
- CPU, GPU → 조금만 파괴시켜도 전체가 작동안함
- neural net, 뇌 → 일부분이 파괴되어도 전체가 망가지는건 아님. accuracy가 낮아질 뿐
RNN은 뇌와 마찬가지로 자기 layer의 뉴런으로의 링크를 허용하는 neural net
Motivation
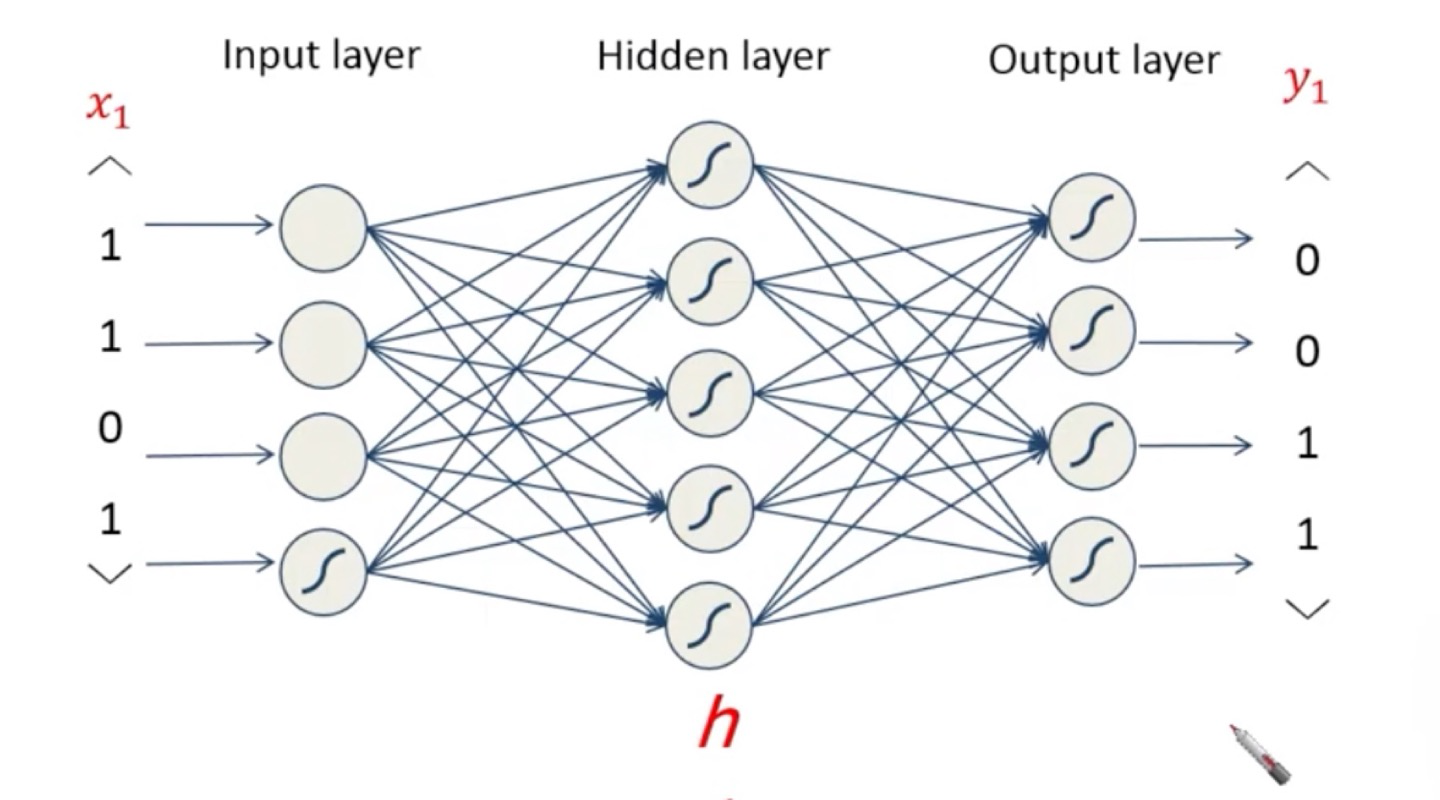
- 우리가 이때까지 배웠던 neural net은 function(many to one)의 형태, 그리고 fixed size data만 다룸
→ 같은 input을 넣으면 같은 output이 나옴
- 근데 사람은 (one to many, many to many) 문제를 다루기도 하고 variable size data도 다룸
ex) 자연어
이런건 우리가 이때까지 배웠던 neural net으로 못다룸
- ex) variable size의 수를 받아서 짝수면 0, 홀수면 1을 출력하는 문제

- fixed context window를 써서 variable length를 다루는 문제를 처리하는건 hard/impossible
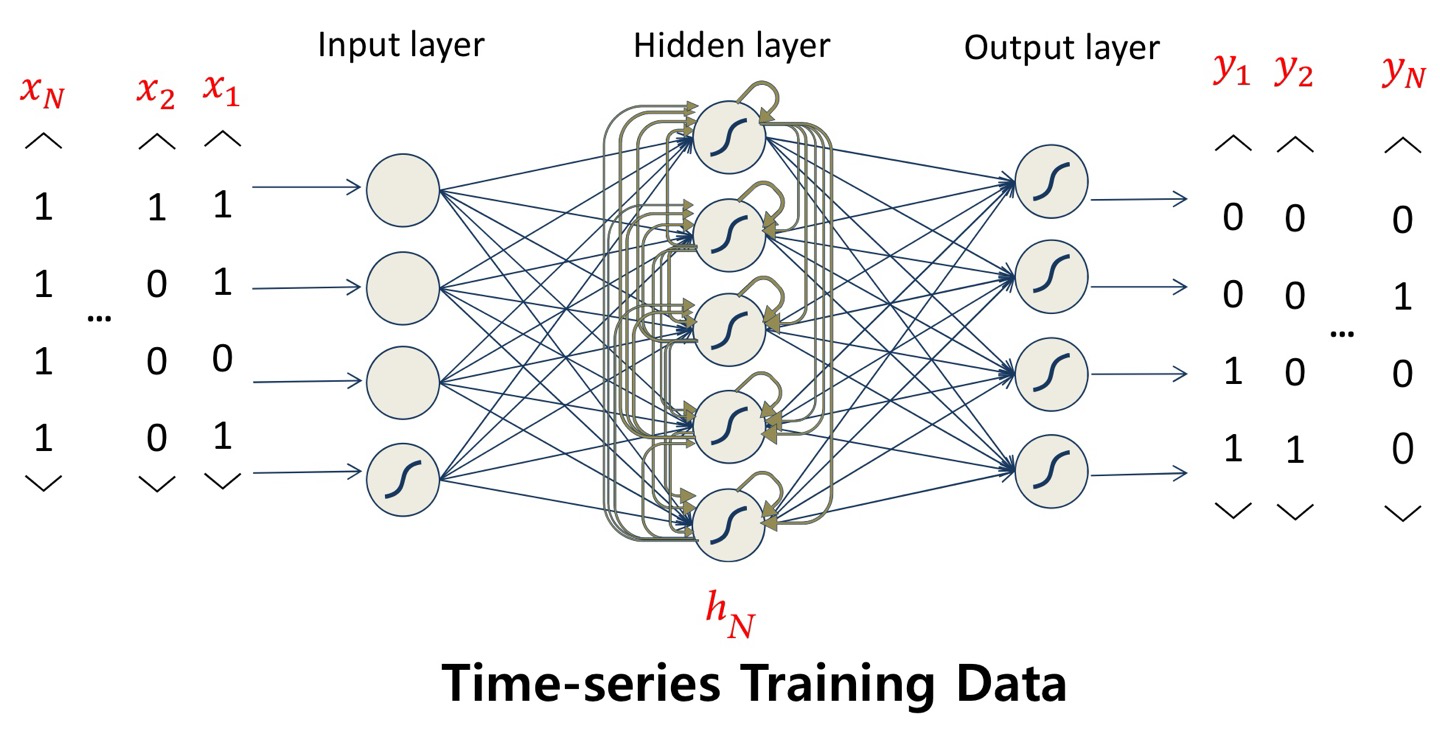
Recurrent Neural Networks(RNNs)
- Recurrent neural net은 함수랑 다르고 automata랑 비슷하다!
→ state에 따라 같은 input이 들어와도 다른 output이 나온다
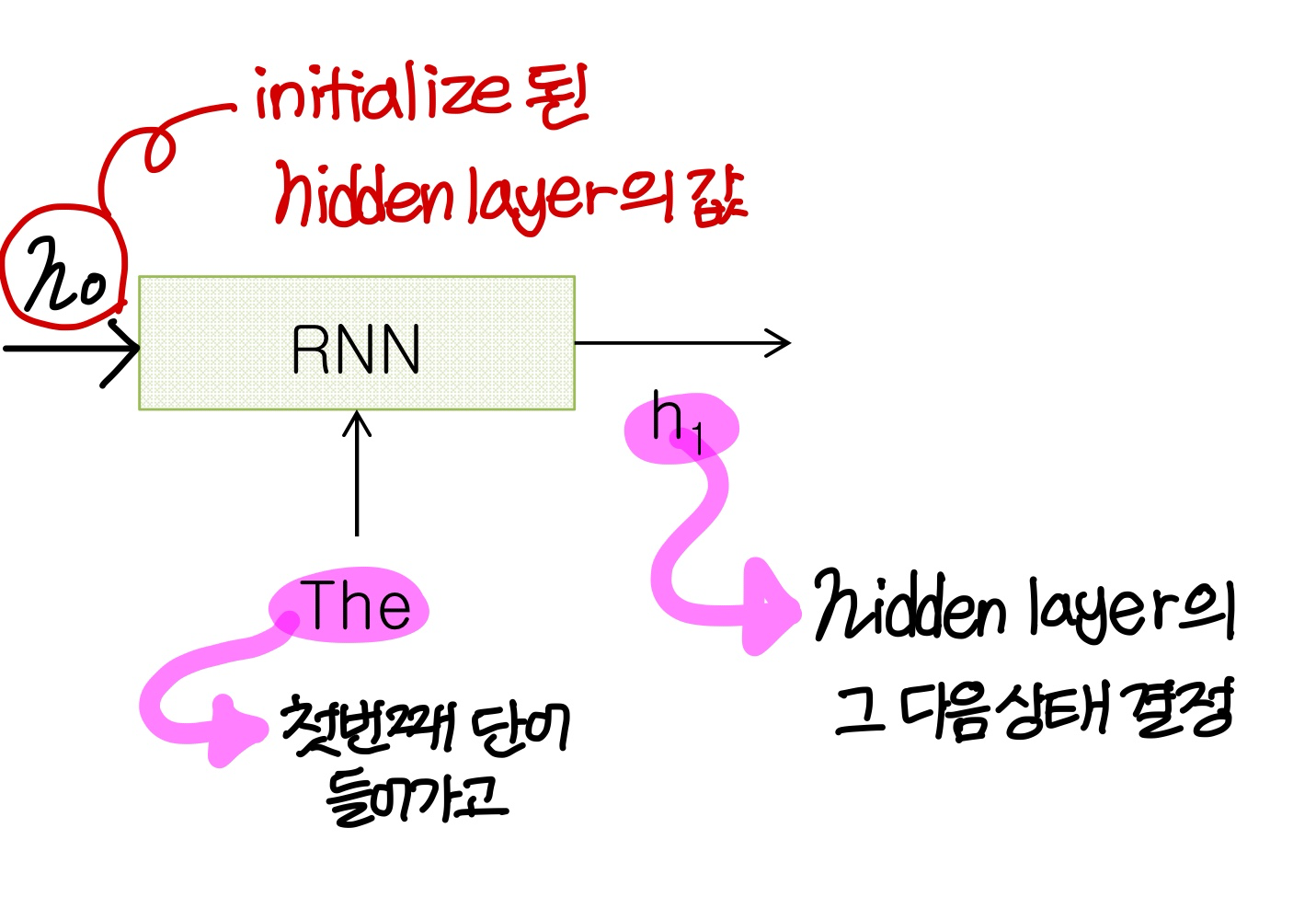
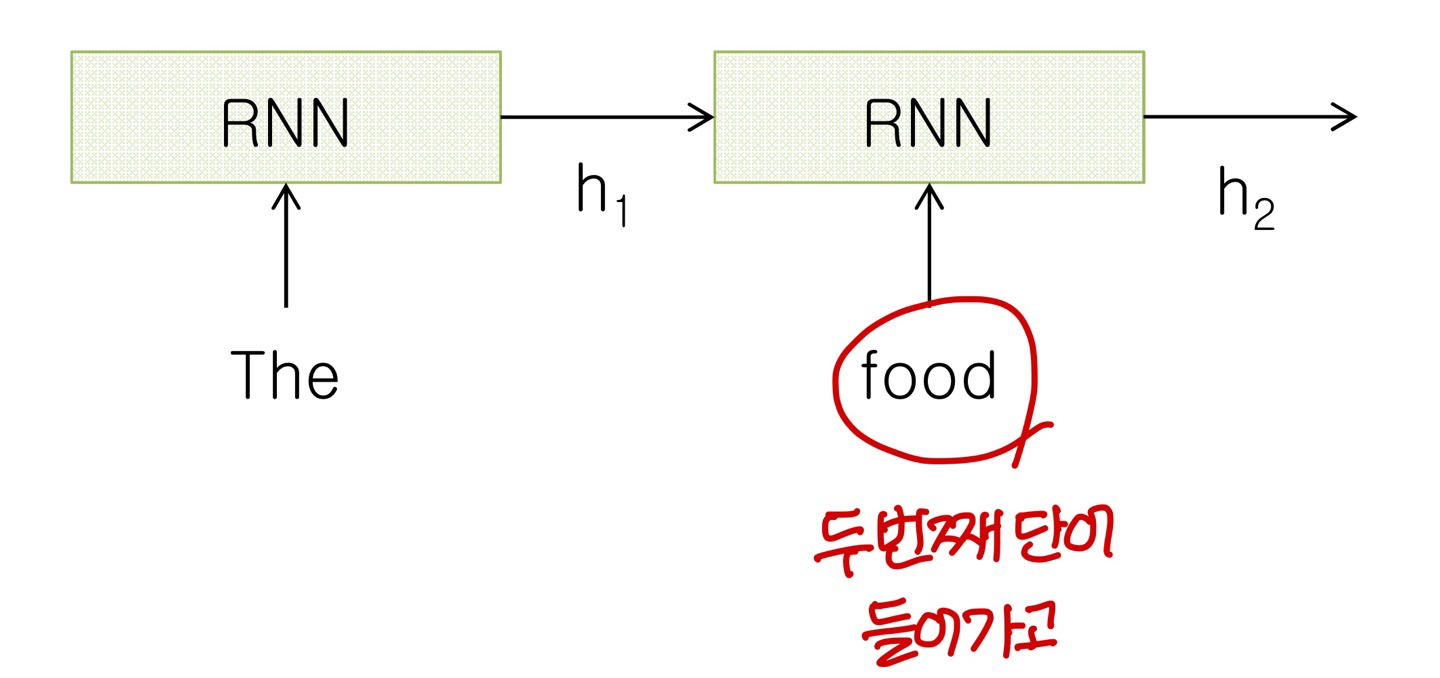
→ hidden layer의 출력값을 hidden layer의 다음 input으로 넣어줌
→ t 시점에 들어온 input은 t 이전에 일어난 일에 대한 historical information을 담고 있음
- RNN에서는 과거 input이 state의 형태로 저장됨
→ 근데 RNN은 hidden layer에서 그 다음 layer로 보내는 link뿐만 아니라 같은 layer로 들어가는 모든 link들을 가지고 있음
Revisted-Recurrent Neural Networks
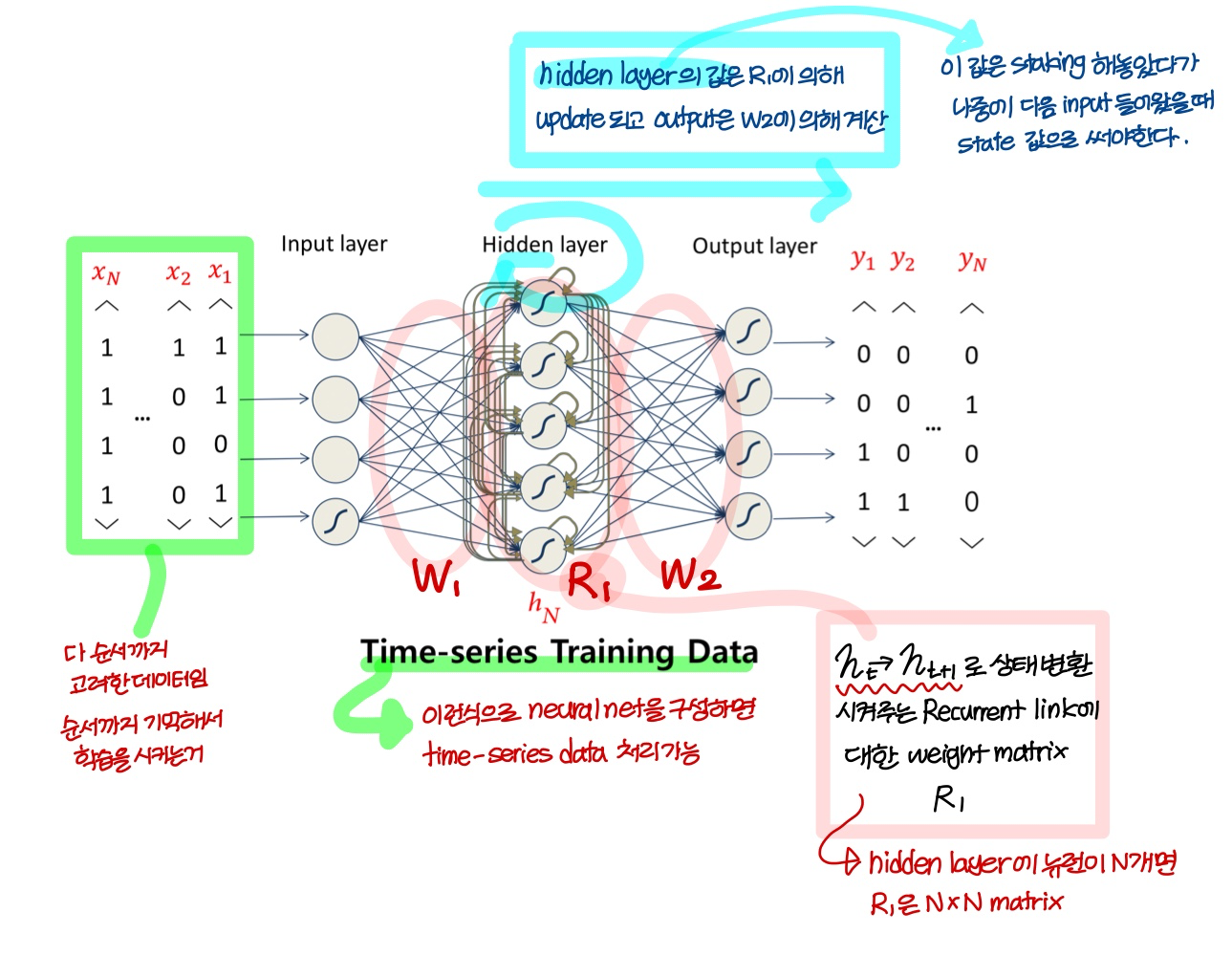
→ hidden layer가 많으면 recurrent link에 대한 matrix도 많아지겠지)
→ output이 에 의해 계산된다 해서 헷갈렸는데
상태값 새로 계산하고 그 new 상태값에 곱해서 output 나오는거
Sample RNN


