
728x90
728x90
Paradigm shift of computing Model
80, 90년대) 워크스테이션이나 고정된 서버가 있고 client로 PC가 있음
2000년대) peer-to-peer로 넘어감
Client/Server 아키텍쳐
- 서버는 powerful, reliable 해야함
- 클라이언트는 최소한의 리소스만 가지고 있어야함
- ex) WWW(Http), FTP, Web service(http 말하는게 아니라 별도의 웹서비스가 있었음. 프로토콜도 별도로 soup라는게 있었음)
Client/Server Limitation
- 모든걸 서버가 처리하다보니 scalability 측면에서 제한이 무조건 있게 된다.물리적으로 communication line의 용량 제한이 있을수밖에 없음. request를 모두 같은 지점에서 처리하다보니 병목현상이 생길 수밖에 없고
- single point of failure. 서버가 failure 되면 전체 서비스가 다운된다.
- unused resources at the network edge. client도 상당한 power의 리소스를 가지는데 이걸 사용하지 않음
Peer to Peer Model
- client/server 구조에서는 client와 server의 역할이 달랐는데 여기서는 모두 같은 역할
- p2p에서 노드는 client인 동시에 server로서 동작한다 (data를 provide하기도 하고 consume하기도 하고)
- 장점
- scalability가 있다 → 노드가 늘어난다는건 client가 늘어나는 동시에 server도 늘어나는 것이니까
- 리소스를 효과적으로 활용할 수 있다 → client의 버려지던 리소스 자원을 이제 다 활용한다
- reliability → 원래 서버가 다운되면 전체 다운되는 거였는데 이제 한명이 담당하는 stoarge만큼만 사용불가
- geographic distribution → peer 가 여기저기에 흩어져있기 때문에 가장 가까운 peer에게 서비스를 제공받으면 되니까 지리적인 측면에서 장점이 있음
- 원래 서버에게 과도한 부담이 주어졌는데 이제 그러지 않음
P2P protocol classification
- centralized인지 decentralized인지, hybrid인지에 따라 p2p protocol이 나누어진다.
- → indexing server의 유무로 판단한다.
- → indexing server는 파일 인덱스를 가지고 있는 서버다 ex) skype 서버
- overlay network의 topology에 따라 structured인지 unstructred인지 나눌수 있다
- → file들이 흩어져있는데 어떤 노드가 어떤 파일을 저장할지 논리적인 프로토콜에 의해 결정되면 structured
- → 그게 아니라면 unstructured
- → structured network는 decentralized일수밖에 없음. centralized인게 말이 안된다. centralized는 파일을 흩뿌리고 빨리 찾는거니까

Napster(Centralized + Unstructured Networks)
- indexing 서버가 shut down되면서 하룻밤 사이에 날아가버린 p2p 프로토콜
- 사용자들 music 파일을 교환하는 상황
- 먼저 indexing 서버에 나 이런 노래 있다고 publish함 (indexing server에 접속해서 indexing server가 보유하고 있는 database에 insert하면 publish됨)
- 이제 타인이 가진 파일을 search해야하는데, A라는 파일을 갖고 싶으면 indexing server에 접속해서 db query를 수행함. 그럼 누가 가지고 있는지 ip가 나오고 그 ip를 fetch함
💡 누가 어떤 파일을 가지고 있는지 찾는건 CS 형식으로 되어있지만 파일 교환은 p2p 방식으로 이루어짐. 즉, centralized + unstructred network(hybrid)
- 장점
- 프로토콜이 간단
- search cost가 낮다 (O(1))
- p2p network를 control하는 것이 용이하다.
- 단점
- 서버에 부담이 많이 감. 서버는 O(N) state를 유지해야함
- server가 single point of failure이기 때문에 해당 서버가 다운되면 전체가 다운됨
Gnutella(decentralized + unstructured network)
- 얘는 하룻밤 사이에 다운되는 것이 불가능한 decentralized network
- 누텔라 프로토콜에 의해 연결된 network topology
- 각 노드들이 파일을 가지고 있고, A라는 파일을 찾고 있는 상황
- 여기는 인덱싱 서버가 없으니까 자신의 이웃 노드에 query를 날림
- 받은 이웃들은 나머지 이웃들에게 query를 전달하고… 또 전달하고
- 이런식으로 query가 propagate됨
- A라는 파일을 가지고 있는 노드가 trace back해서 reply를 보내줌
- reply 받은 node도 trace back해서 reply 또 보내줌
- 그럼 결국 query 날린 node는 두 개의 reply를 받게 되는데 여기서 마음에 드는 노드에 접속
- 장점
- indexing 서버를 유지해야하는 부담이 없음
- 단점)
- search cost가 O(n)임
- 노드가 자주 사라지기 때문에 네트워크가 unstable하다
Hybrid P2P Systems:FastTrack/KaZaA
- hybrid에선 모두가 동등한게 아니라 등급이 있다. peer가 있고 ultra-peer가 있음.
