
Part1 - Q learning
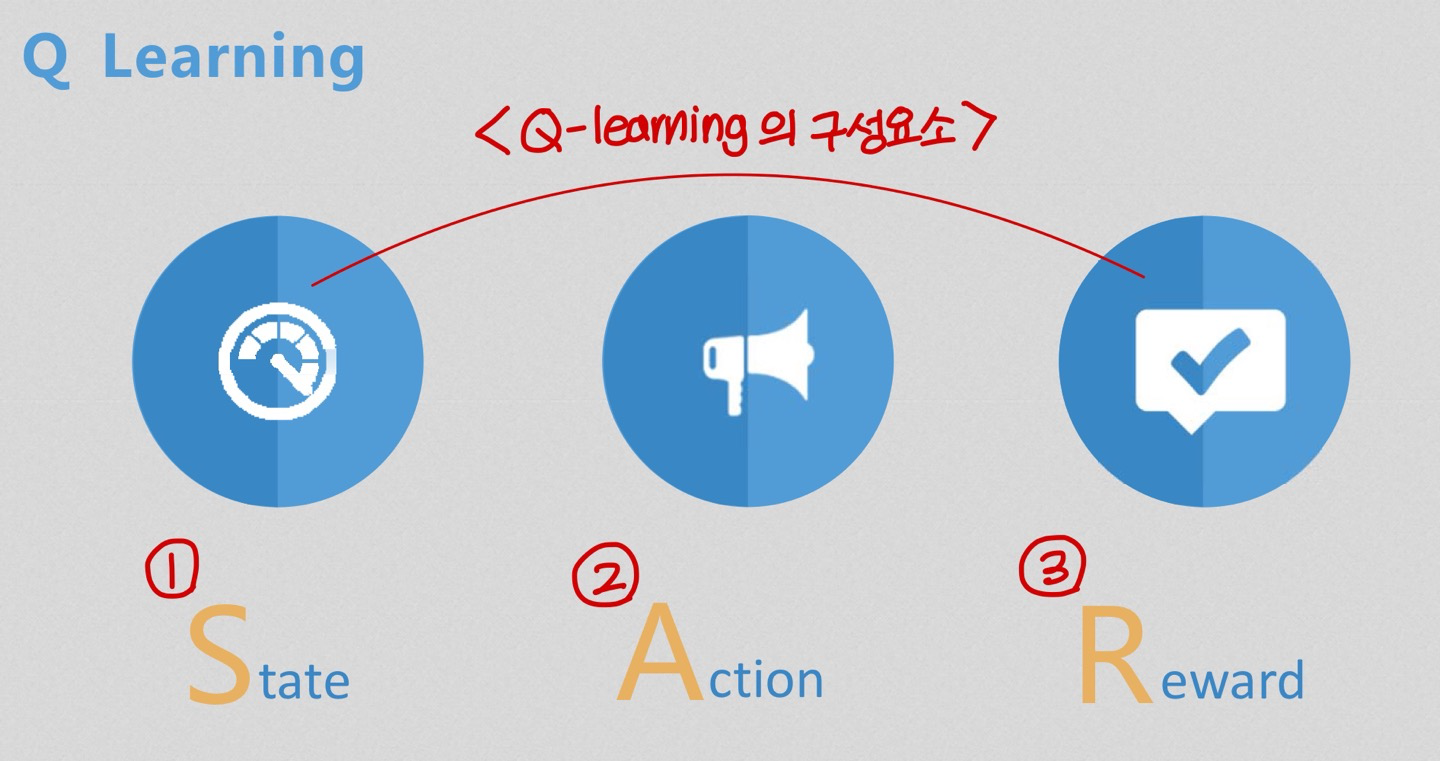
Q learning

Context
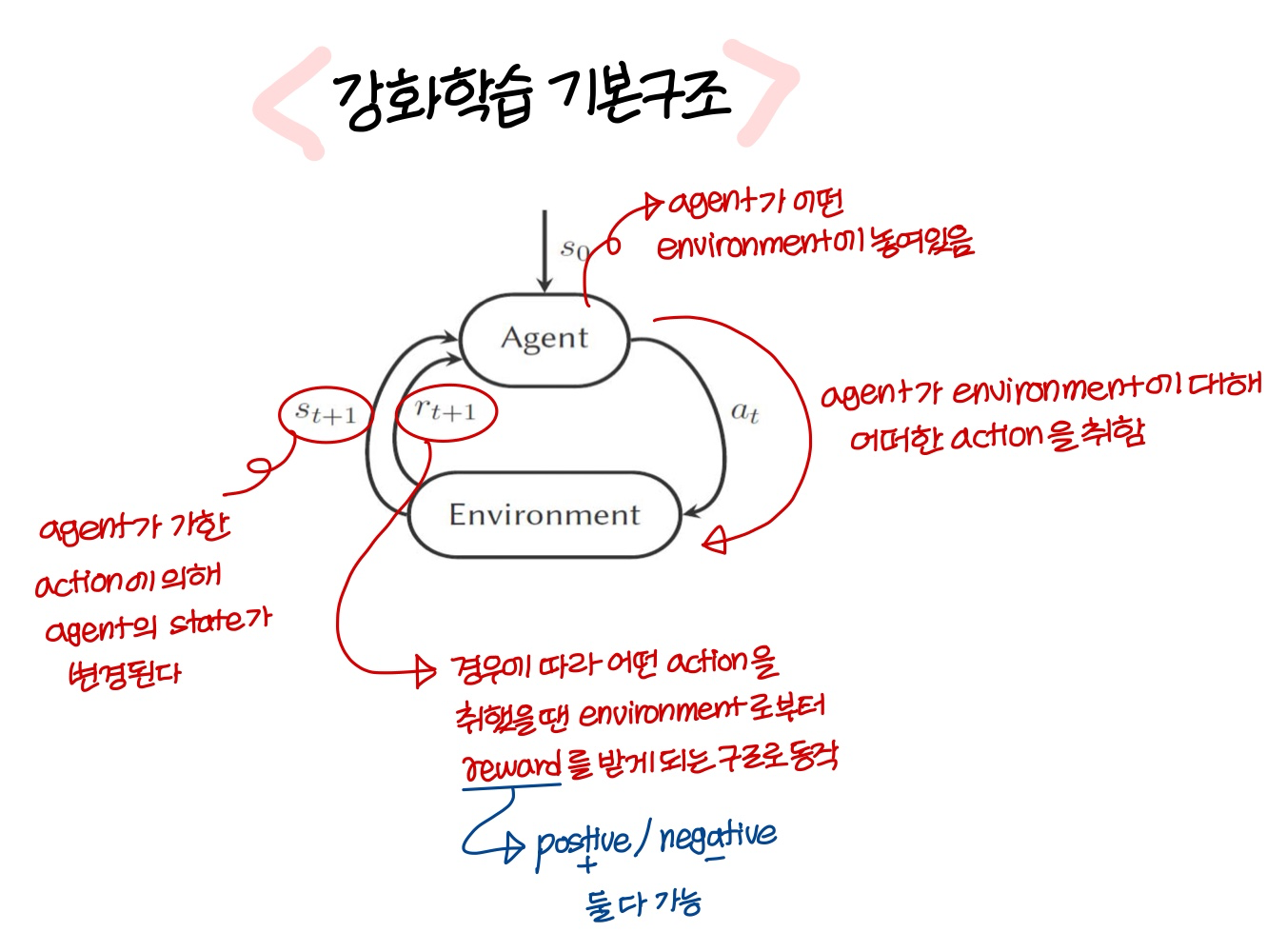
Reinforcement learning
- 2개의 function이 있음
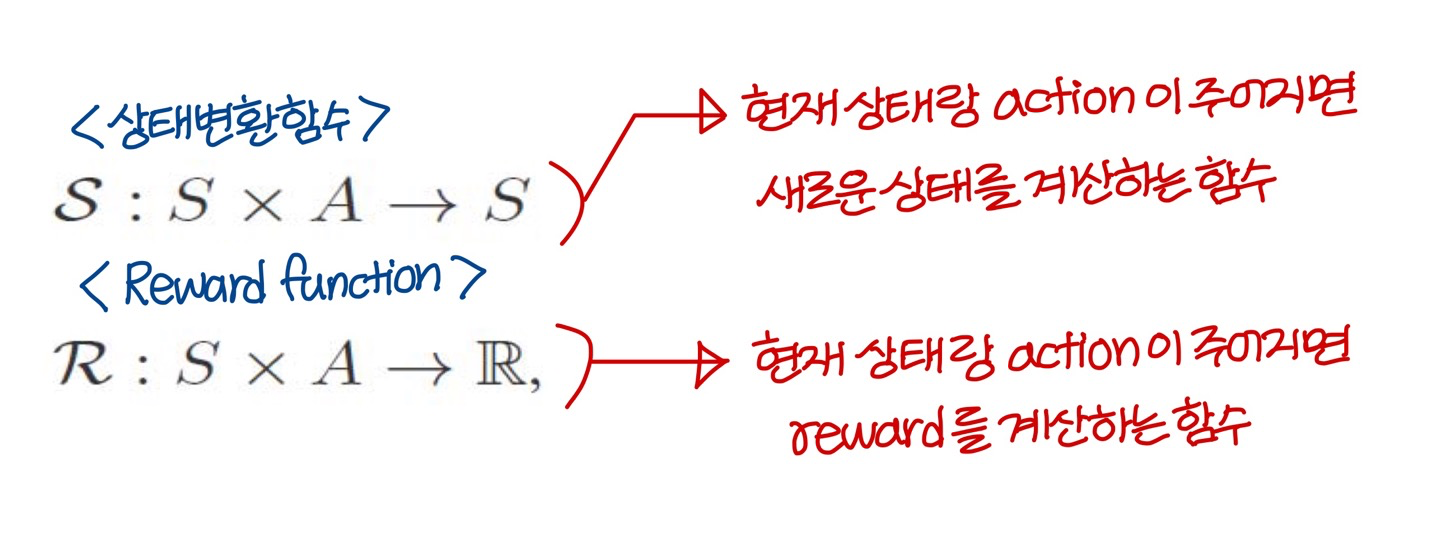
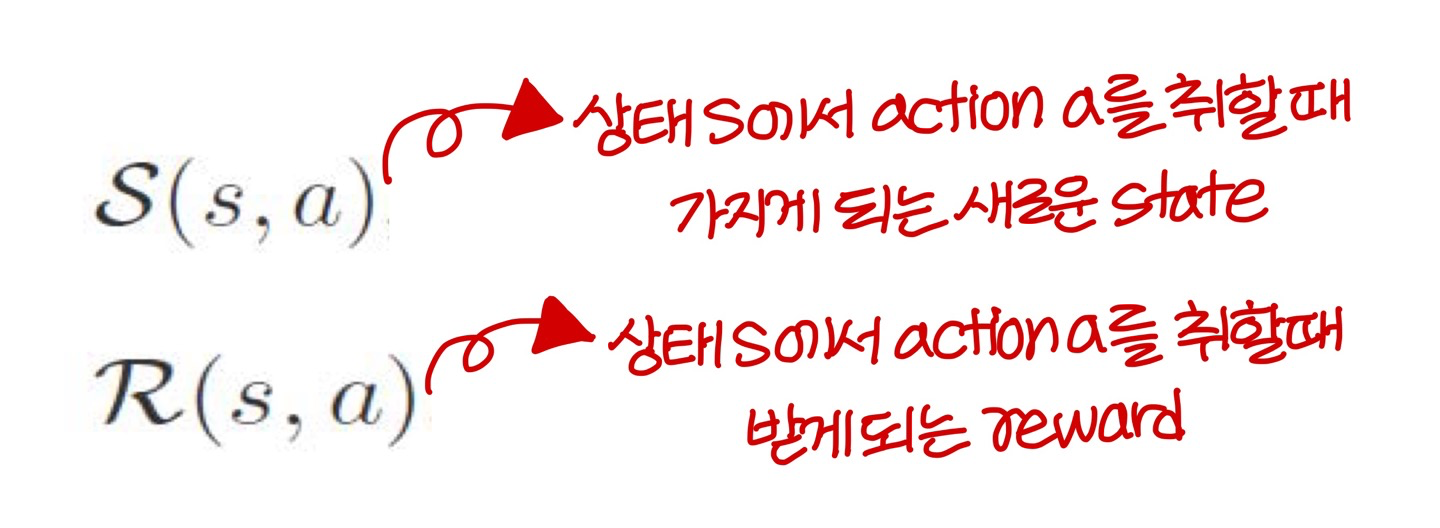
- 위의 함수를 사용해 다음과 같이 표기함