The Vanilla RNN Cell
- Vanilla라는 말은 “가장 기본적인”이라는 말임
→ 아이스크림 중에서 바닐라 아이스크림이 가장 기본이니까!

- RNN에서 activation function으로 많이 사용한다!
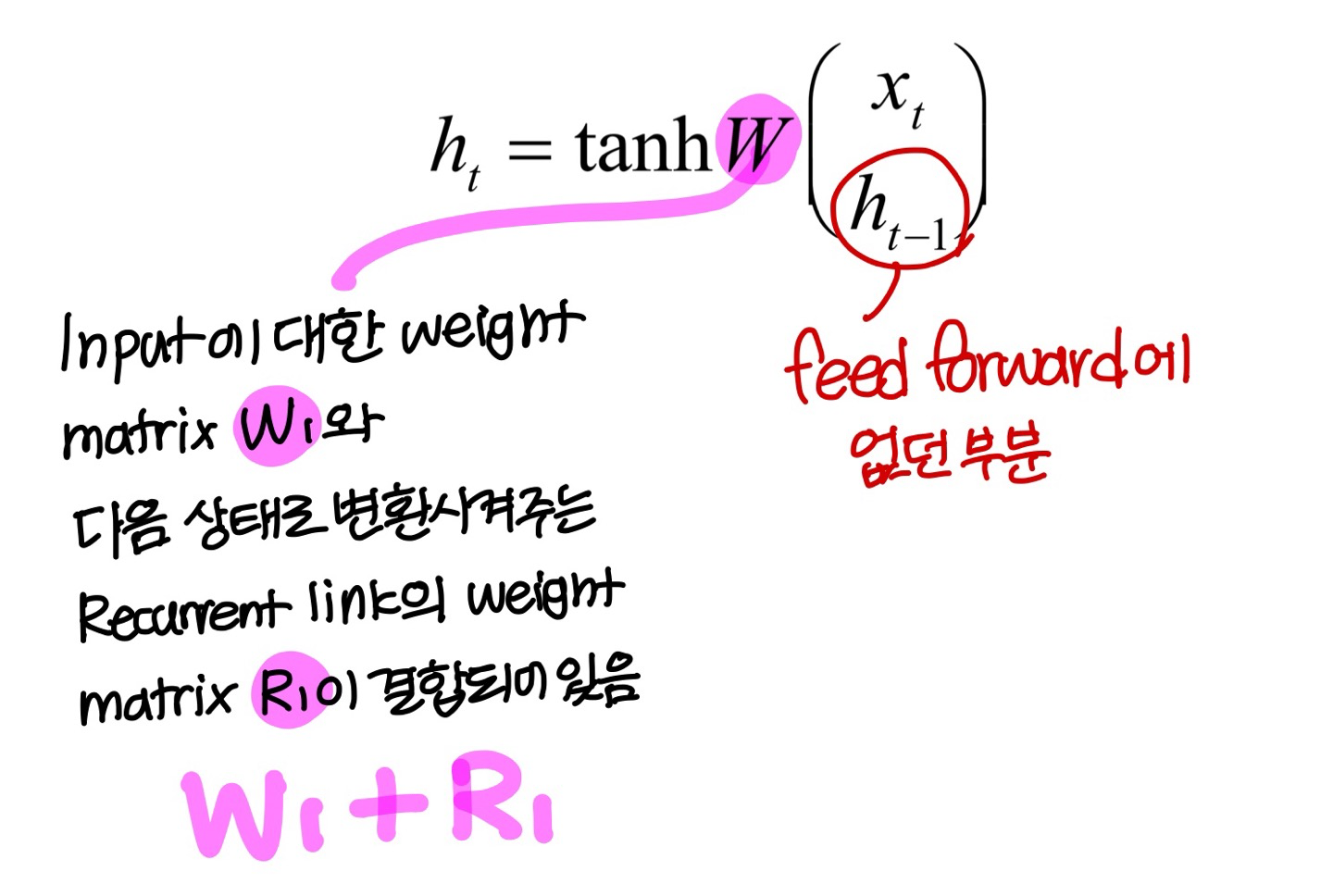
The Vanilla RNN Forward
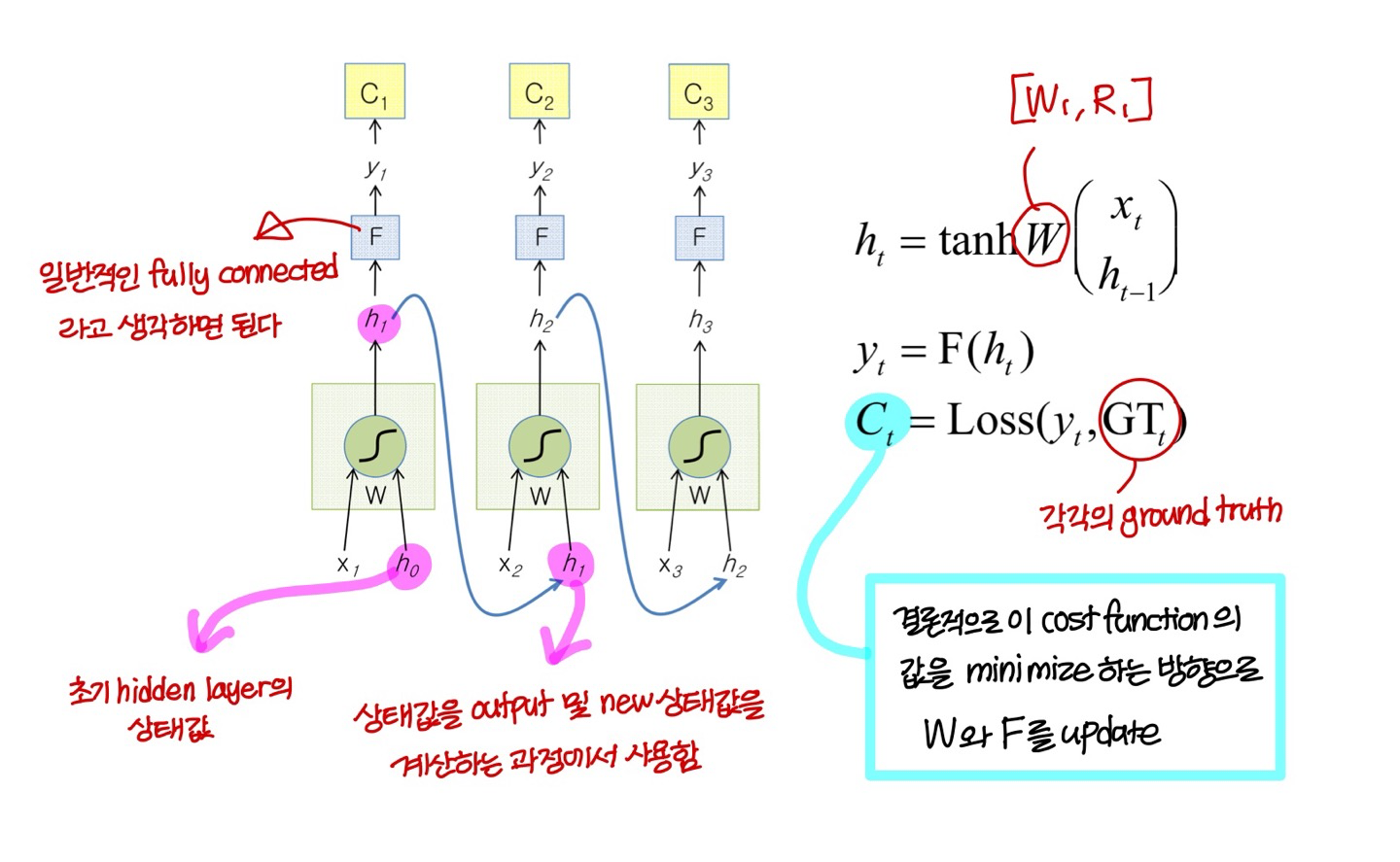
- 앞에서도 말했지만 주의! 위의 그림은 같은 아키텍쳐 시간 순서로 펼쳐놓은거임, 즉 W랑 F는 모두 같은 값
- update는 이런식으로!
Sentiment Classification
→ 이때 RNN을 쓰니까 효과가 좋다!
- 위의 상황에서
Input: Multiple words, one (or more) sentences
Outputs: Positive/Negative classification
한글같은건 교차어라 순서가 바뀌어도 의미가 유사하지만
영어같은건 순서 바뀌면 의미가 완전히 달라진다 → 우리는 영어 기준으로 생각할거임!
Sentiment Classification 하기 위한 neural net 구조


→ 단어 개수가 너무 많다보면 good/bad를 결정하는데 뒤에 있는 단어가 영향을 많이 미친다
→ 위의 문제를 해결하는 구조를 좀 있다가 배움
word embedding

