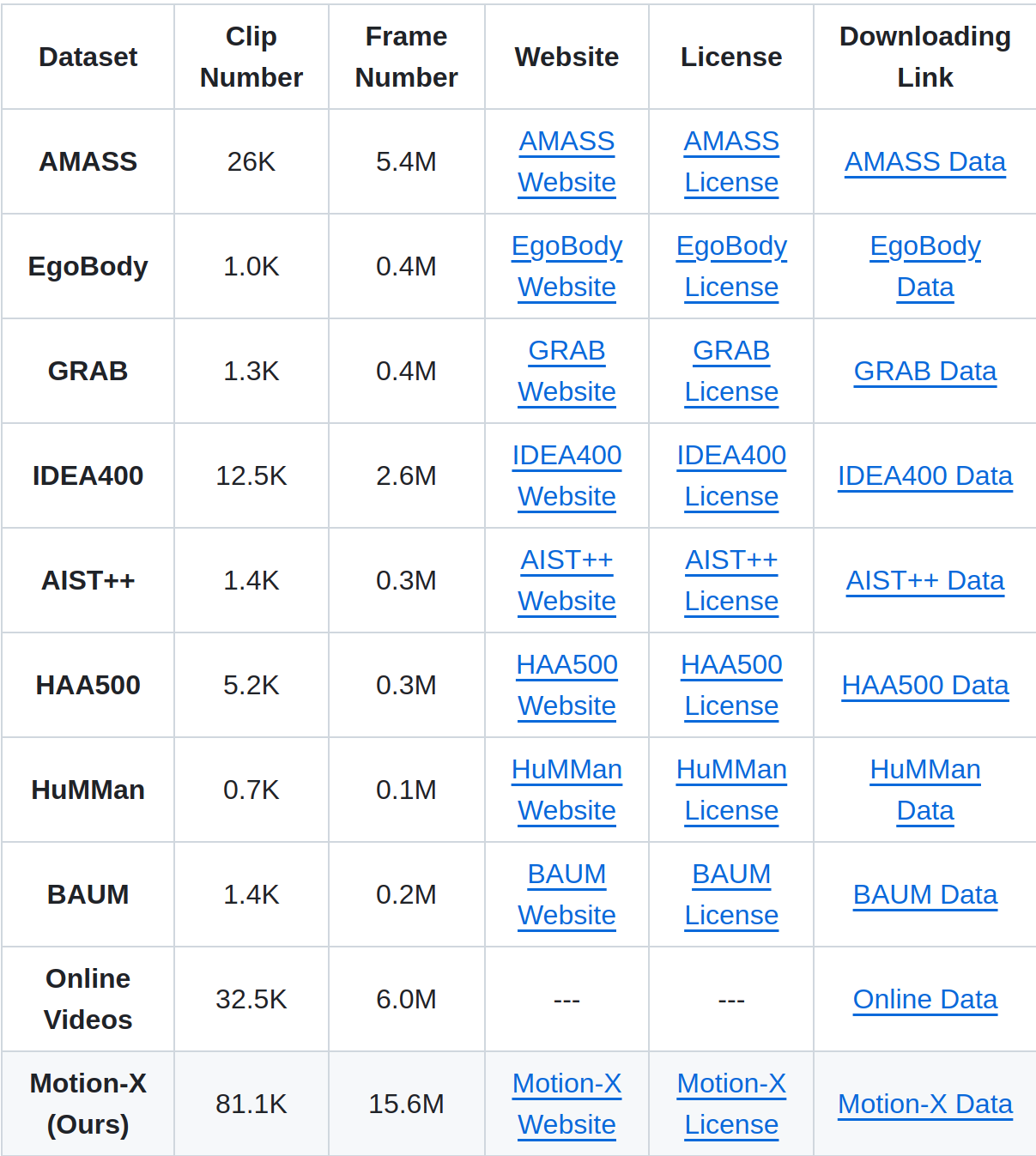
https://github.com/IDEA-Research/Motion-X#dataset-download 표정과 손동작까지 포함하는 데이터를 만들었다는 말 같다.) Motion-X dataset에서는 모두 같은 format(SMPL-X)을 사용하여 data를 표현하고 있다. 위의 8가지 데이터셋 + Online videos을 모두 사용하여 dataset을 구축하였다보니 확실해 Motion-X의 dataset 양이 방대한 것을 확인할 수 있다. 참고로 원본 Mocap dataset(AMASS, GRAB, EgoBody)와 원본 RGB 비디오는 제공하지 않는다. 또한 Mocap subset에 대해서는 text labels와 facial expression만 제공하며 Non-Mocap Subset에 대해서는 ..