- 목표: 미래 보상의 기댓값을 최대로 하는 action을 선택하는 policy function을 학습하는거!
→ policy function은 이렇게 표기함
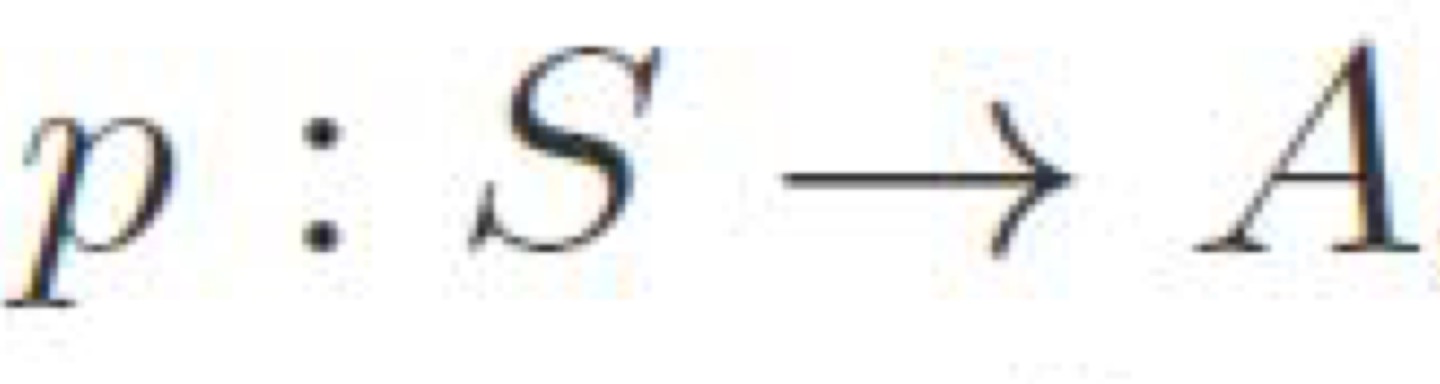
Cumulative reward metric
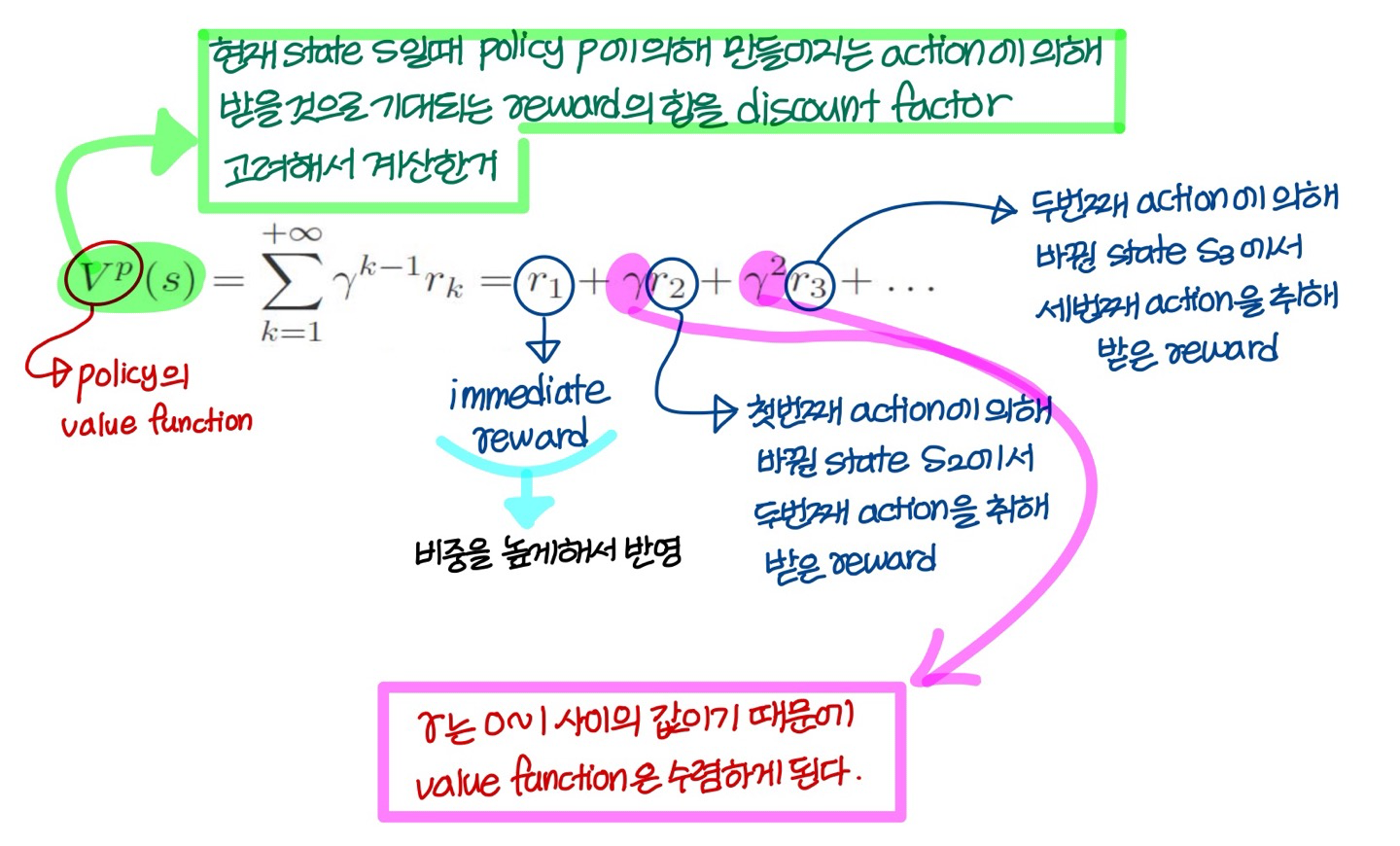
policy의 value function 정의
Q function
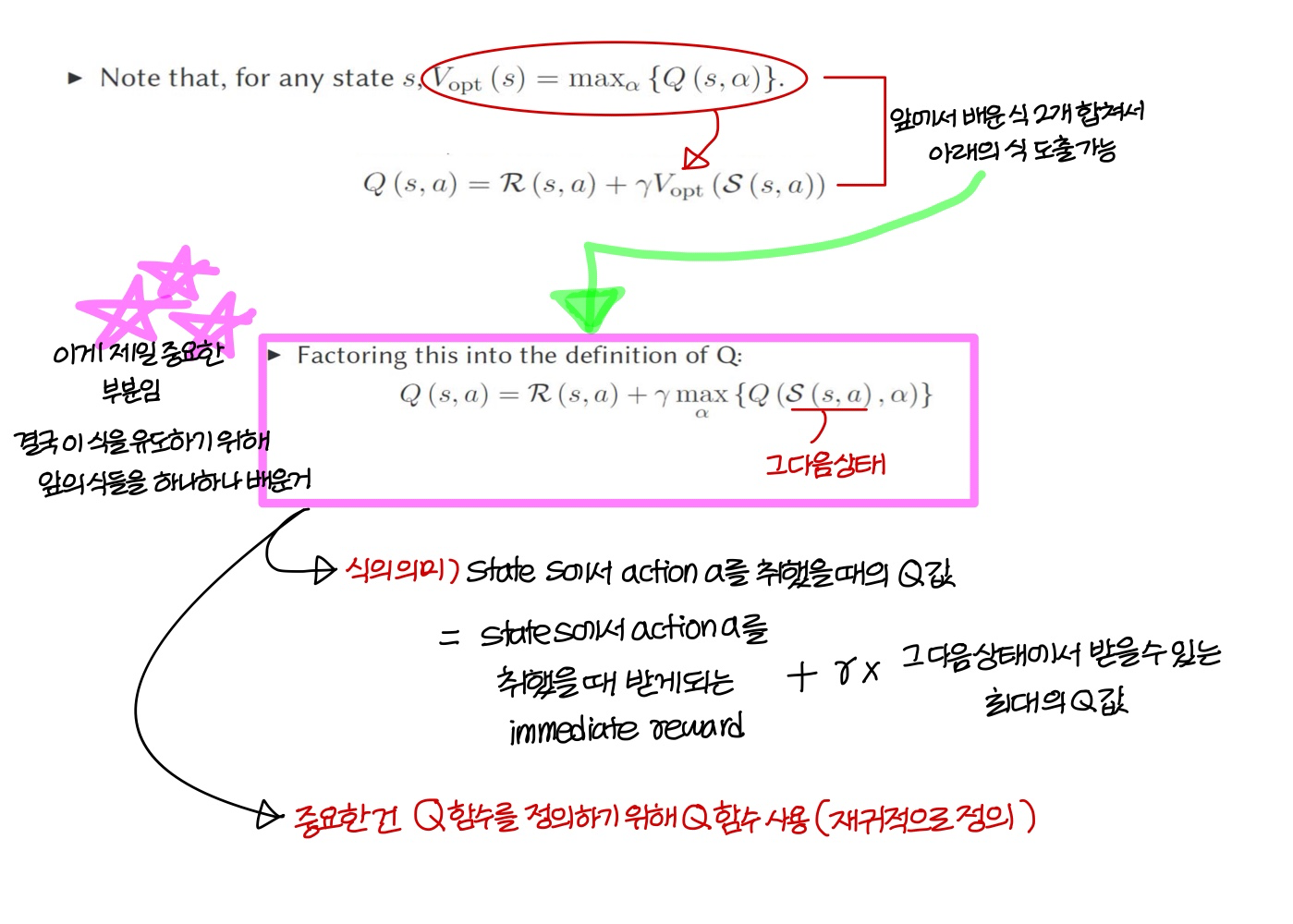