→ 적당히 잘 embedding 되었다고 가정하자
→ 단어 embedding 할 때
- 동의어는 서로 다른 벡터로 나타낼 필요가 없음: 서로 같은 벡터로 나타냄
- 단어 중에 서로 관련 있는 단어들이 있음 (ex: 삼촌-남자)
이렇게 관련있는 단어들은 비슷한 벡터로 두고
아무관련 없으면 orthogonal vector로 두자
- 단어 중에 서로 관련있는 단어일수록 같은 문장에 있을 확률이 높고, 관련없을수록 서로 다른 문장에 있을 확률이 높음
→ 위키같은 방대한 문장이 있는 걸 활용해서 neural net을 통해 word embdding을 만들어냄
(nerual net에 input으로 word를 집어넣는 방식인 word embedding 방식을 neural net을 통해 만들어냄)
앞에서 말한 문제점을 해결한 구조
- 이게 뒷단어가 영향 많이 미치고, 앞단어가 영향 거의 못미치는 문제점을 해결한 구조임
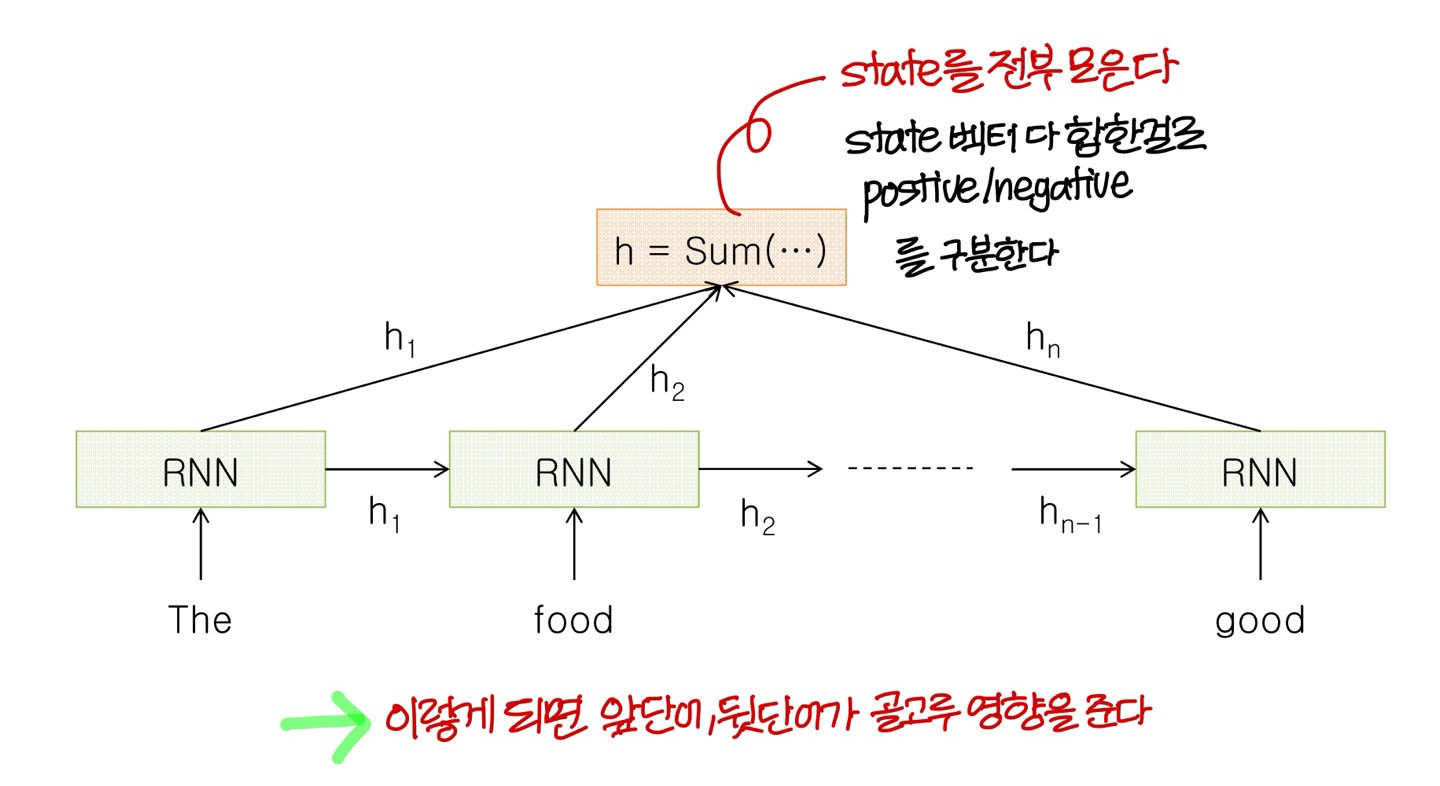
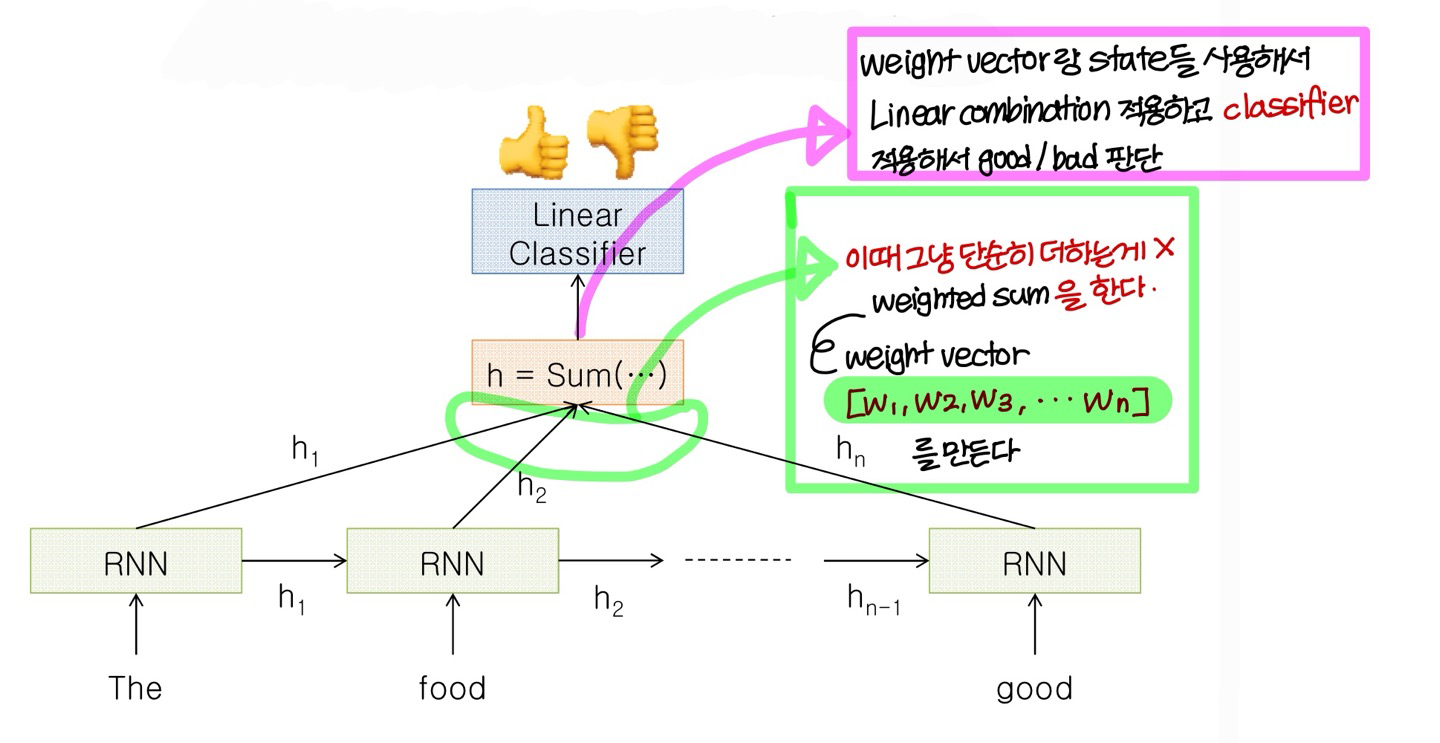
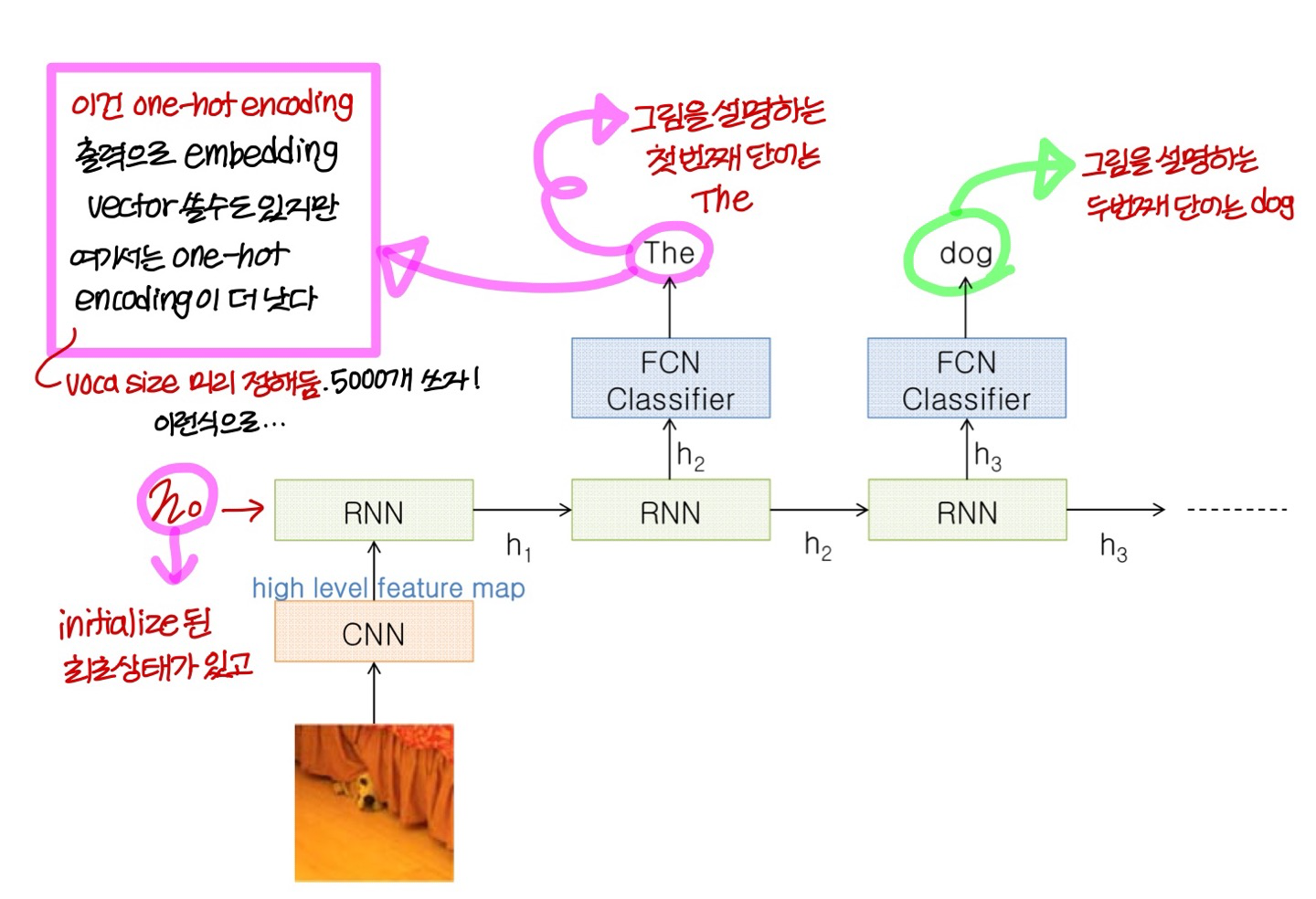
Image Captioning
- Image를 주고
Image를 설명하는 문장을 만들어내는 분야를 Image Captioning이라고 한다
- 딥러닝이 가장 성공적으로 사용된 분야 중 하나임
- Input: CNN으로 만들어낸 Image feature
- Output: Multiple words (one simple sentence)
→ 학습을 이런식으로 시킨다!

→ 동작은 이런식으로!
→ 결과는 이런식으로!

