
728x90
728x90
Mixture of Expert model
Mixture of Experts model는 ME 또는 MoE model이라고 부른다.
복잡한 문제를 최대한 단순하게 분리하며, 이렇게 단순화된 해는 합쳐져서 최종적인 해를 산출하는 분리와 해결의 원리를 이용한다.
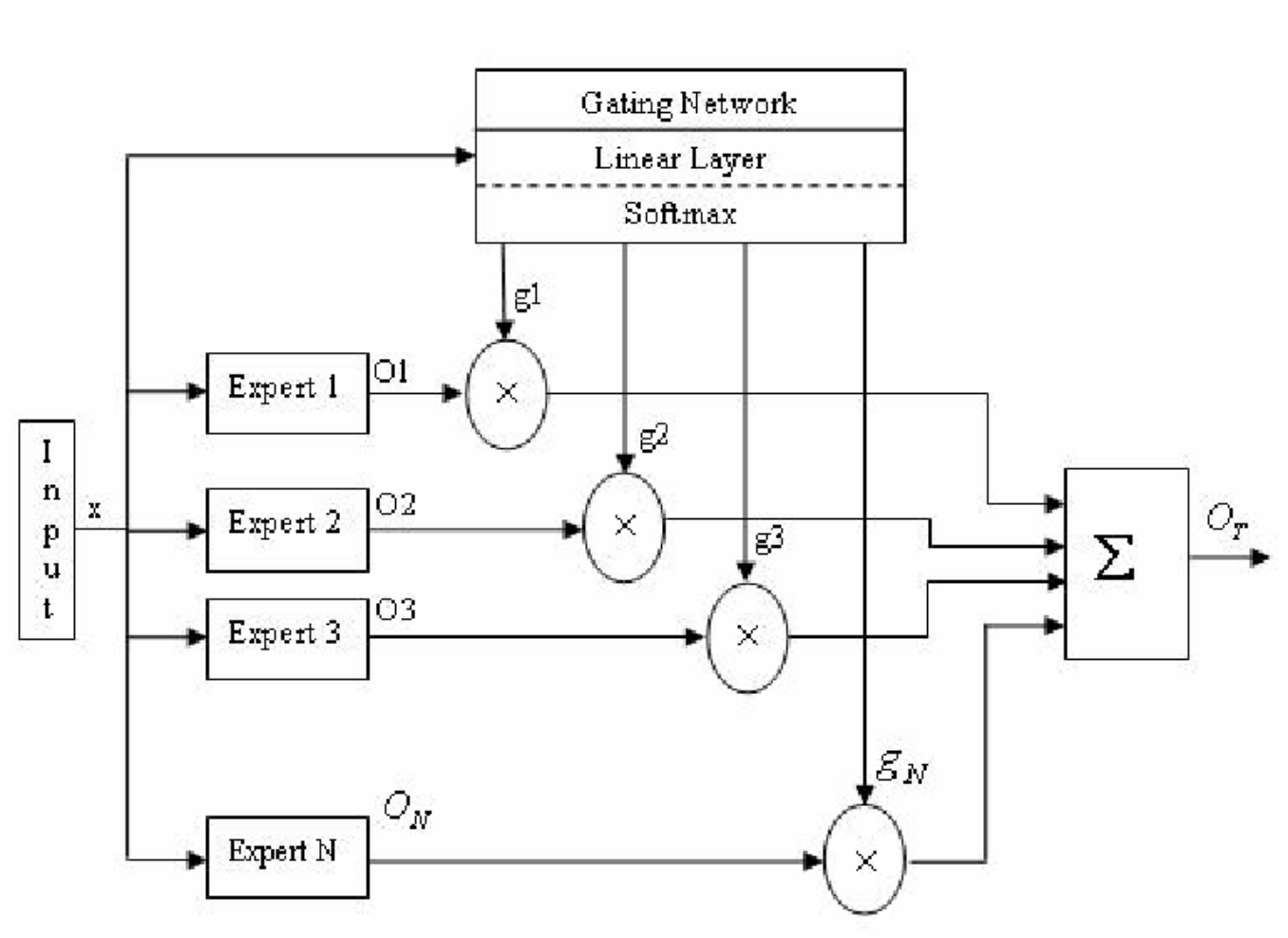
각 expert network는 Input Vector에 대한 Output Vector를 생성한다.
Gating Network는 Input vector x를 받아 input space에서 각 지점으로 분할하는 스칼라 결과를 생성한다.
Input Network에서 Expert Network에 대한 확률로서의 linear combination을 제공하기 때문에 ME network의 최종 결과는 expert network들에 의해 생성되는 모든 Output Vector의 weighted sum으로 나타난다.
이해를 돕기 위해 아래의 Mixture of experts 수식을 보자.
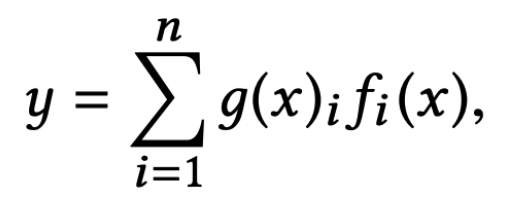
g(x)_i: softmax의 확률(i번째 expert를 몇 % 믿을지)를 나타낸다
f_i(x): i번째 expert network의 output 을 나타낸다.
Reference
https://koreascience.kr/article/JAKO201435648478490.pdf
728x90
728x90
'수업정리 > 딥러닝 이론' 카테고리의 다른 글
| 딥러닝 수업정리) 03_Shallow Neural Network (2) | 2022.12.23 |
|---|---|
| 딥러닝 수업정리) 02_WramingUp-Logistic Regression (4) | 2022.12.23 |
| 딥러닝 수업정리) 01_Quick Introduction (2) | 2022.12.23 |
| CVAE 설명 (0) | 2022.07.20 |
| VAE 설명 (0) | 2022.07.19 |