optimal policy 정의

Q function 정의

→ 는 action 취하자마자 튀어나오는거니까 값이 명확한데
→ 이건 값을 명확하게 구할 수 있지 X

Towards an iterative method
→ 정확하지 않은 초기값을 쓰더라도 반복적으로 수행하다보면 정확한 값으로 수렴된다!

Q-learning


Exploration vs exploitation

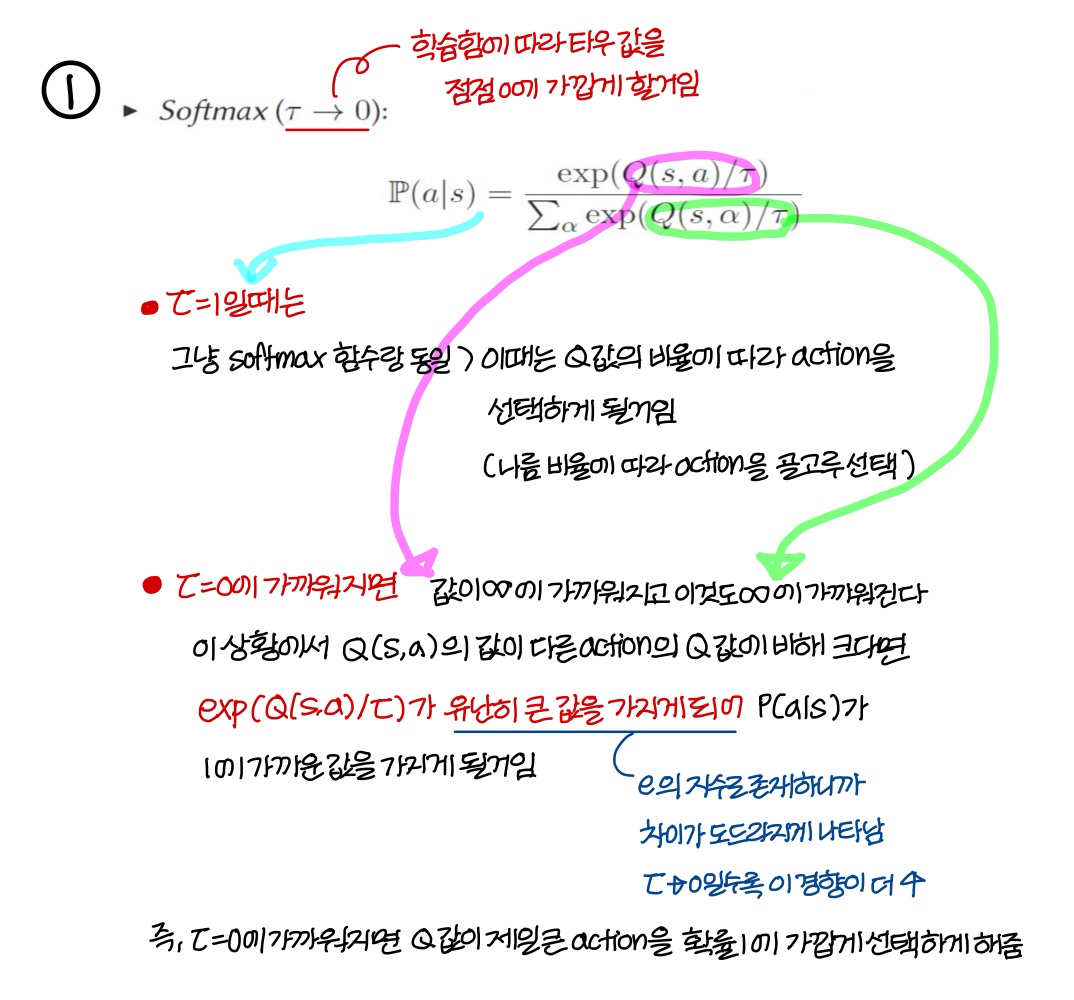