: 생각보다 결과를 잘 뱉어낸다!
Input-Output Scenarios
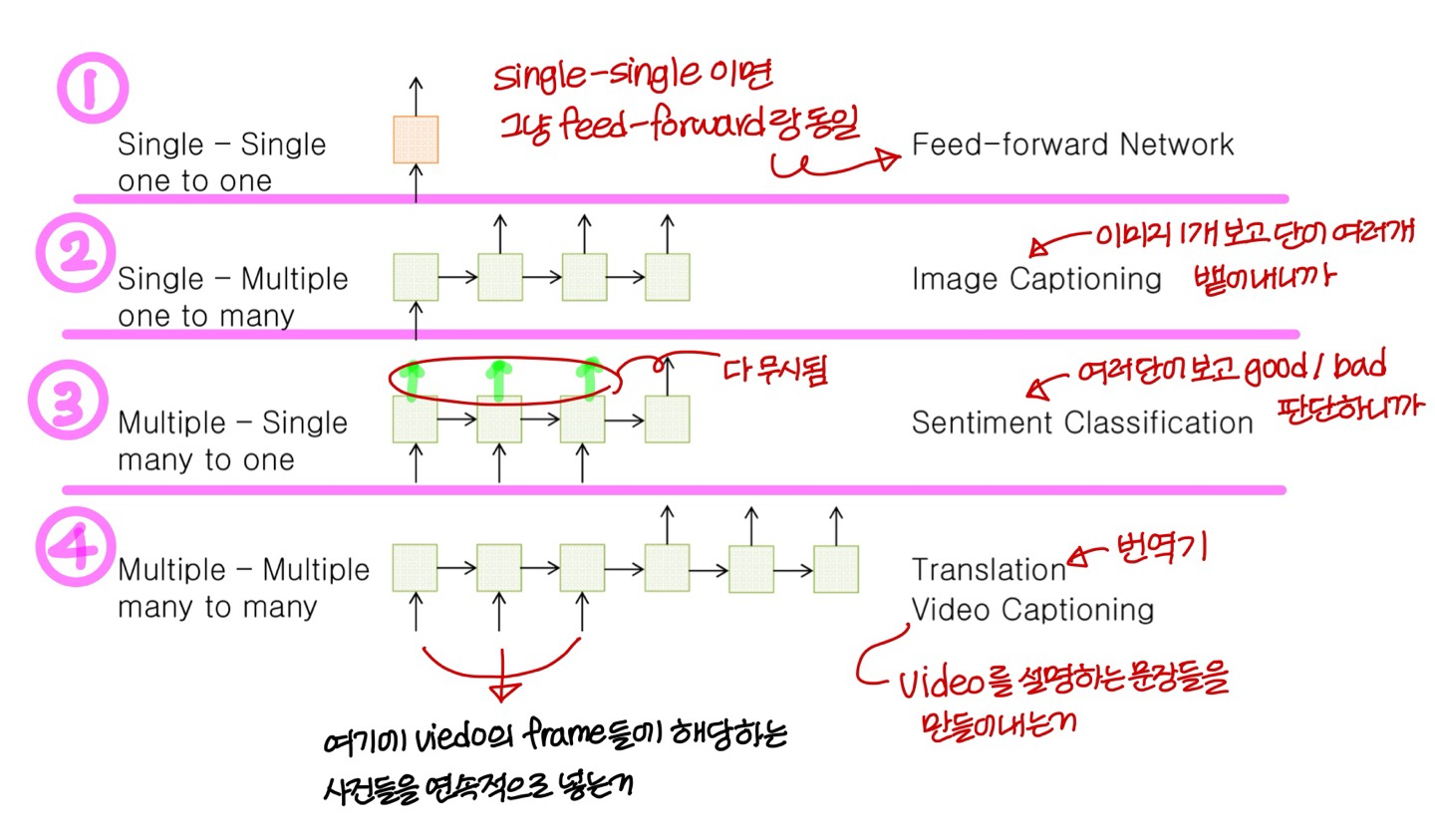
- many to many에도 종류가 있음!


<특이한 부분 두가지>
- hidden layer의 벡터(h_0)로 이미지를 넣어줌
- 시작 단어를 만드는 부분에는 SoS라는 special token을 Input으로 넣어주고
그 이후로는 그 전에 출력한 단어를 Input으로 넣어줌
BackPropagation Revisted!
- feed-foward에서는? (복습)

- Multiple layer에서는? (복습) - chain rule 사용하기
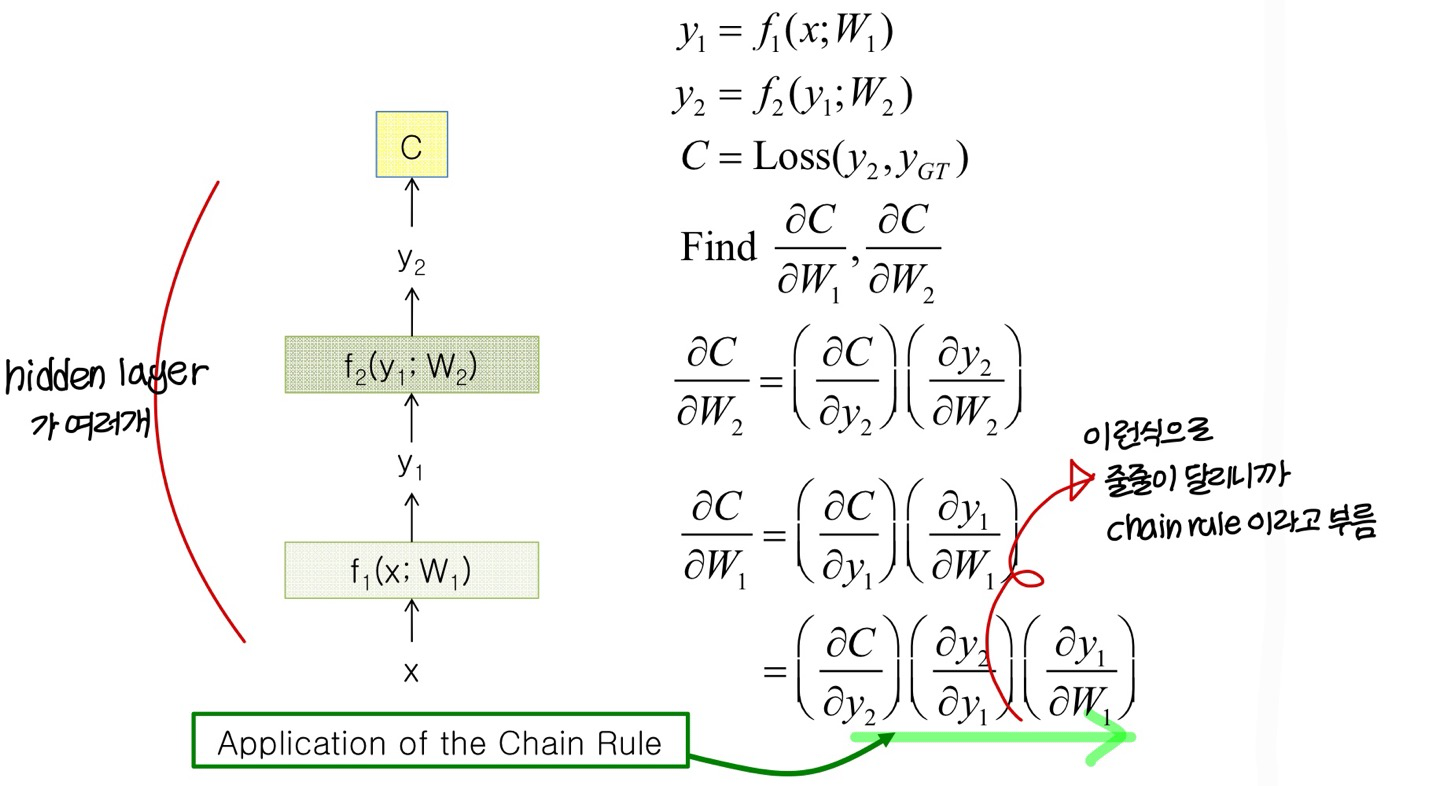
Extension to Computational Graph
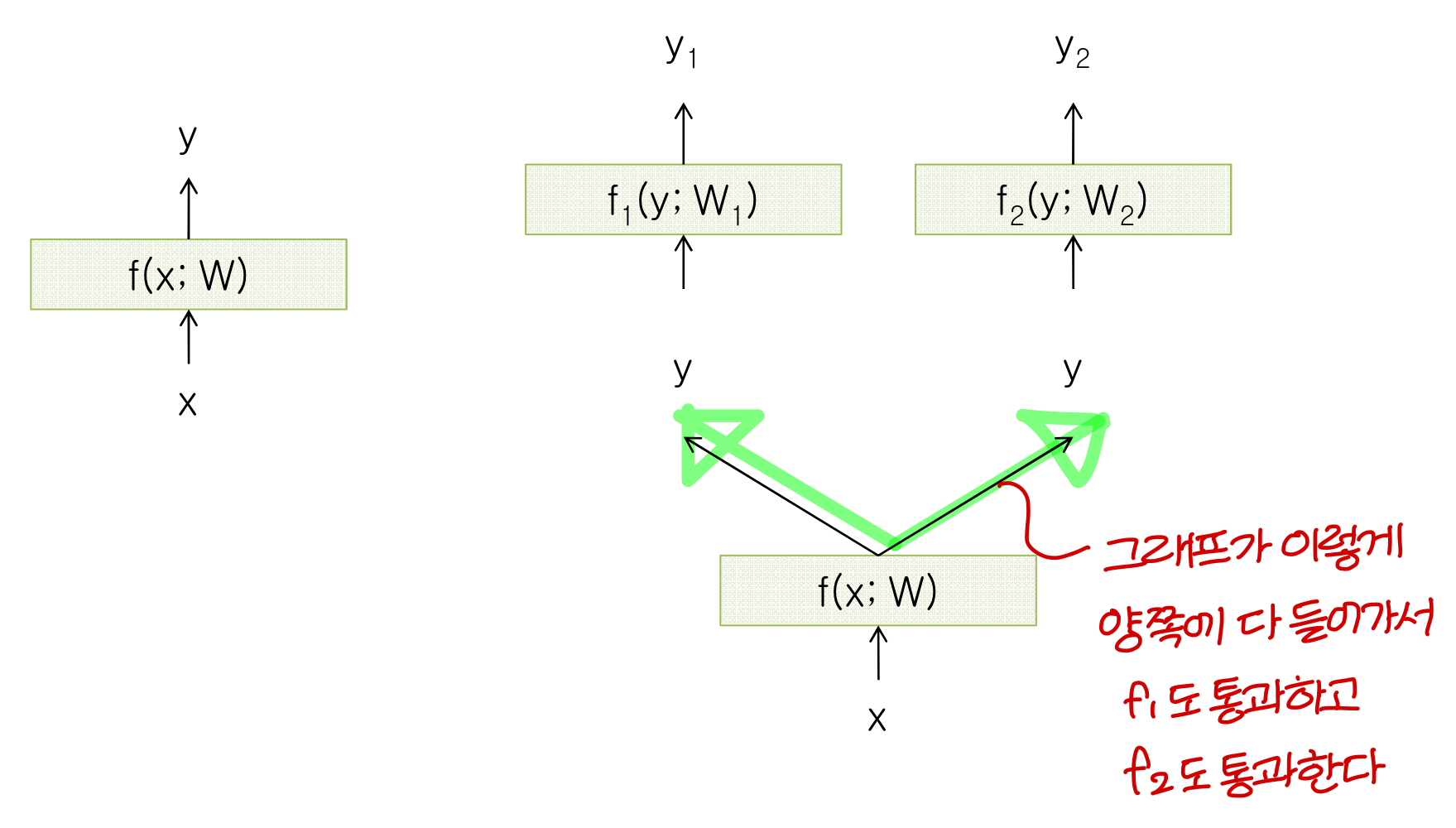
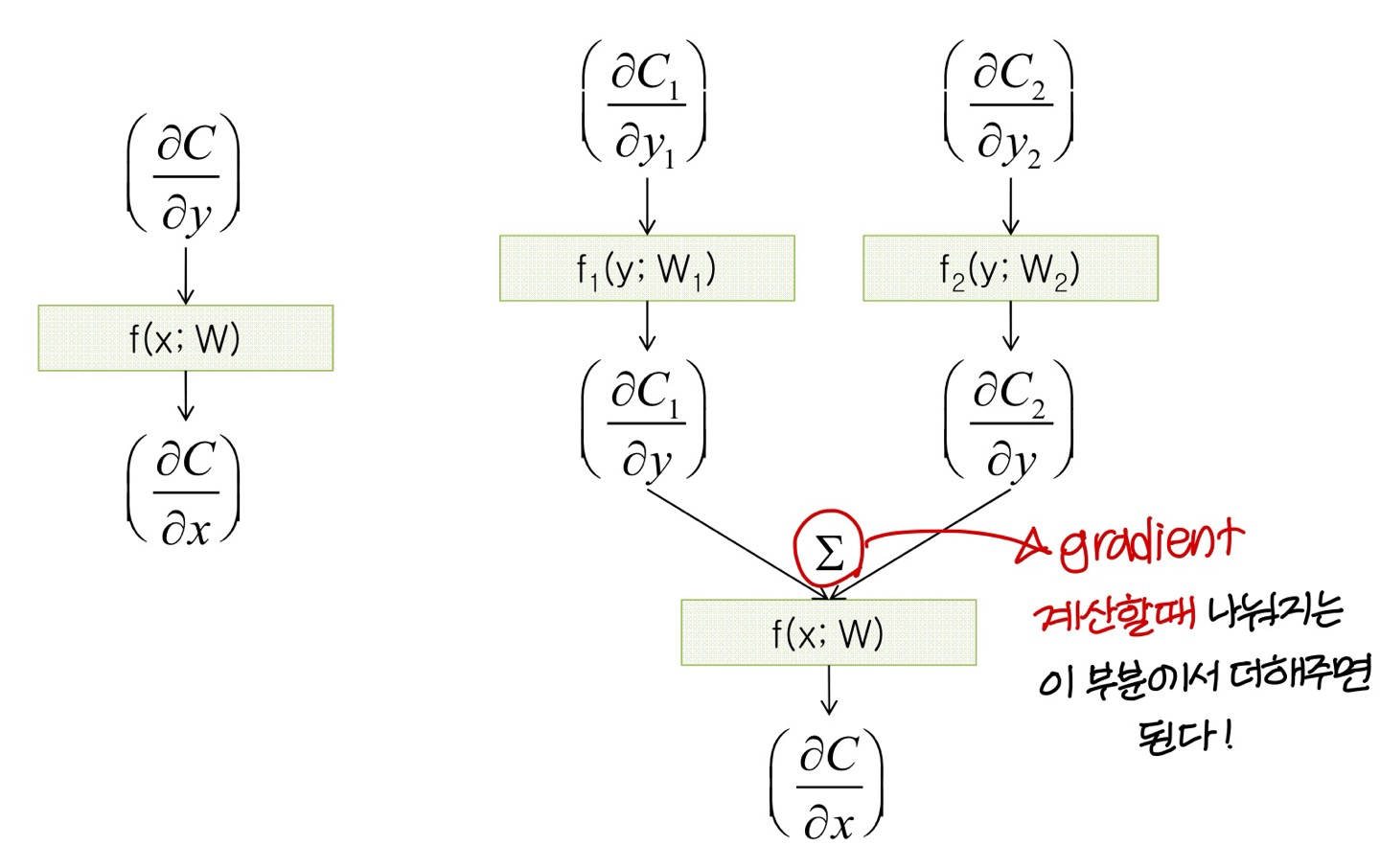