- 즉 mini indexing server를 유지하는거
- 아까 centralized network에서 봤던건 global indexing server이고, 여기는 local indexing server
KazaA(Hhybrid + Unstructured)
- ultra peer) local top임. 특정 지역에 존재한 peer들의 indexing network
- ultra peer들끼리 p2p로 연결된다
<동작방식>
- hybrid라 centralized + decentralized 방식으로 동작함
- search가 일어나면 자신의 indexing local server에 기록함
- indexing local server 상에서 파일을 가지고 있는 노드가 자기 자식으로 있으면 search가 끝남(centralized 방식)
- 그게 아니라면 다른 indexing server를 뒤져야함. 이때 query를 broadcast하게 됨(uncentralized 방식)
→ 이렇게 하면, 많이 찾는 파일들은 local indexing server에서 해결이 될거고, 잘 사용하는 파일들만 다른 서버에서 가져옴.
DHT: Distributed Hash Table
- 기존의 network
- centralized의 경우
- 디렉토리 사이즈) O(n)
- query(number of hop) ) O(1)
- Decentralized의 경우
- 디렉토리 사이즈) O(1)
- query(number of hop) ) O(n)
- centralized의 경우
- 우리가 원하는건
- 노드당 O(log(n))의 state를 가지고
- look up마다 O(log(n))의 메세지를 가지고
- 노드가 있으면 노드의 ip x가 있고, 파일이 있으면 파일의 이름 y가 있음
- hash function이 있고 file y를 hash 하면 H(y)