→ 위의 설명처럼 처음엔 exploring 나중에 exploit을 하는 방법 중 가장 common한 approach 2개: Softmax, ε-greedy
1) Softmax
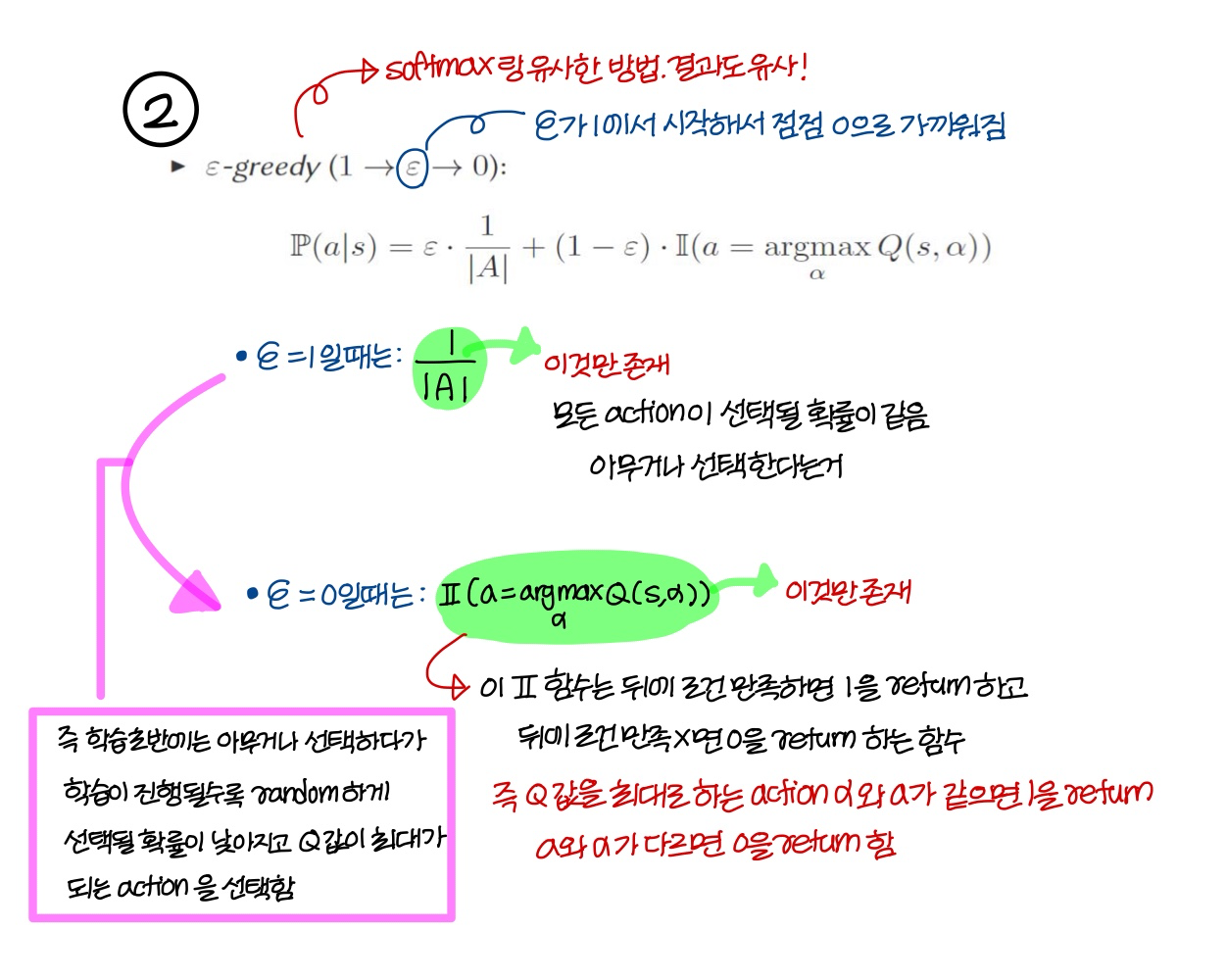
2) ε-greedy
Q Learning: Another Update Formula
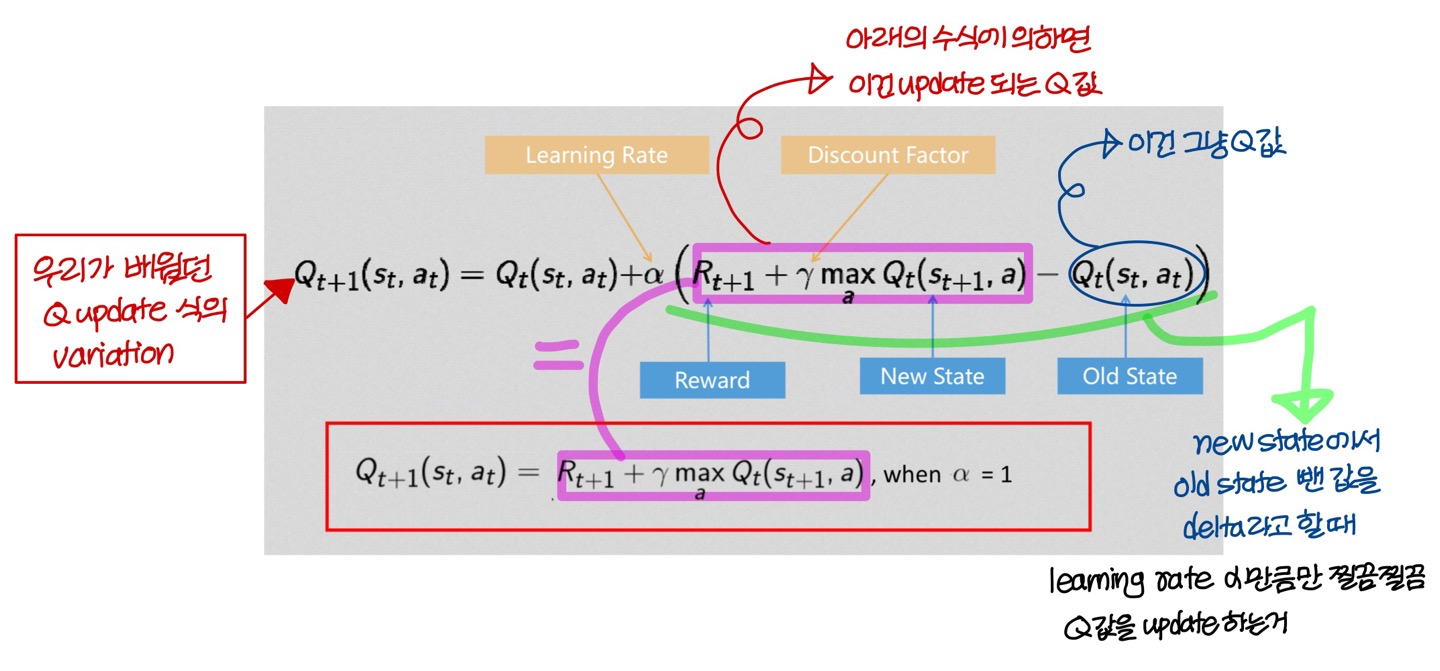
- 위에처럼 variation한 식을 쓸 때도 있고, 아래의 식을 쓸 때도 있음
어떤 논문에서는 위에 식을 쓰고 어떤 논문에서는 아래의 식을 쓴다.