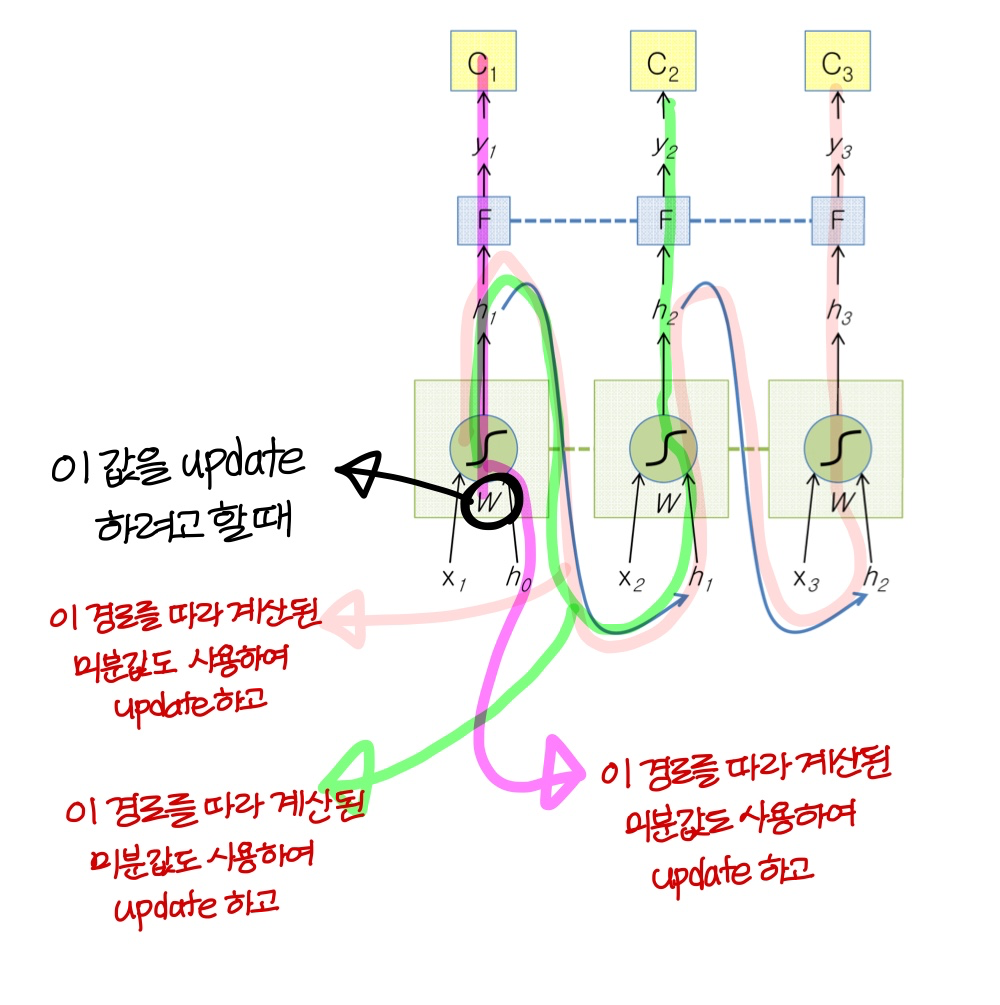
BackPropagation Through Time(BPTT)
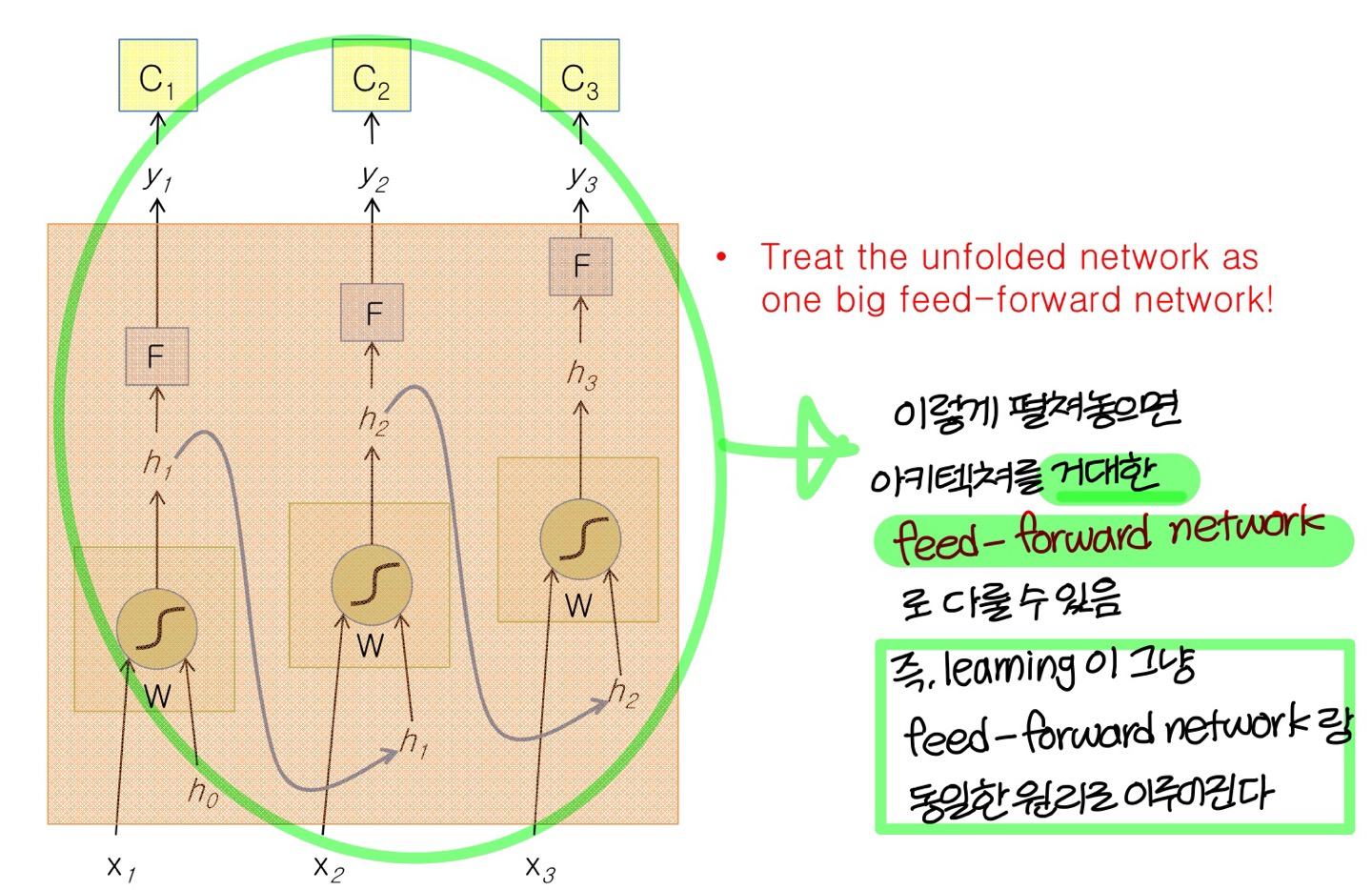
- 시간에 따른 gradient descent 값을 back propagation 해서 구한다해서 BPTT라고 부른다!
- 이때 시간에 따라 펼쳐놓은 (unfolding) 그림을 사용해서 back propagation을 함
- 우리가 이때까지 배운거랑 동일하게
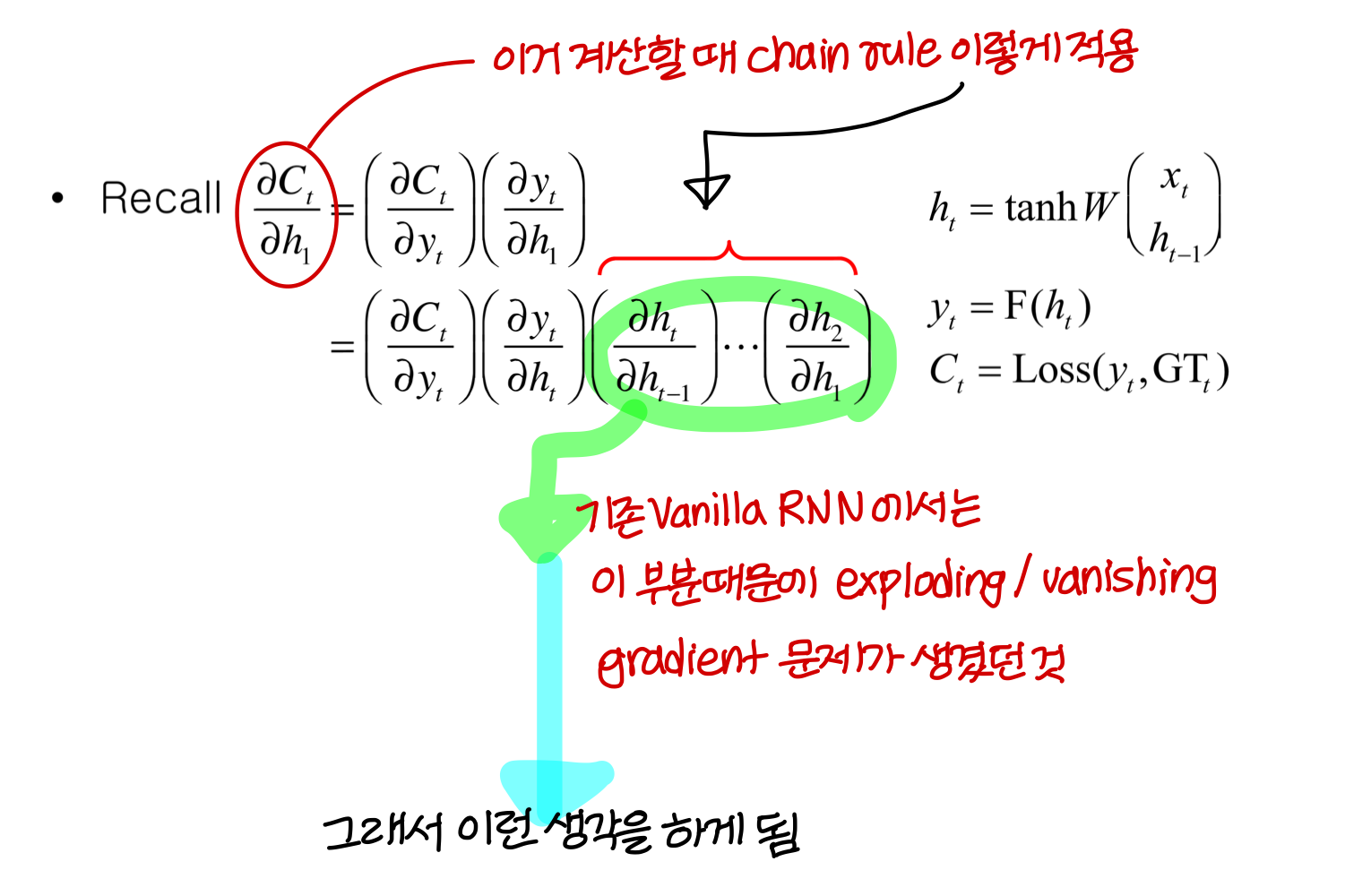
→ 같은 path 상에 있는건 미분한걸 곱해주고, path가 합쳐지는 부분에선 미분한걸 더해준다
- unfolding 구조를 사용해서 gradient 계산하기 때문에
unfolding network의 각 copy마다다 weight update 값이 계산될거임이걸 더하거나 평균내서 RNN weight 값을 update한다!
The Unfolded Vanilla RNN Forward