- 노드 x를 hash하면 H(x)
→ 즉, 노드의 아이디나 파일의 이름을 hashing할 때 똑같은 hash space 상에서 hashing함
→ 노드 hash한건지, file hash한건지 결과만 보고 판단할 수 없음
💡 그리고 p2p network 상에서 위치 정해질때, hashing value에 기반하여 정해진 규칙에 따라 정해진다
(위치가 랜덤하게 정해지는 것이 아니라 정해진 프로토콜에 의해서 규칙에 따라 정해지는거)
(정해진 규칙에 따라 위치가 정해져있기 때문에 규칙만 따라가면 cloding을 하지 않고도 위치를 찾을 수 있음)
💡 규칙: hash key가 가장 가까운(자기 보다 큰 값을 가진 애들 중에) peer에 object를 저장

- 처음에 두 개의 노드가 p2p network에 조인함(중간꺼 업는 상태)
- 이후 제일 왼쪽 data가 저장되는데 hash key가 가장 가까운 제일 왼쪽 node에 저장됨
- 이후 두번째 data(제일 오른쪽꺼)가 가장 가까운 노드에 저장되니까 가장 오른쪽 node에 저장됨
- 이후 세번째 object가 저장되는데 규칙에 따라 가장 오른쪽 node에 저장됨
- 그러다가 세번째 노드가 조인함(중간거)
- 그럼 제일 마지막에 추가된 object data가 제일 오른쪽에 저장되는건 규칙 위반이므로
- 중간 노드로 오브젝트가 옮겨짐
(위에꺼 읽을 필요없고… 요약하면)
💡 규칙이 잘 유지되어야 client가 규칙에 따라 search할 수 있으므로, 규칙에 위반되지 않도록 node가 추가되면 파일 옮겨주는 작업이 필요함
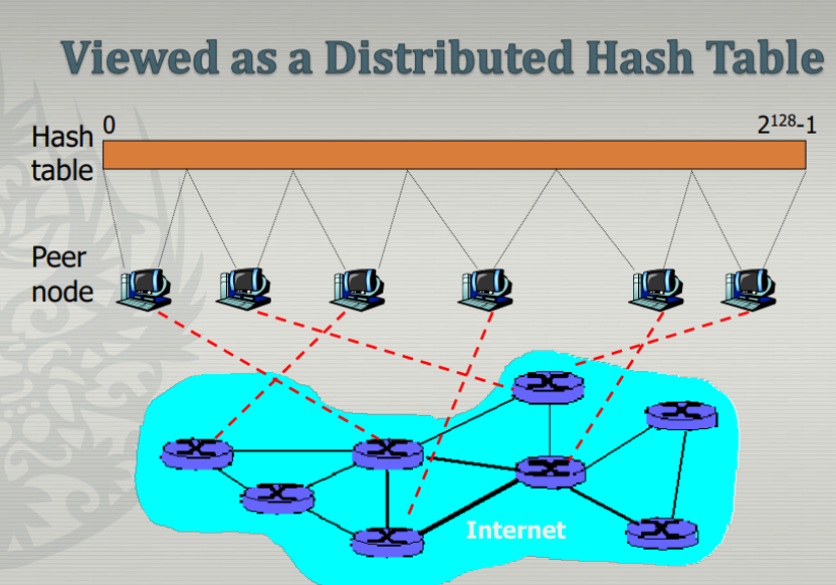
→ hash table은 원래 Single machine에 저장되는데 DHT에서는 여러 테이블에 나눠서 저장이 된다