- 일반적인 neural net에서는 learning rate가 포함되어 있는 위의 식을 더 많이 사용한다
Part 2 - Deep Q learning
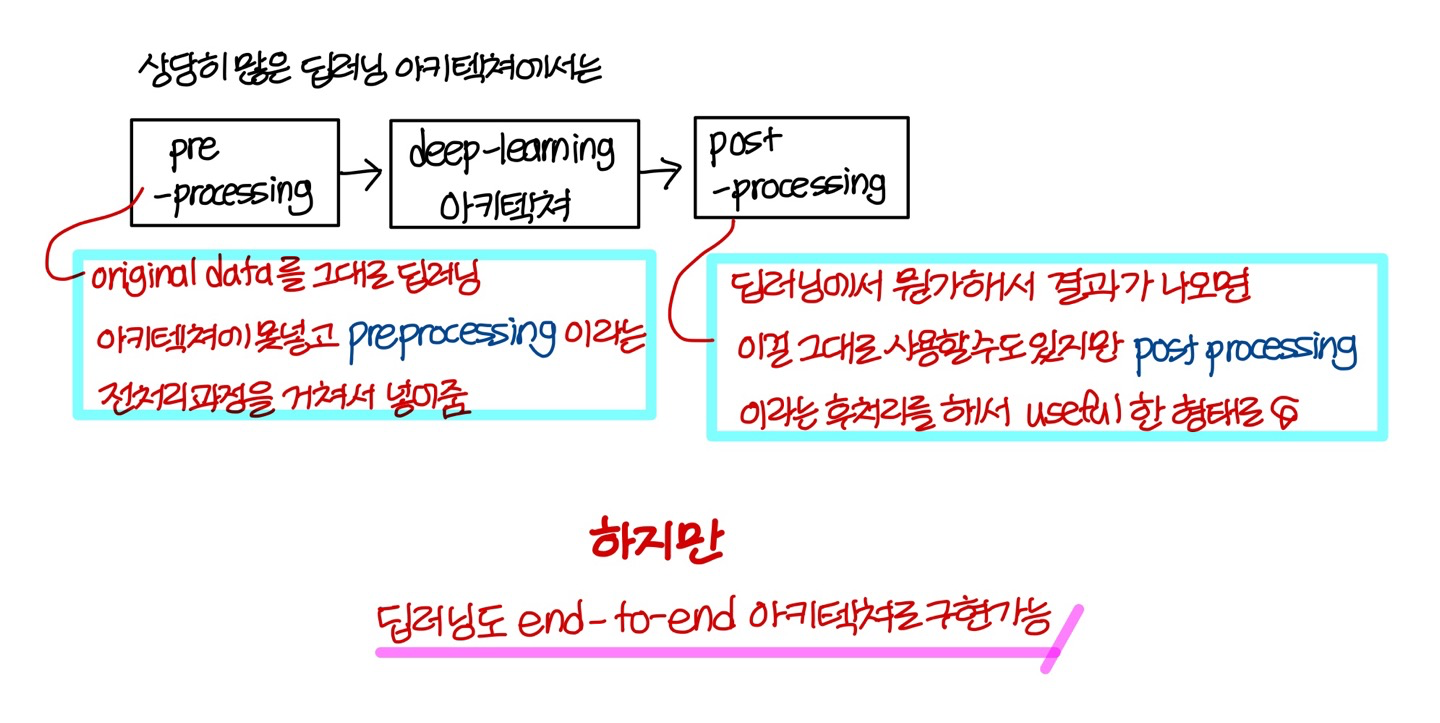
Traditional Cooking
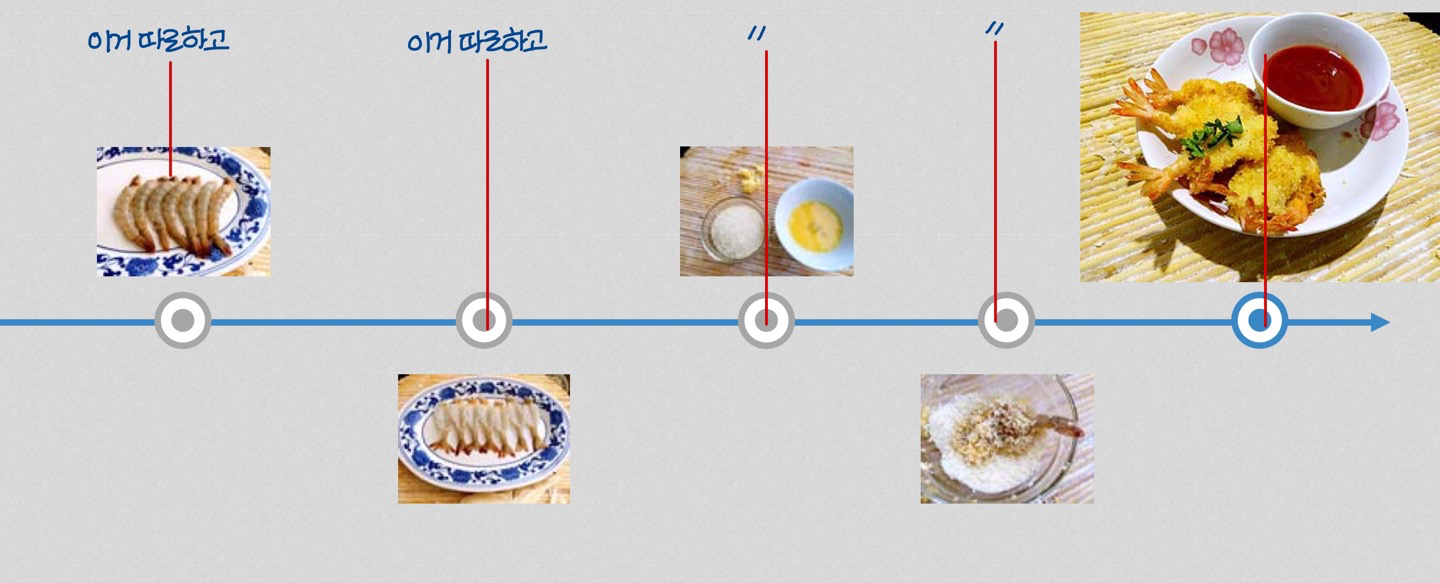
→ traditional cooking에서는 각각의 과정을 다 따로따로 진행함
End-to-End Cooking
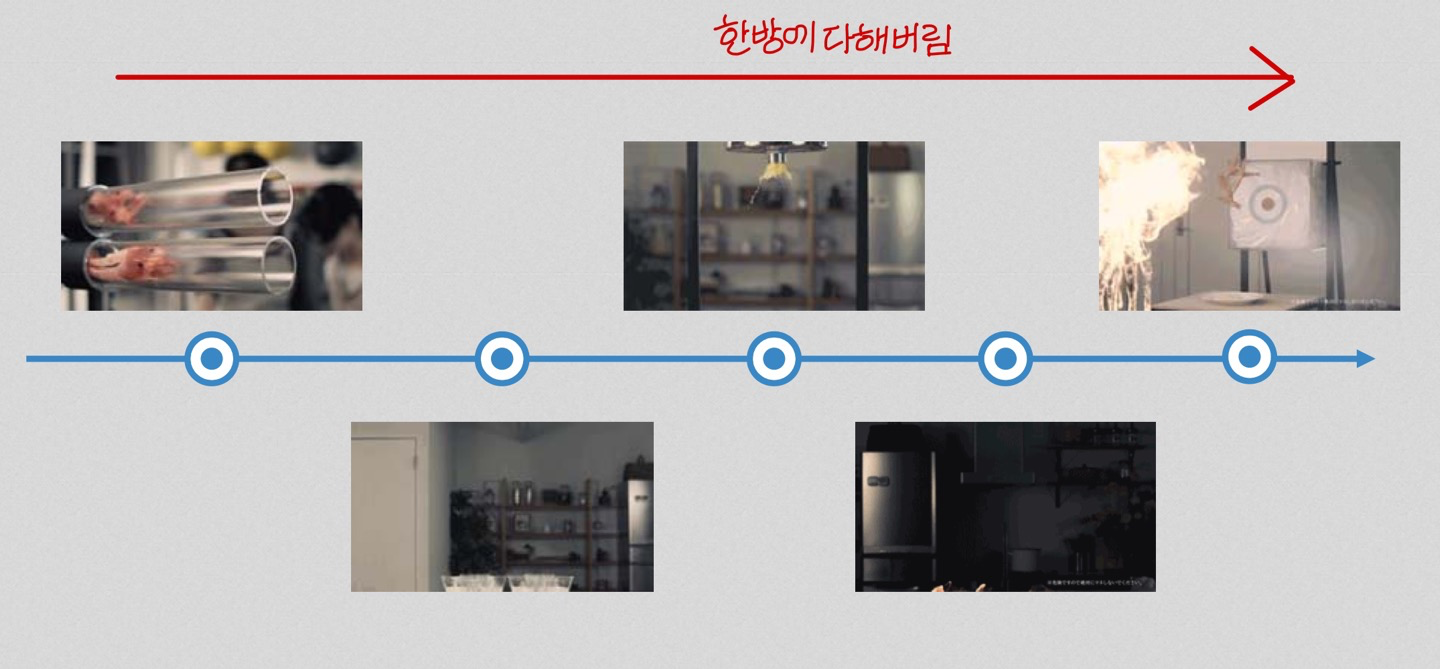
→ 이건 각각 따로 하는게 아니라 한방에 다해버림
이렇게 한방에 다 해버리는 방식을 end-to-end 방식이라고 부름
End-to-End Deep Q Learning
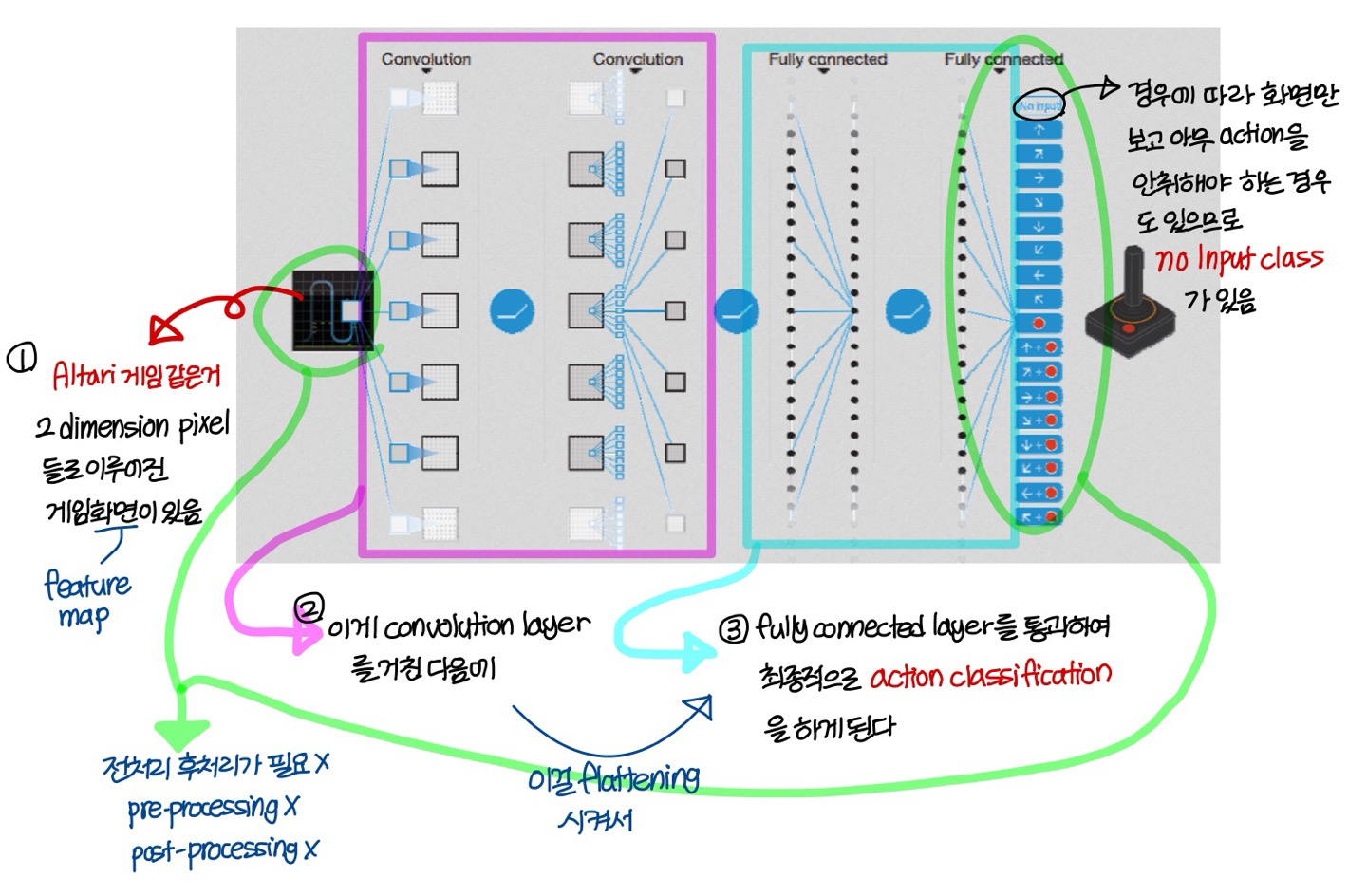
Playing Atari
→ 이 게임을 사람을 능가하게 play 할 수 있는 인공지능을 end-to-end deep Q learning으로 만들어보임
→ Atari를 play 할 수 있는 인공지능을 예로 deep Q learning을 설명할거임
Setup
- Input:
초반에는 RGB pixel matrix들을 사용함 (즉, pixel matrix 3개 사용)
→ 그러다가 이미지를 흑백(gray scale)로 바꿔서 pixel matrix 1장 쓰는 형태로 수정함