미분은 이런식으로
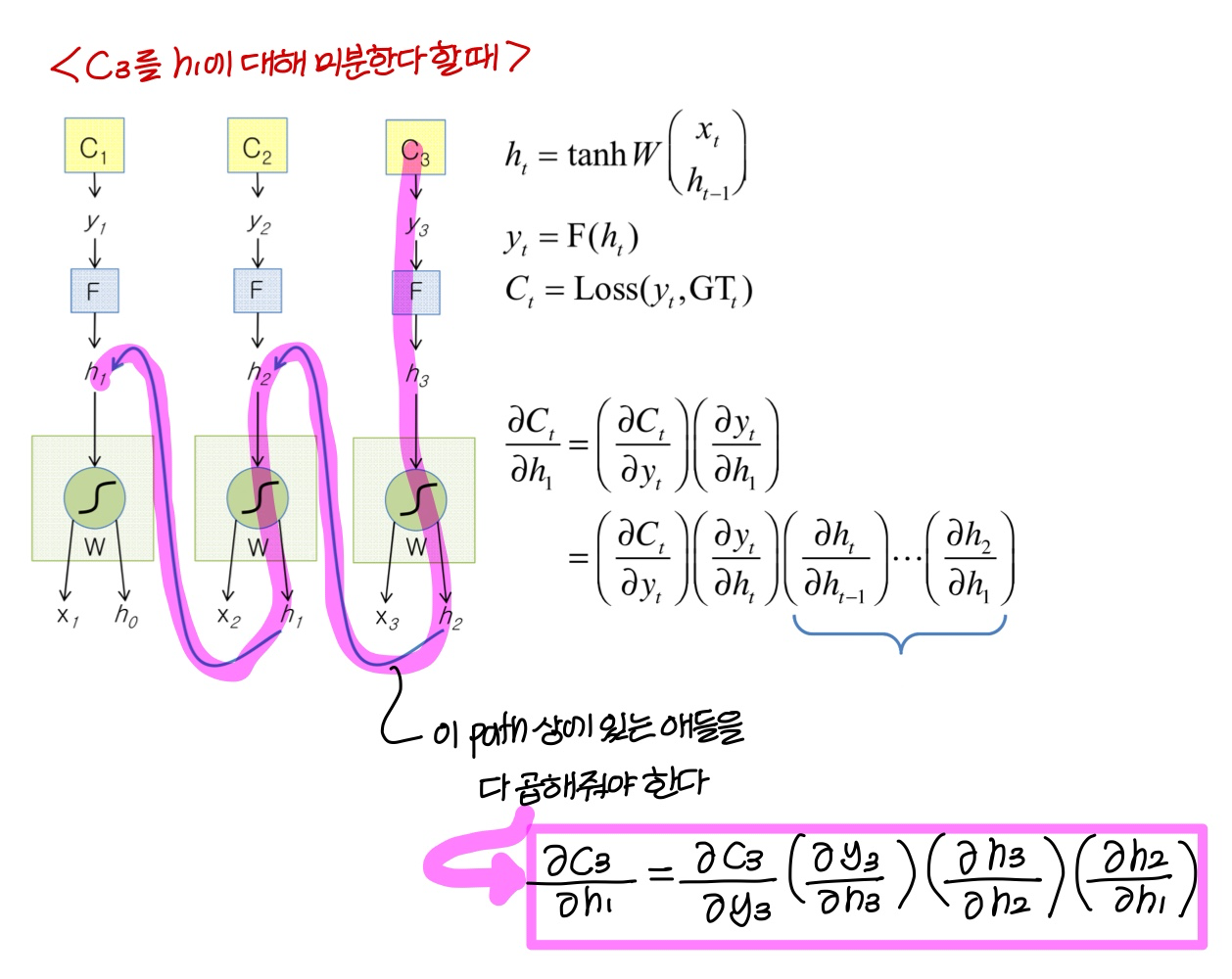
Backpropagation through time(BPTT)
이 과정에서 2가지의 문제가 생길 수 있음
1) 앞쪽 Input(long term)에 대한 low dependency
: 정리하자면 gradient를 계산할때 앞쪽 Input에 대한 gradient가 정확하게 계산되지 않아
이런식으로 학습을 진행하게 되면 뒤쪽 Input에 대해서는 dependency가 잘 학습되지만
앞쪽 Input에 대해서는 dependency가 잘 학습되지 않아
뒤쪽 Input의 영향만 많이 받는 model이 만들어질 수 있음
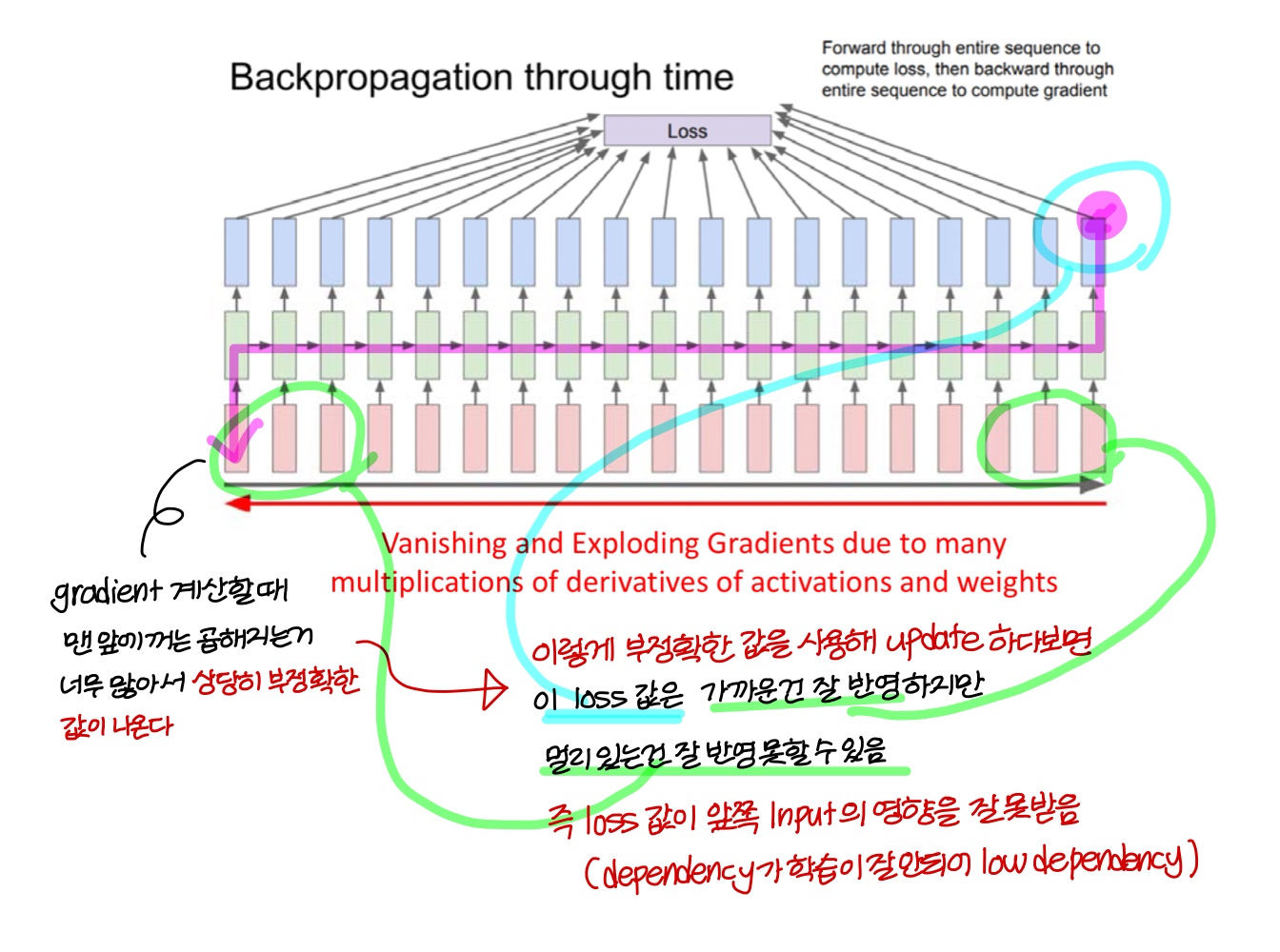
→ 경우에 따라 결과 판단할 때 앞쪽에 중요한 단어가 있을수도 있는데
model을 이런식으로 구성하니까 앞쪽 반영을 잘 못함
2) Vanishing Exploding Gradient
gradient 계산할 때 W가 계속해서 곱해지는데 이때
W의 norm이 1을 넘게 되면 → exploding gradients
W의 norm이 1보다 작게 되면 → vanishing gradients
문제가 발생
(뒤에서 더 자세히 살펴볼거임)
Truncated(결절의, 끝을 잘라버린) Backpropagation through time
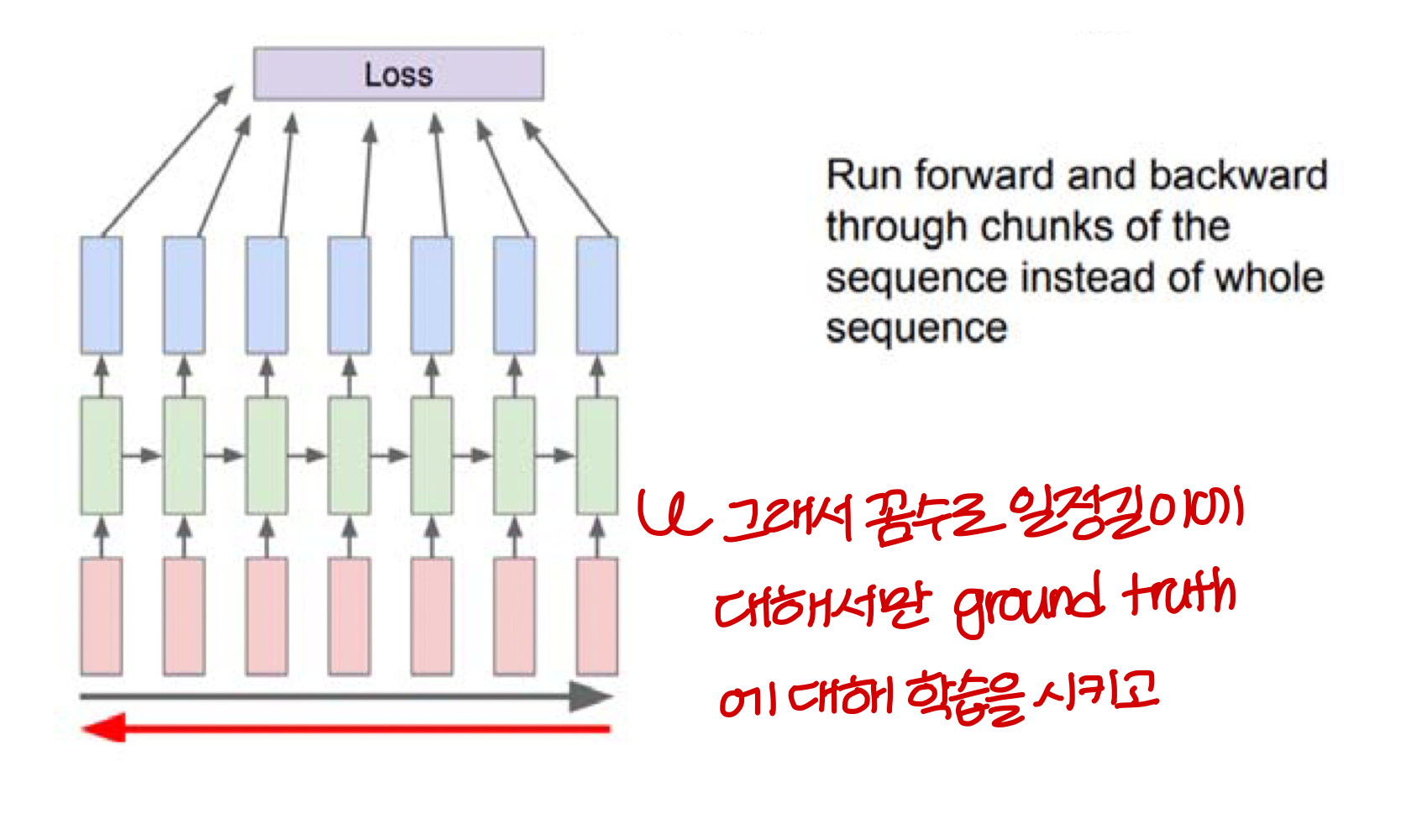
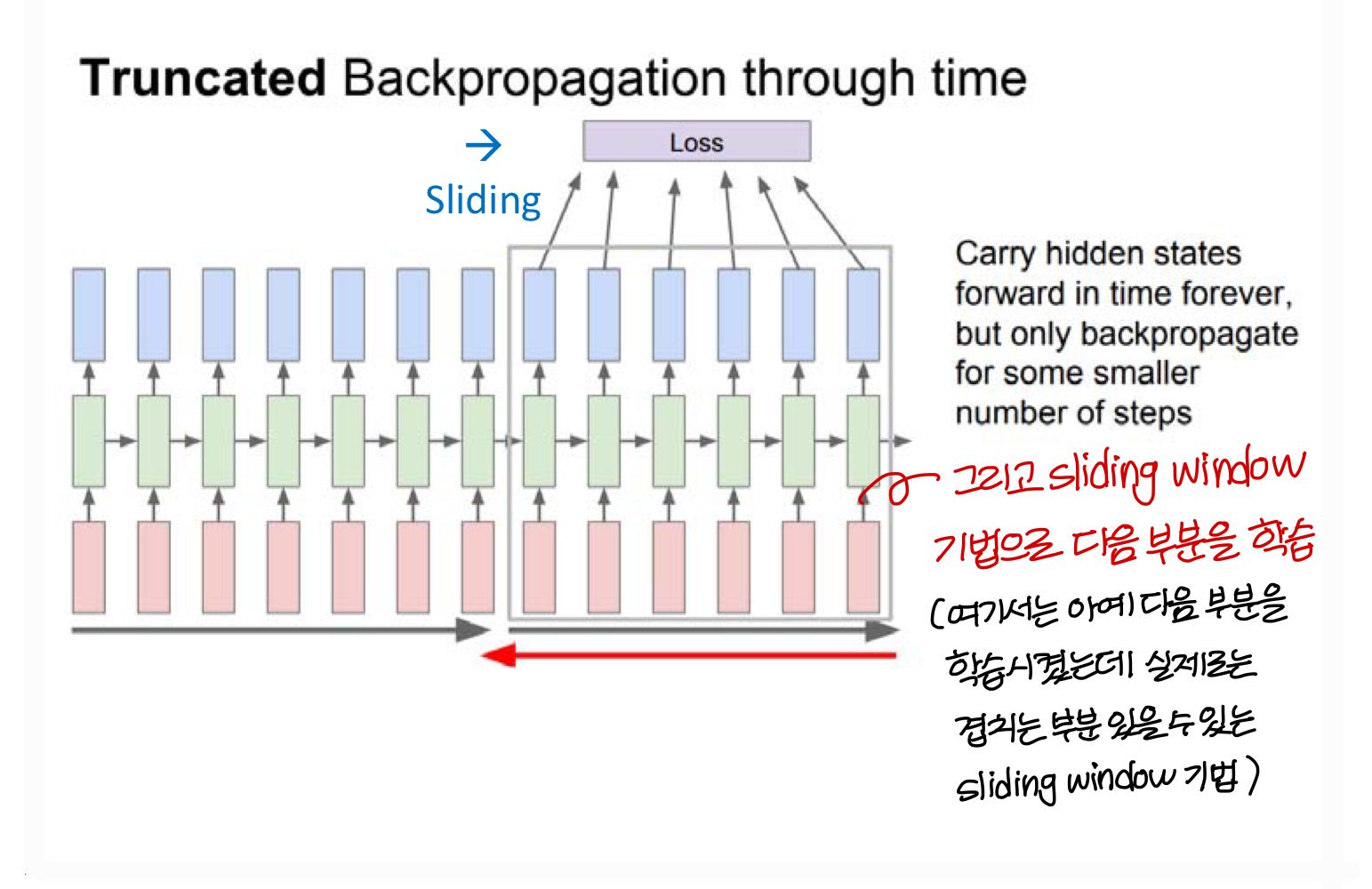
Truncated Backpropagation 방법을 쓰면
→ vanishing and exploding gradient 문제는 어느정도 해결이 된다.
→ 하지만, 여전히 logn term에 대한 low dependency 문제는 해결이 안됨
Vanilla RNN gradient Flow
Forward propagation