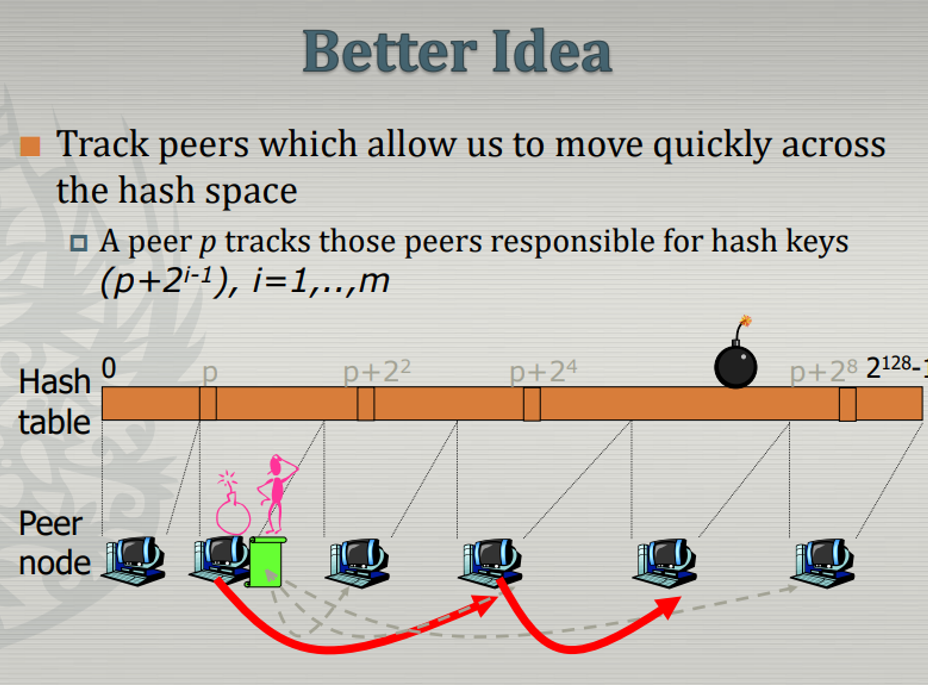
원하는 hash table 부분을 가지고 있는 node 어떻게 찾지?
→ linear보다 binary search로 하면 더 효율적
→ 개별 peer는 hash table에 대한 shortcut(주요거점에 대한) 정보도 가지고 있다
Chord Protocol (Decentralized + Structured), DHT 방식으로 동작하는 프로토콜
- Chord Protocol은 DHT 방식의 프로토콜임
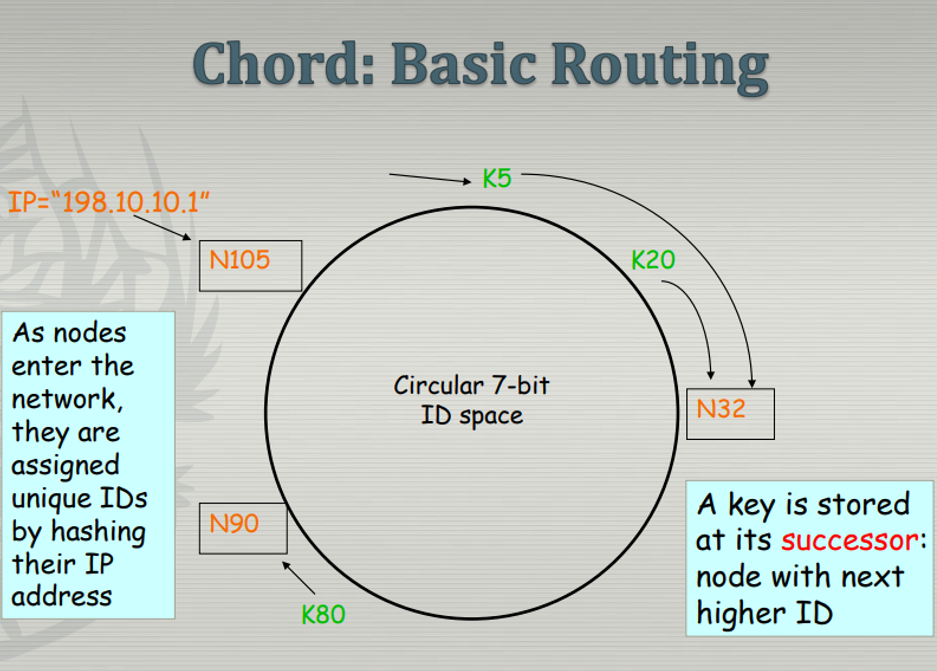
→ successor node) 자신의 다음 ID를 가지 노드
<동작방식>
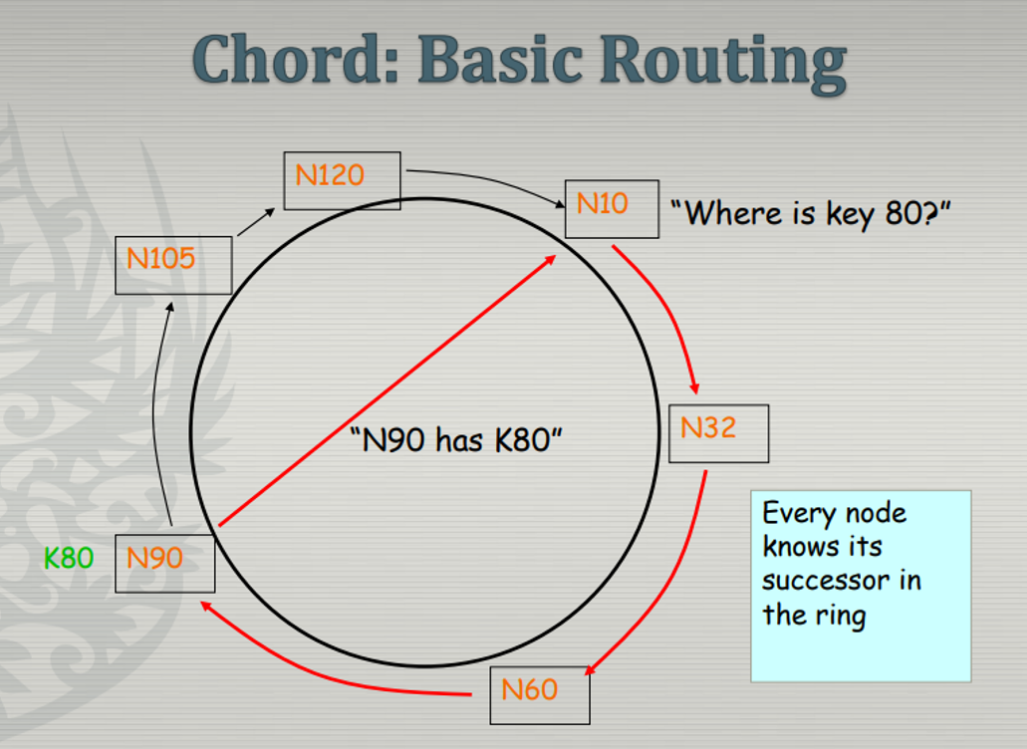
- 10번 노드에 80번의 키를 찾는 query가 들어옴
- 자신의 데이터베이스 봤는데 없음. 없으니까 자신의 sucessor 노드인 32번 노드에 pass
- 얘도 없으니까 90번에 pass. 90번에 80번 키에 대한 정보가 있음
- 얘가 파일 10번에 넘겨주면 10번이 query에 대한 reply 해줌
→ 이렇게 되면 performance가 O(n)
→ 이것으로 만족 못하니까까 shortcut table을 가지고 있음
Chord: Finger-Table Routing
- 위의 방식만 사용하면 계속해서 다음 호스트에게 물어봐야하므로 시간이 오래걸린다
- 이러한 단점을 개선하기 위해서 shortcut 정보를 담고 있는 finger table를 만들어서 관리한다
- finger table은 더 넓은 범위의 노드들을 어떤호 스트가 담당하고 있는지 더 쉽게 파악할 수 있게 해준다

728x90
728x90
'수업정리 > 분산컴퓨팅' 카테고리의 다른 글
| 수업정리 6) Kubernetes in action (0) | 2023.10.29 |
|---|