→ frame 1개에 대한것만 넣어주는게 아니라 최근 frame 6장 넣는 형태로 수정
💡즉, Input으로 gray scale로 표현된 pixel matrix 6장 넣어줌
- action:
아까 봤듯이 joypad input (여기에는 no action도 포함됨)
- reward:
화면에 뜨는 score 증가하면 +1점, 감소하면 -1점
Q-learning, revisited
- Atari game을 Q-learning의 형태로 학습시키려고 했는데 문제가 있음
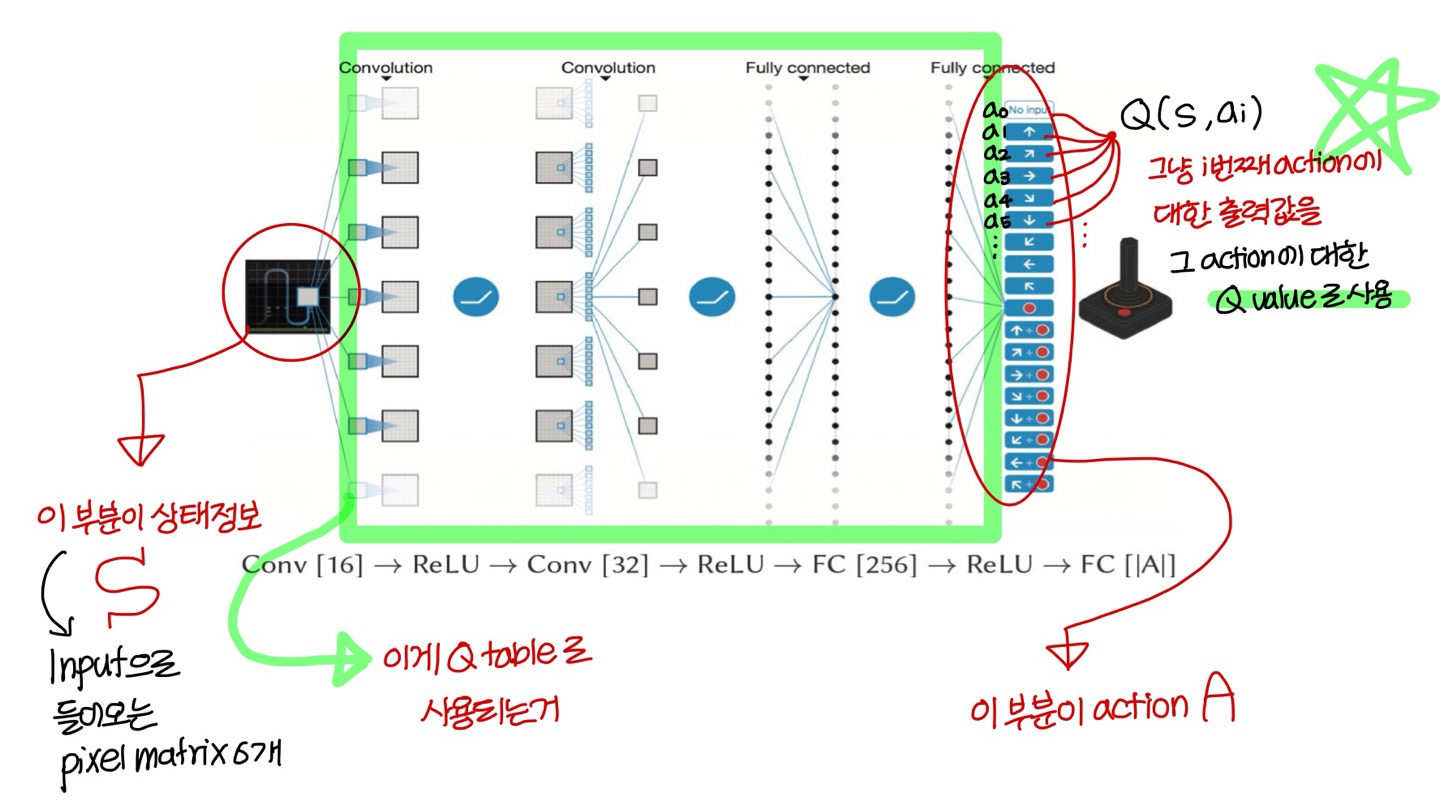
Major Issue: 전체 Q table을 메모리에 다 store할 수가 없음
→ Q learning에서 Q table을 approximation하기 위해 deep neural network를 쓸 때, 이 deep neural network를 “Deep Q-Network”라고 부름
Deep Q-Network
- Q-table 대신 convolution network랑 fully connected network 연결한 형태의 deep neural network 사용함
Deep Q-learning(? 좀 헷갈린다. 학습하면서 training data를 쌓는거임?)
- 비어있는 replay memory를 initalize한다.