Backward propagation
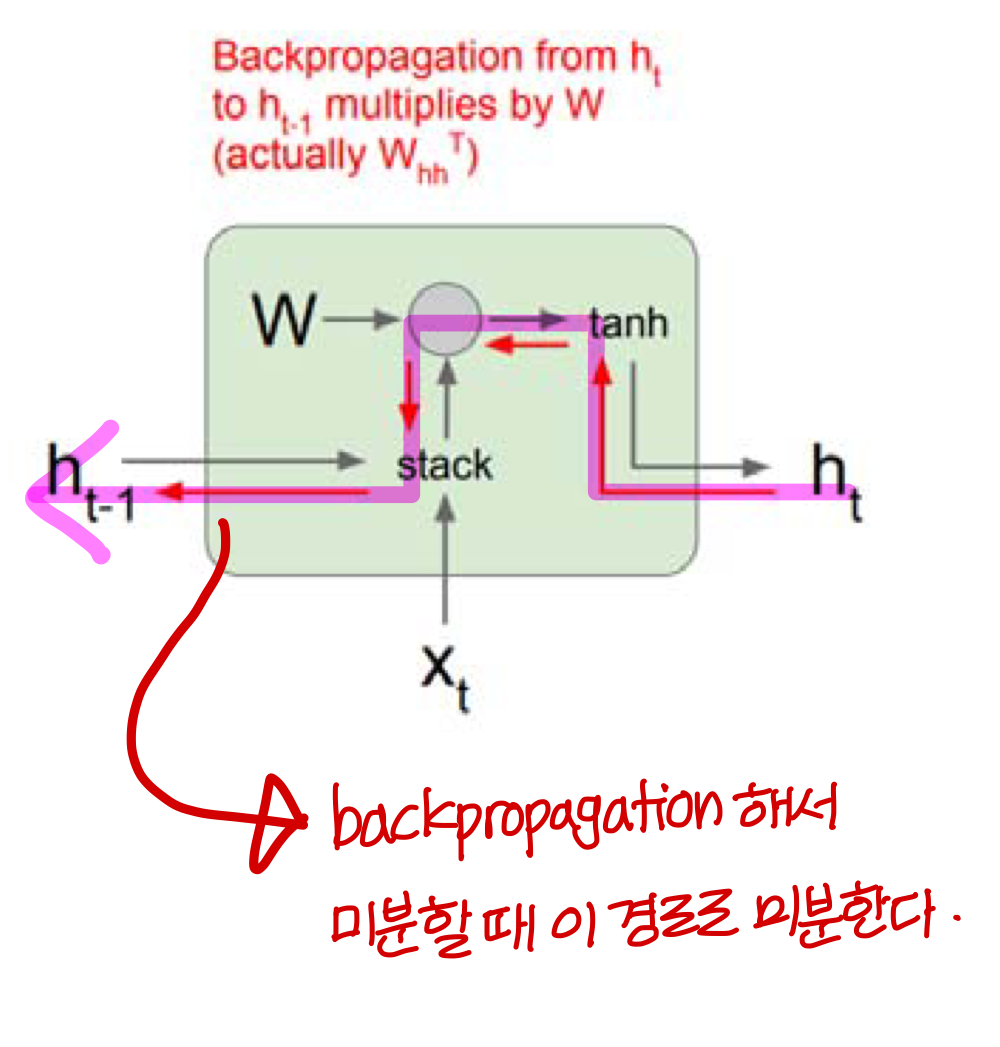


→ 이렇게 앞쪽 term에 대한 gradient 계산할 때: W가 계속해서 곱해지다보니

정확히 말하면 norm이 1보다 크거나 작으면 → exploding gradient, vanishing gradient
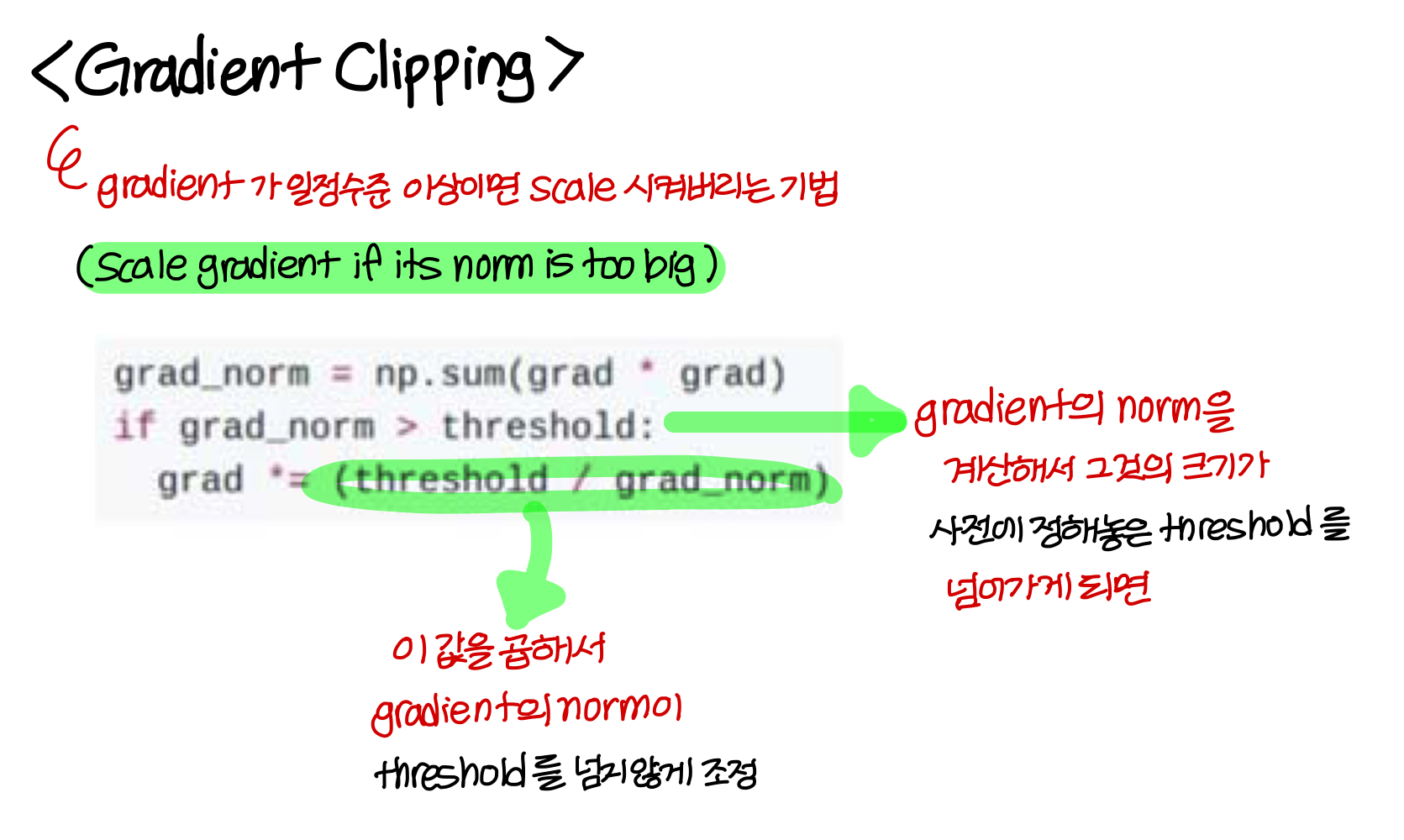
Exploding gradients 해결
exploding gradients 문제는 gradient clipping 기법을 써서 해결 가능
- gradient clipping 기법
Vanishing gradients 해결
RNN 아키텍쳐를 바꿔서 해결할 수 있음
ex) hidden states들 사이에 Identity relationship을 쓰는 방법이 있음 (뒤에서 다룬다)
The Identity Relationship

→ 설명 쉽게 하기 위해 activation function을 생략한거!
→ error(오차)만 뒤로 전파되어서 gradient는 decay되지도 않고
explode 되지도 않는다고 해서 이 방법을
“Constant Error Flow” 라고도 부름
→ 이 방법을 사용하는게 바로 LSTM
Long Short-Term Memory(LSTM)
- 이걸 경량화, 단순화 시킨게 GRU
- LSTM은 RNN에 대한 “Constant Error Flow”라는 아이디어에 의해 motivated됨
- key component는 memory cell
: memory cell은 identity relationship을 포함하는 accumulator처럼 행동함
- “constant error flow”에서 배운대로
new state를 old state에 matrix product 하여 구하는게 아니라 / 두 state의 차이를 계산함
(표현적으로 같지만 gradients는 더 낫게 behaved됨)
The More Detail of LSTM Cell
- gate가 3개 존재: Input gate, Output gate, Forget gate
→ 셋 다 0~1의 값을 가진다
→ 그 말은 즉슨 전부 activation function으로 sigmoid function 쓴다는거
Starting Point of the LSTM Idea
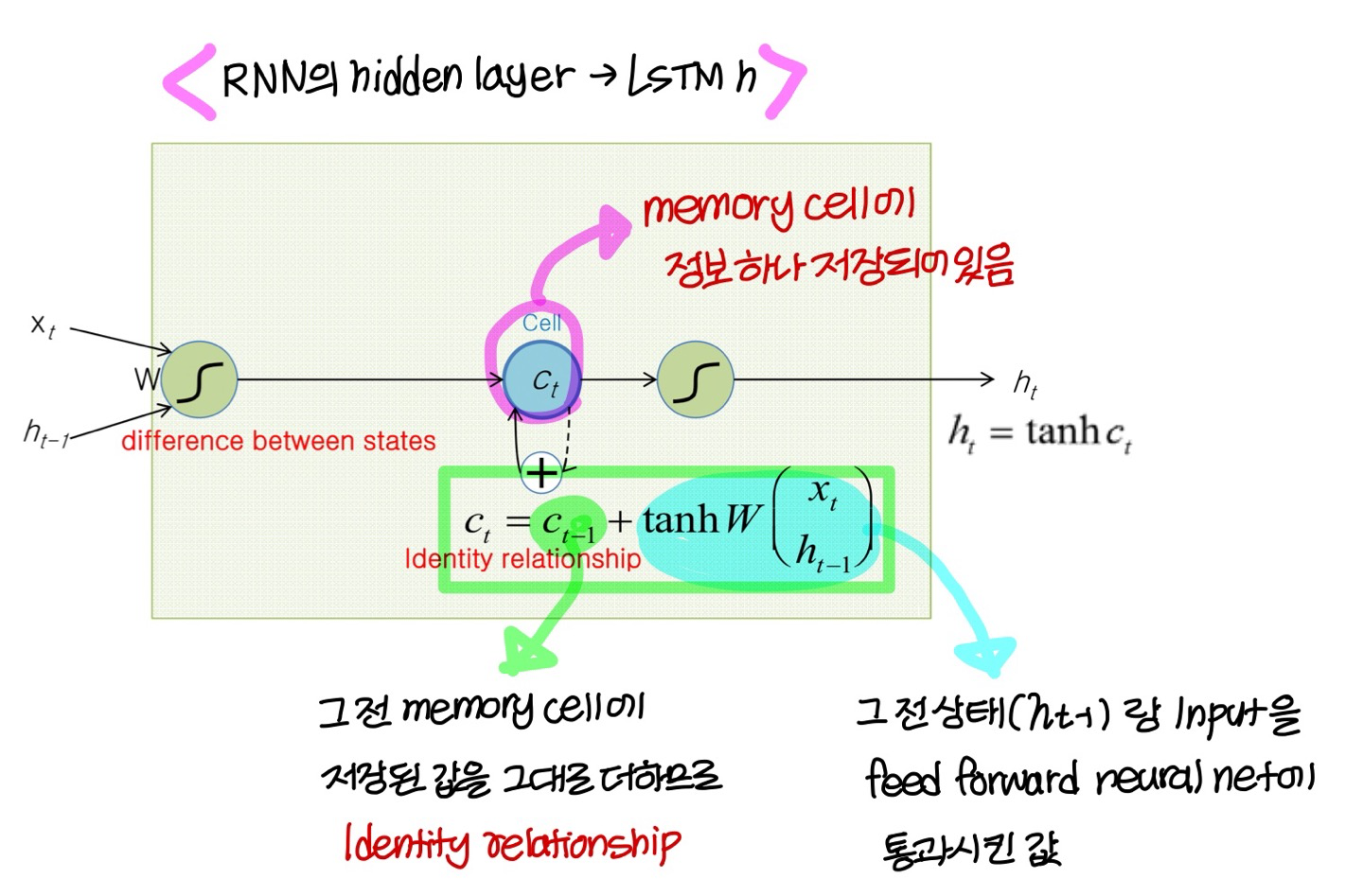
→ simple하게 아이디어만 보면 이럼
state 외에 memory cell에 저장되는 라는 값이 따로 존재
The Detail of LSTM Cell
- <Input gate>

