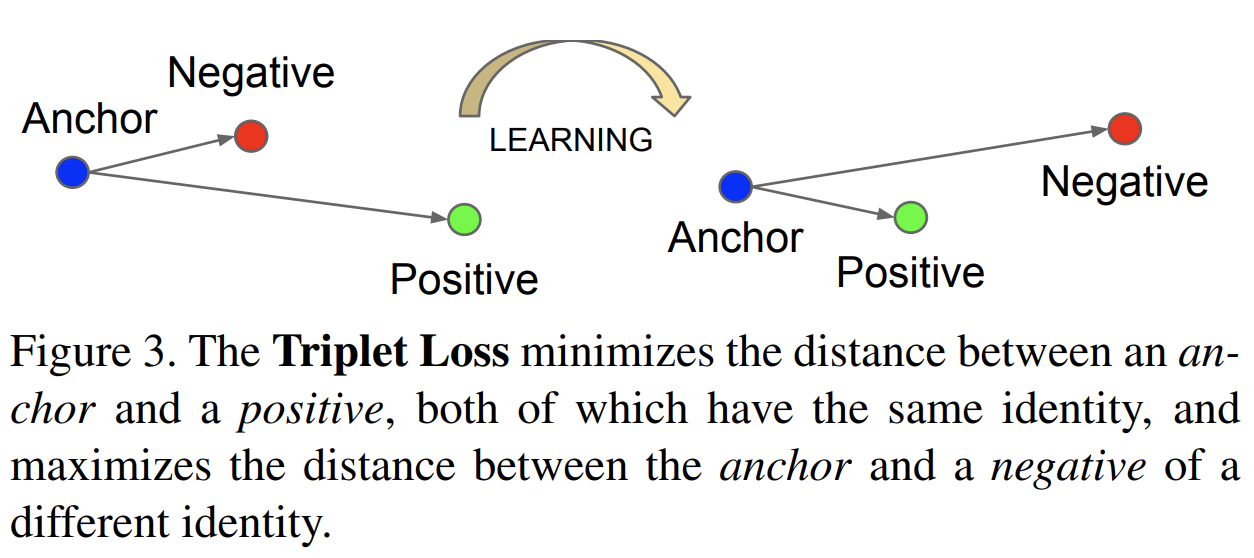
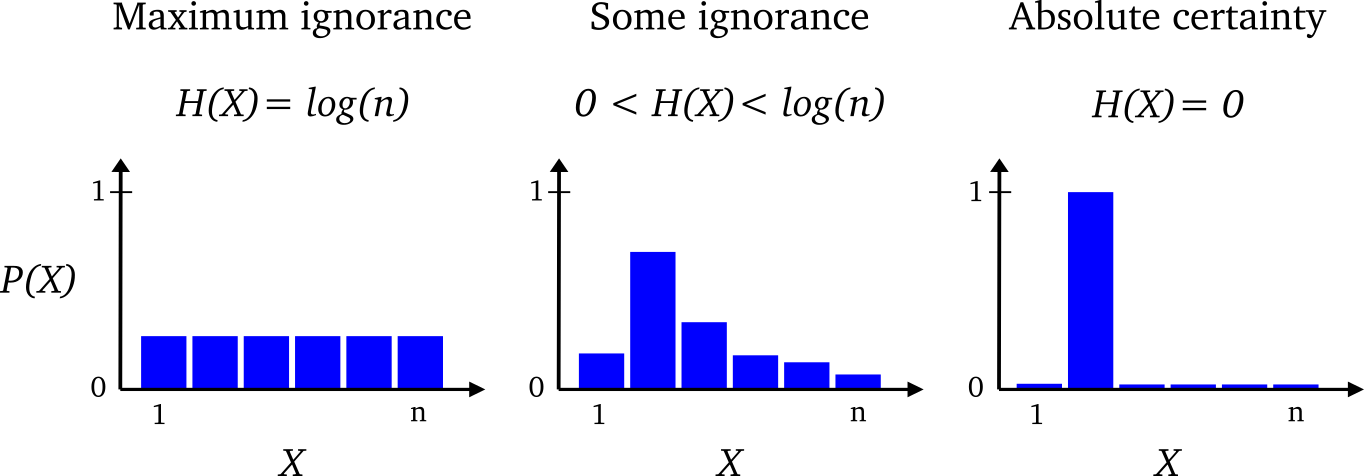
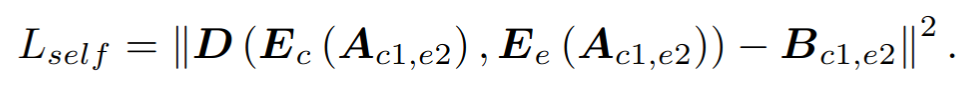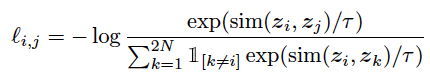VAE에 대해선 다들 알고 있을 것이다. 내가 작성했던 아래의 포스트에서도 VAE에 대한 설명을 제공하고 있다.https://chickencat-jjanga.tistory.com/3 VAE 설명들어가기에 앞서 * AE와 VAE는 이름이 유사하지만, 수학적으로는 아무런 관련이 없음 * VAE는 Generative model임! * Generative model? training data가 주어졌을 때 이 data가 sampling 된 분포와 같은 분포에서 새로chickencat-jjanga.tistory.comVAE를 간단하게 복습해보자면, VAE(Variational Autoencoder)는 데이터를 잠재 공간(latent space)으로 압축한 후 다시 복원하는 방법론을 제공한다. VAE는 잠재 공간을..