- DQN(deep Q-network)를 random small weight로 initalize해줌
- 그 이후에 다음의 과정을 반복

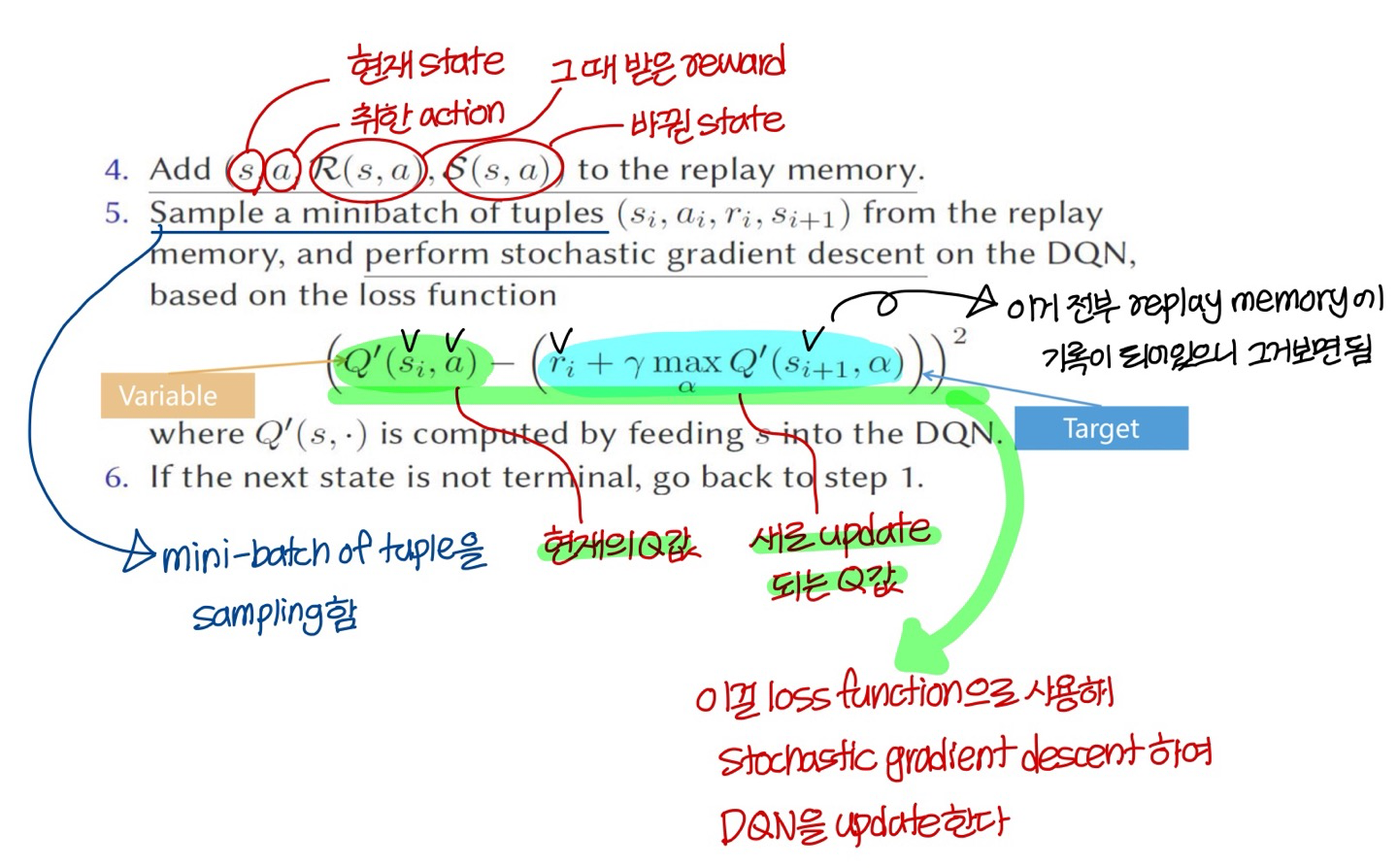

- 이렇게 학습을 진행할 때의 장점:
training data를 따로 얻을 필요가 없음
그냥 게임 잘하는 사람 게임하게 놔두면 엄청나게 빠른속도로 training data가 축적되니까 무진장 얻어낼 수 있음
Result Analysis
Part3 - Discussion
Leveraging GPU (GPU의 활용)
- 지금까지 논의한 neural network 아키텍쳐는 실제로도 그대로 많이 사용함
→ computer vision 같은 분야에서 특히 많이 사용!
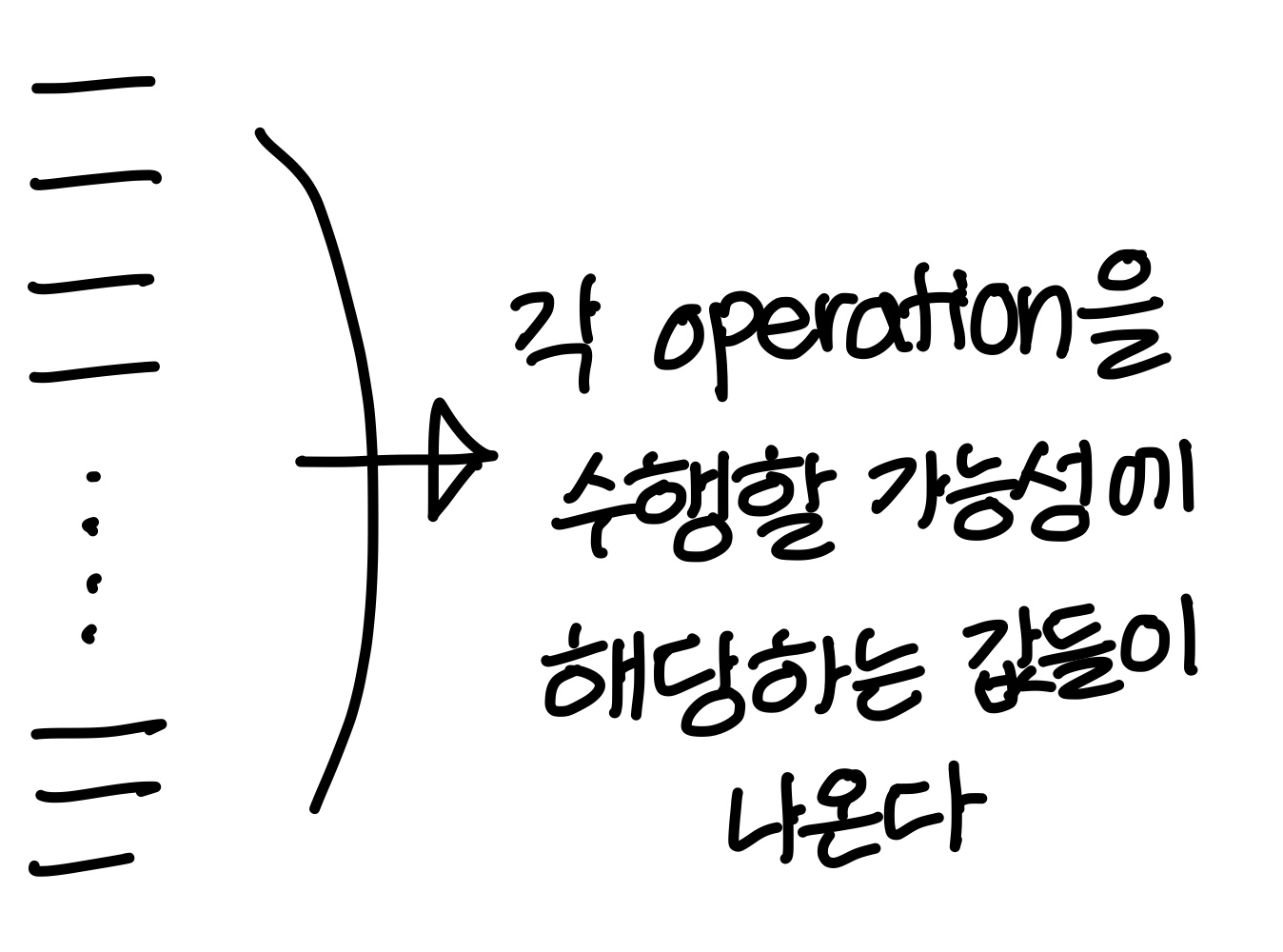
- neural network의 opeartion들은 matrix opeartion들로 구현되어 있는데
이 matrix opeartion은 SIMD instruction 사용하면 speed up 시킬 수 있음
- DQN은 deep learning framework(TensorFlow, Torch…)같은거 쓰면 GPU를 아주 효율적으로 잘 동작하게 만들 수 있음
Double Q-learning
- 기존 Deep Q learning의 문제점
- Deep Q-network 수렴하기 전에는 다른 neural network랑 마찬가지로 random하게 initalize 되어 있음 (성능 좋지 않음)
- 이 Deep Q-network 사용해서 action selection
→ 이 action을 이용해서 deep Q-network의 weight 값 조정
→ 또 같은 Q-network 사용해서 action selection → 이 action 사용해 deep Q-network 조정
- 이런 일이 반복되다 보면 action selection과 evaluation이 같은 테이블을 사용하기 때문에 action value가 overestimate 될 가능성이 있음
→ 다른 action들을 많이 선택해서
여러 action들에 대한 Q 값을 골고루 update 시켜야하는데선택이랑 학습을 같은 deep Q-net을 사용해 하다보니