- <Output gate>

- <Forget gate>
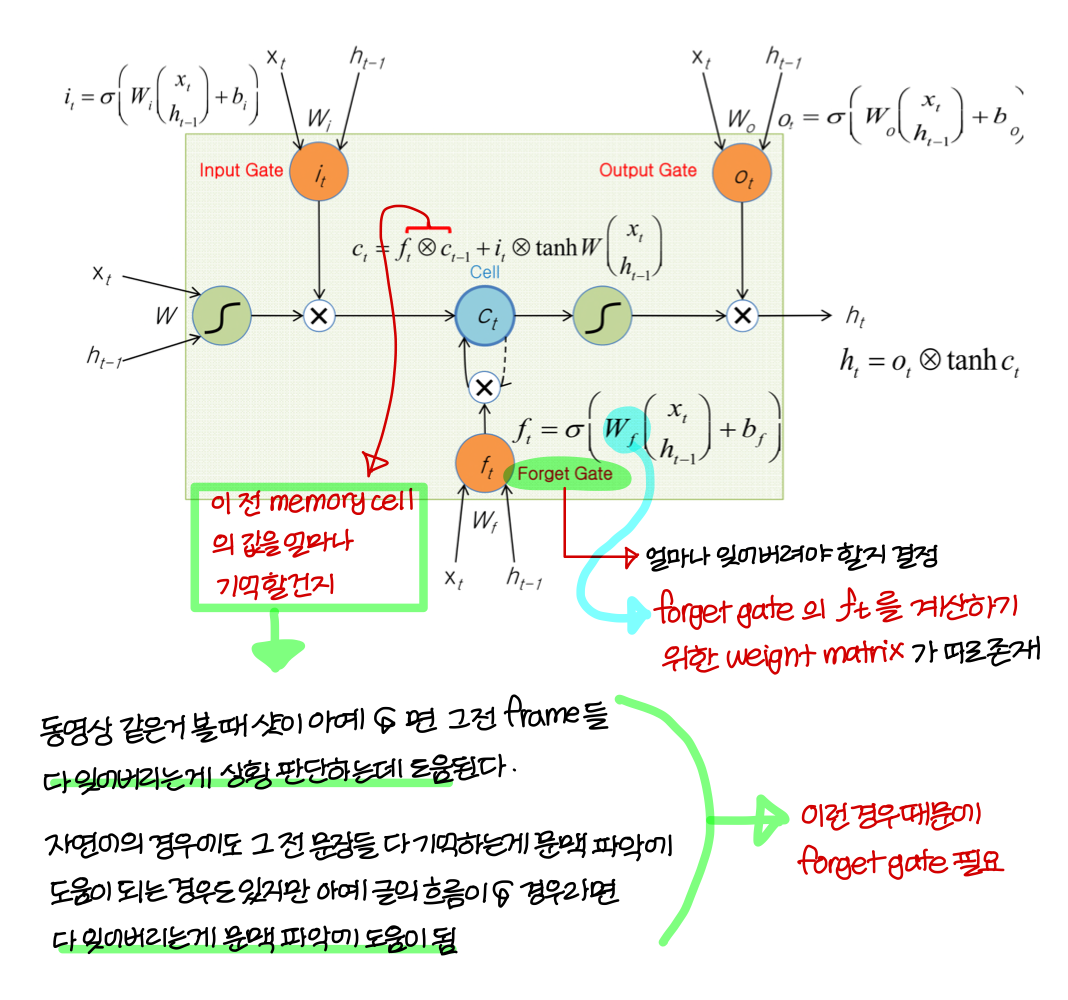
LSTM Cell(좀 더 formal한 설명)
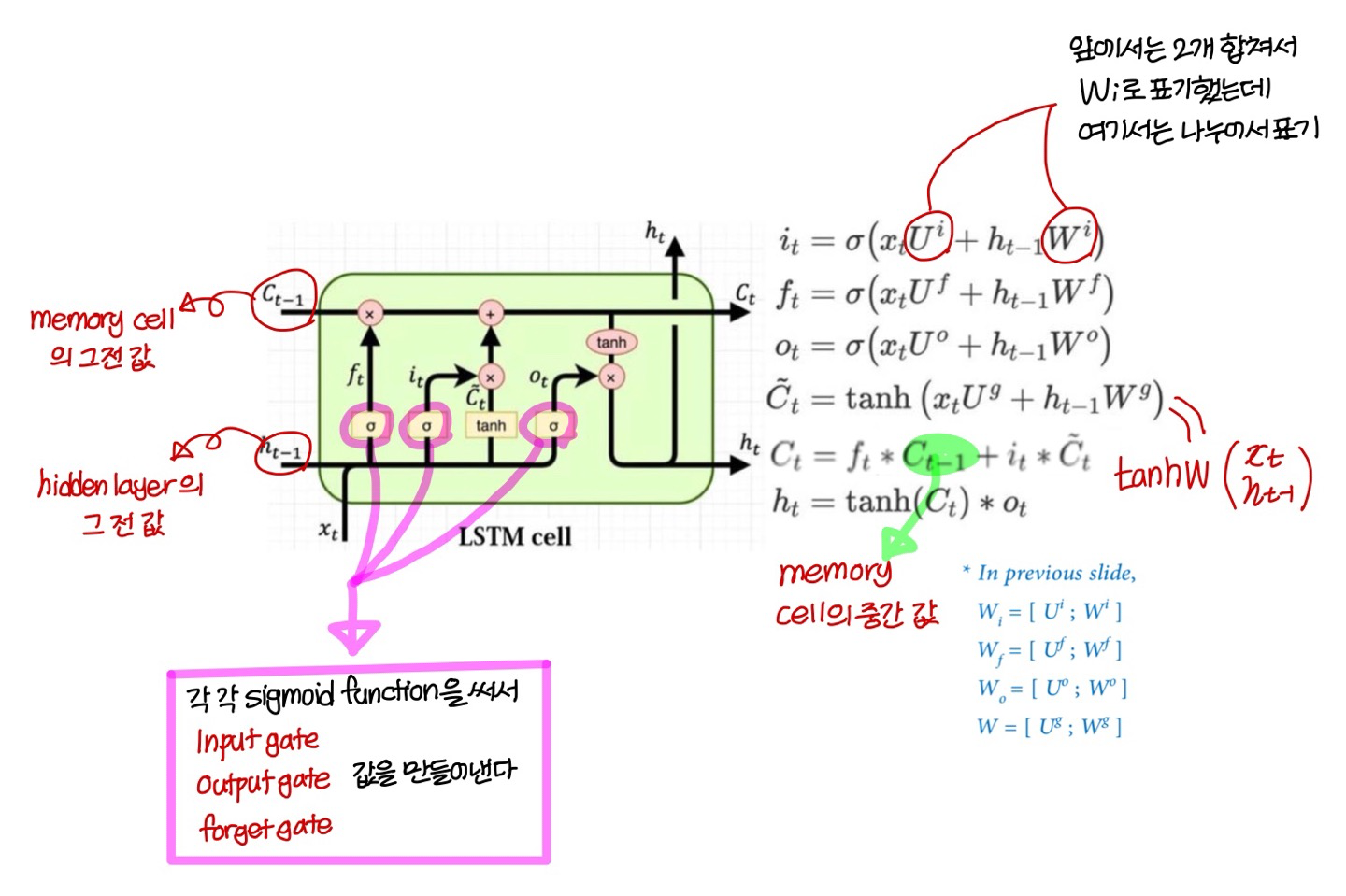
- sigmoid 어디서 쓰는지는 안헷갈린다!
→ input gate, output gate, forget gate 마지막에
- tanh 어디서 쓰는지는 살짝 헷갈림
→ memory cell 값 update할 때 기존 항 말고 다른 항에
→ state update할 때 memory cell 값에 적용
→ 딱 2번 쓰는거임!
LSTM 구조 (시간에 따라 펼쳐서 보면)
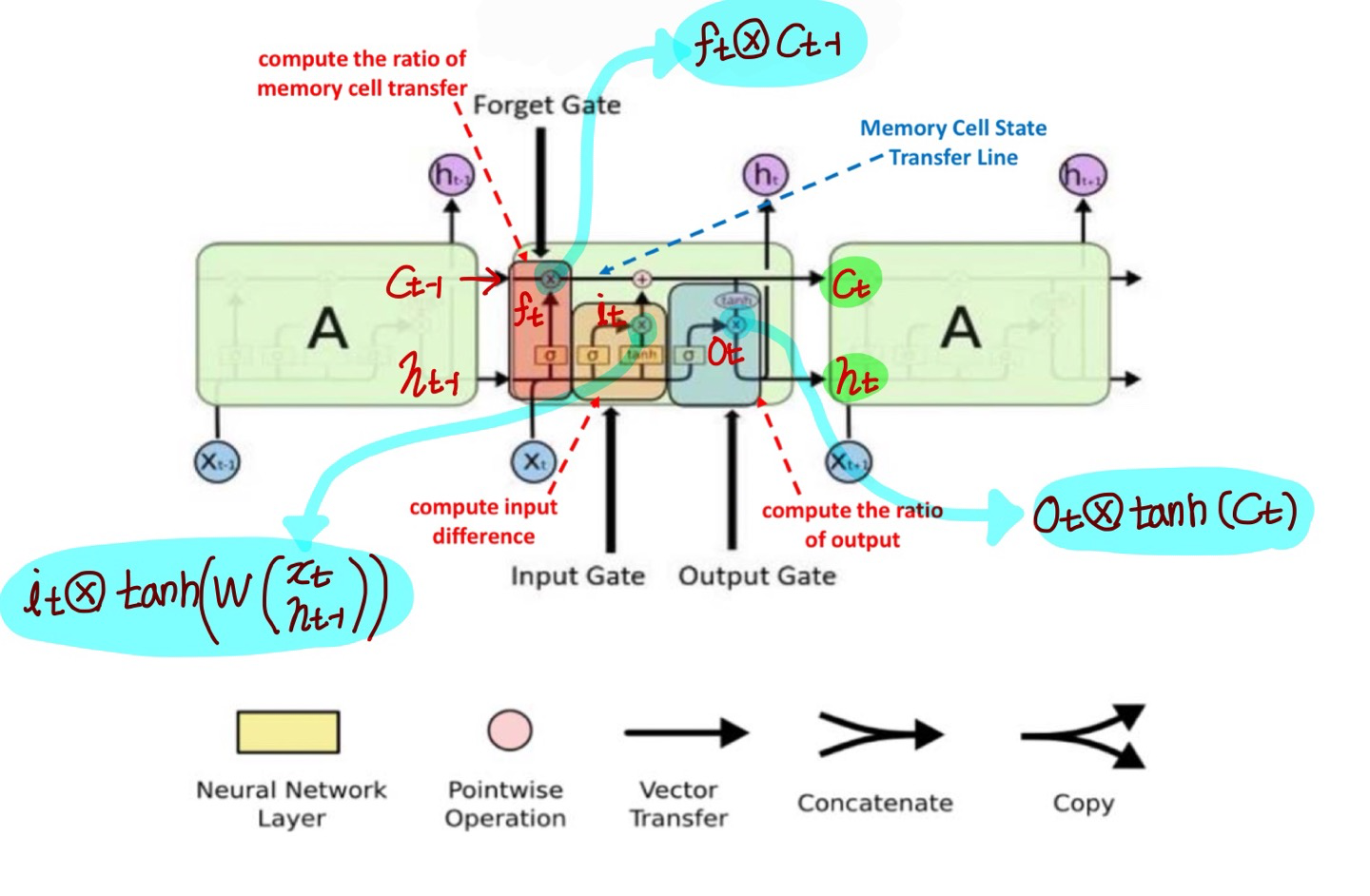
LSTM reduces vanishing or exploding gradient problem
- LSTM “Constant Error Flow”라는 아이디어에서 파생된거였다! → 즉 vanishing or exploding gradient 문제 없애기기 위한 거였는데
너무 다양한 내용 배우다 보니 살짝 논지 흐려졌음
- LSTM은 low dependency 문제도 해결해줌!
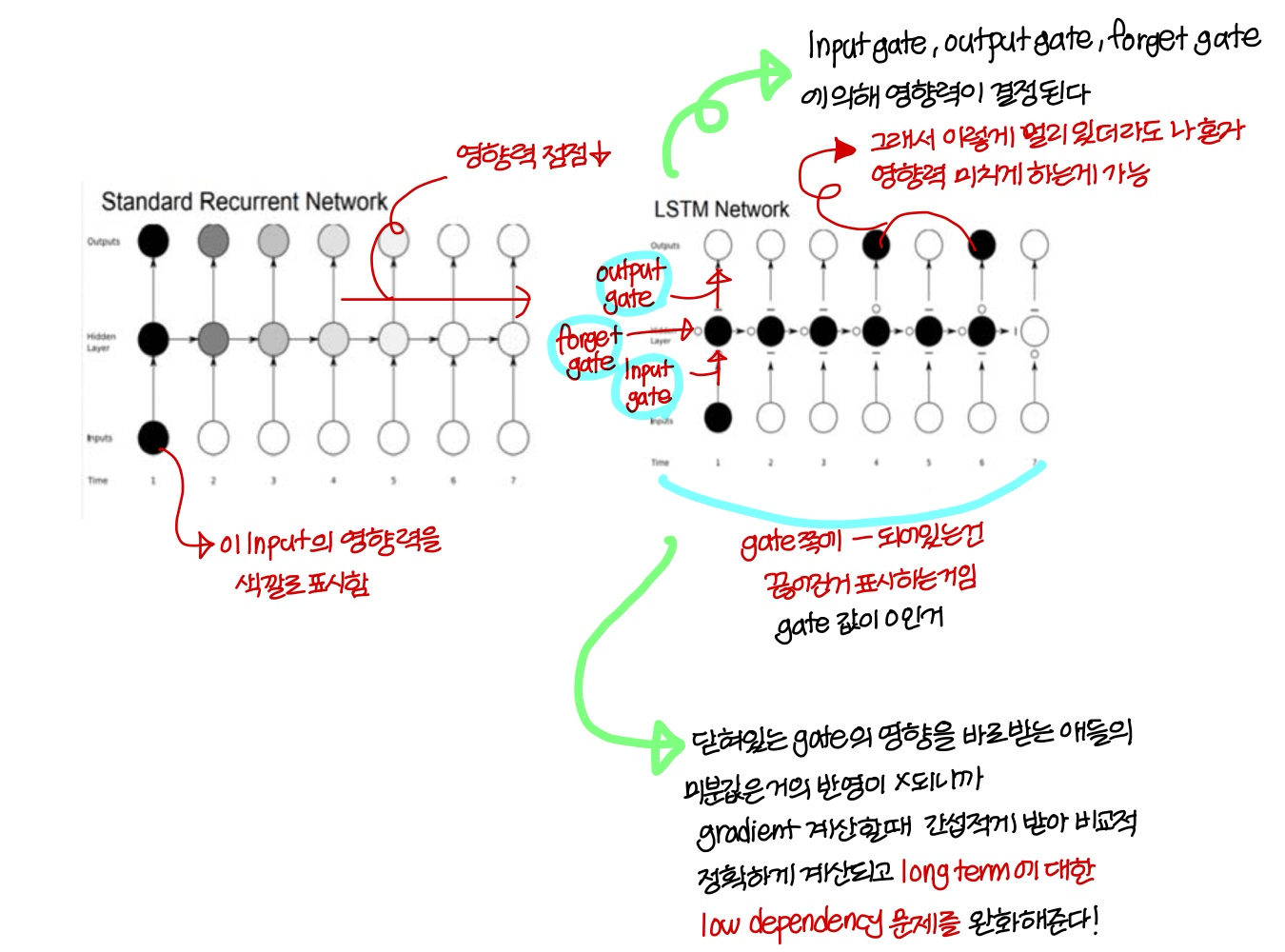
Summary
- RNN은 time step 간의 state 정보를 maintain하여 variable length의 input과 output을 다룰 수 있음
→ 즉, time-series data를 처리할 수 있다!
- Various Input-Output 시나리오
→ one to one
→ mul to one
→ one to mul
→ mul to mul
- Vanilla RNN은 vanishing/exploding gradient problem을 가지고 있었는데 이이 LSTM에 의해 개선됨
- exploding gradient 문제는 LSTM 말고 gradient clipping 방법으로도 개선할 수 있음 (근데 잘 안씀)
Uploaded by N2T