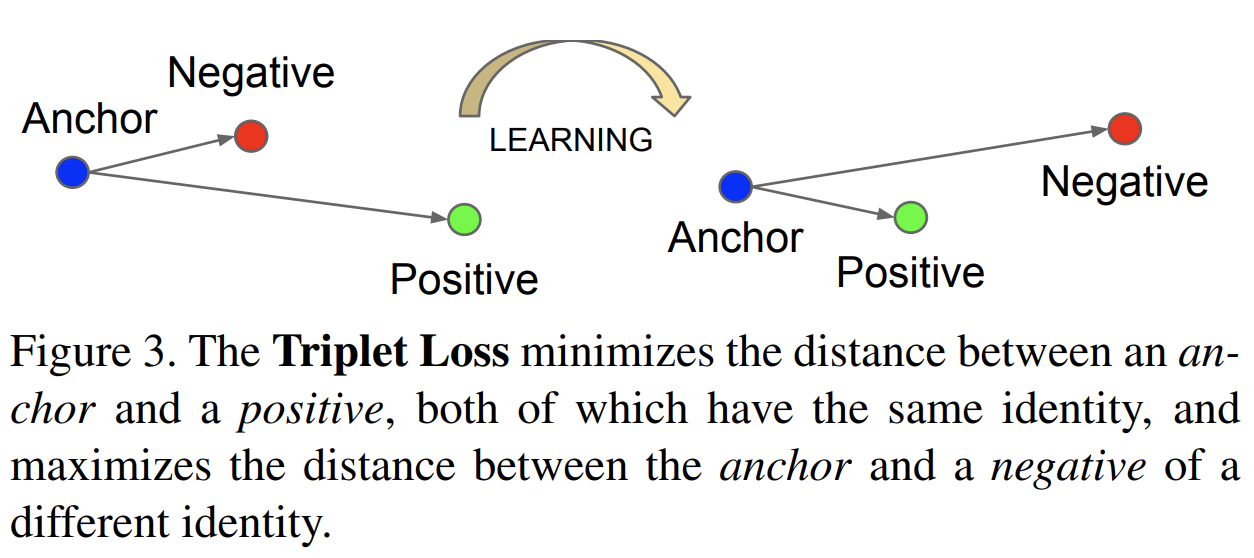
Triplet LossTriplet Loss는 딥러닝 기반의 임베딩 학습에서 자주 사용되는 손실 함수이다. 해당 손실 함수를 사용하면, 주어진 데이터들의 관계를 고려하여 임베딩 공간에서 특정한 거리를 유지하도록 학습하는데 도움을 준다. Triplet Loss는 이름에서도 추측할 수 있듯이 세가지 샘플(triplet set)로 구성된 입력 데이터(Anchor, Postive, Negative)를 사용하여 정의된다. Triplet Loss의 구성요소1) Anchor(A): 기준이 되는 데이터 포인트2) Postive(P): Anchor와 같은 클래스에 속하는 데이터 포인트3) Negative(N):Anchor과 다른 클래스에 속하는 데이터 포인트 Triplet Loss의 목표Triplet Loss의 주요 목..