선택되는 action들만 정교하게 학습되는 문제
- Double Q-learning
→ 두가지 형태의 Deep Q-network를 사용함
→ 이 두가지의 Deep Q-network가 두가지 역할을 번갈아 가면서 수행함
한 Deep Q network에서는 action을 selection하는데 쓰고
한 Deep Q newtork에서는 selection된 action을 사용해서 weight를 update하고
(영어 표현: one used for evaluation, and the other for selection)
→ 이렇게 두 Q-network가 선택화 학습을 번갈아가면서 서로를 학습시킴
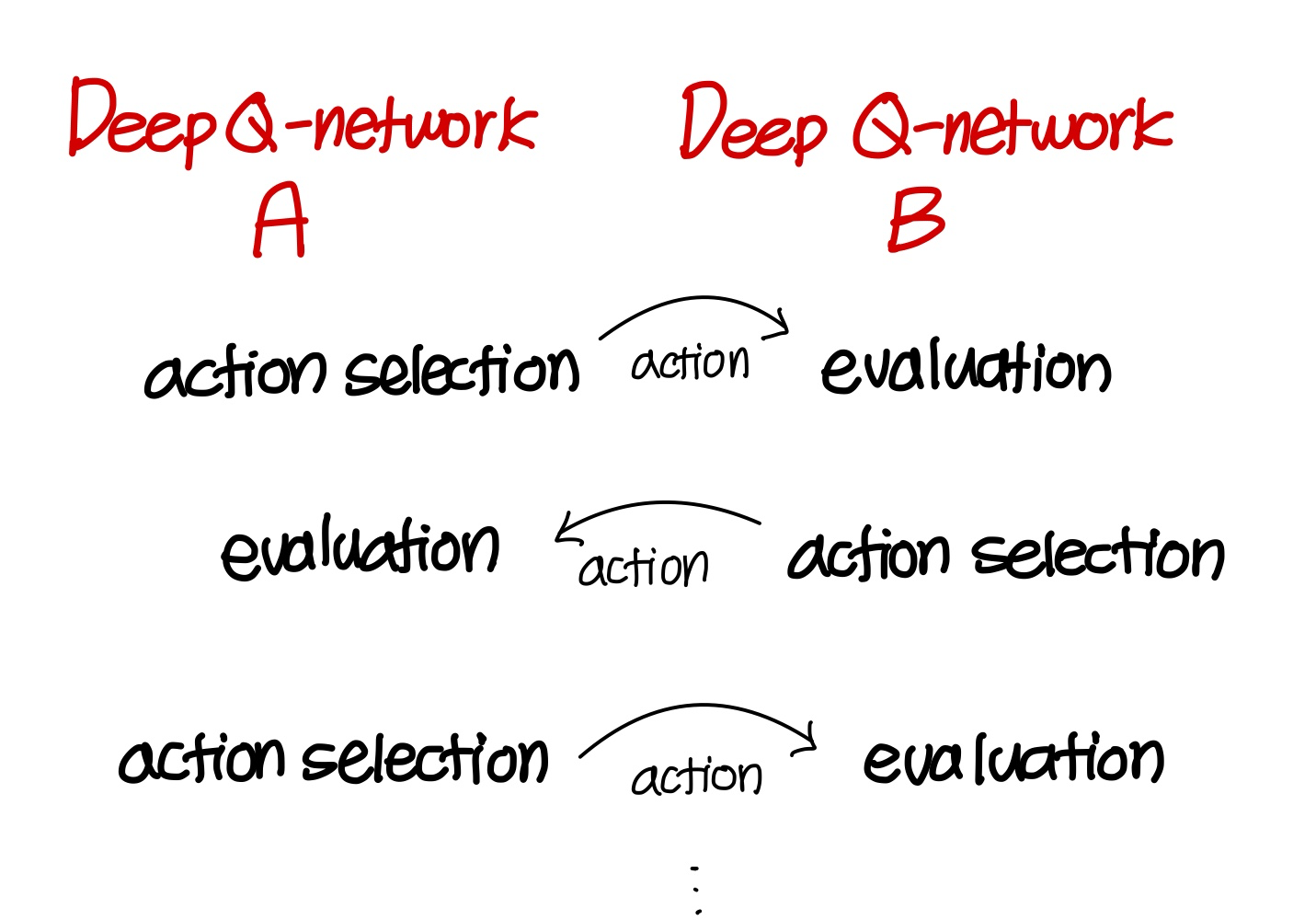
→ 이렇게 되면 자꾸
선택되는 action들에 대해서만 정교하게 학습되는 overestimate 문제를 완화할 수 있음
Ideas
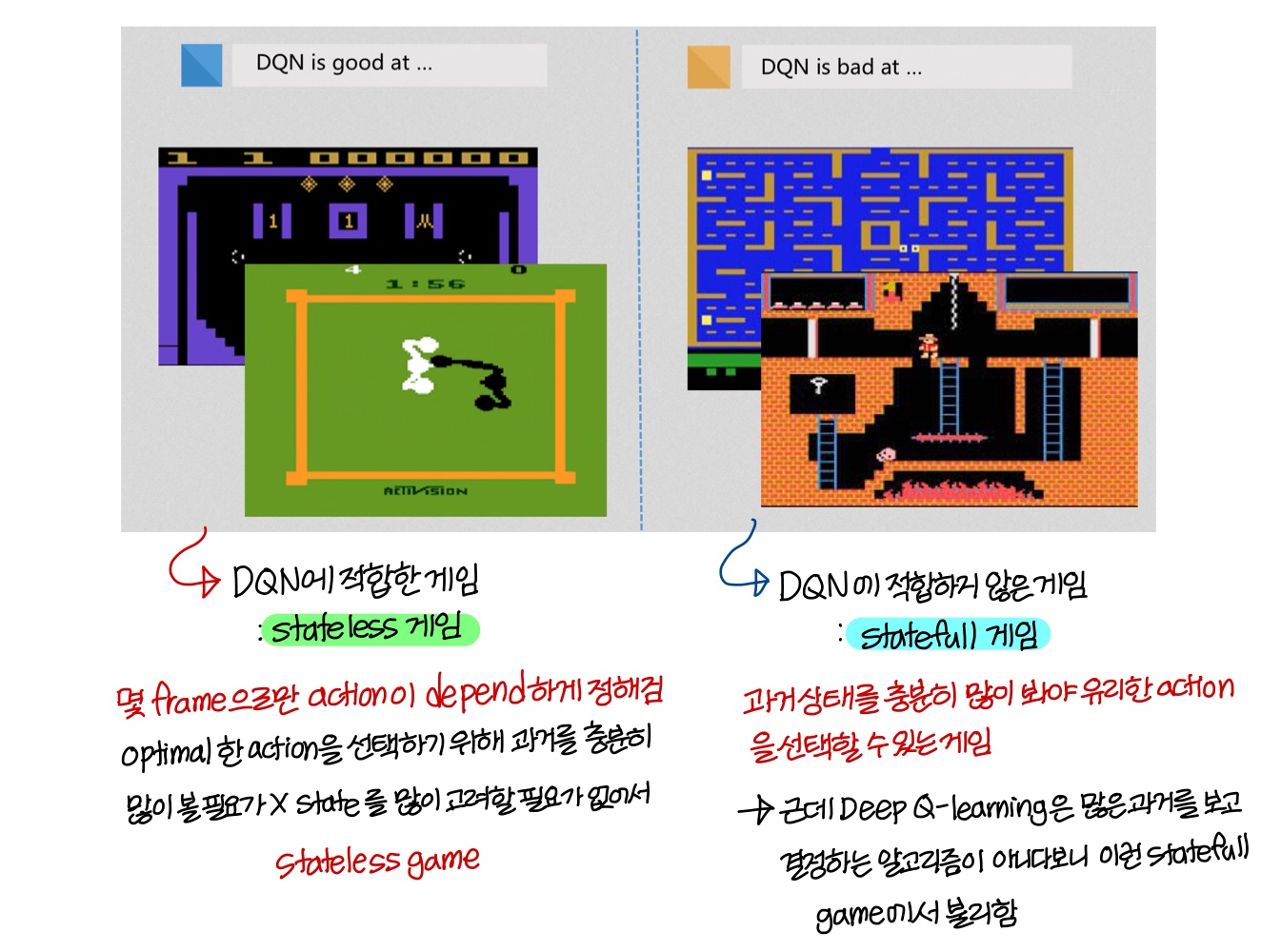
- 우리는 이때까지 화면 전체 frame 다 넣었었는데 화면 상에 중요하게 나타나는 부분(”most important regions”)을 집중적으로 학습시킬수도 있음
- statefull한 게임 같은 경우:
convolution net 뒤에 fully connected가 아니라 RNN 연결해서 최종적으로 action 뭐 선택할지 판단한다면 성능 괜찮게 나올수도 있음
이렇게 하면 꽤 과거 정보까지도 살펴볼 수 있으니까
- sound information까지도 결합해서 학습시킬 수 있음
- 위의 내용들은 원래 구상만 하고 실제로 구현이 어려웠는데 최근에 GPU의 성능이 좋아지면서 위의 시도들이 가능하게 되었음
Final Wrap-Up

training data를 엄청 많이 구할 수 있다!
→ 게임 잘하는 사람의 게임 log 기록을 쭉 남기면 그걸로 training data 해결

LSTM을 fully connected 대신에 붙이게 되면
Long term dependency가 있어야 잘할 수 있는 게임(RNN 붙여서 하는게임)
같은거에서 잘 이용할 수 있음
Uploaded by N2T