
들어가기에 앞서
* AE와 VAE는 이름이 유사하지만, 수학적으로는 아무런 관련이 없음
* VAE는 Generative model임!
* Generative model?
training data가 주어졌을 때 이 data가 sampling 된 분포와 같은 분포에서 새로운 sample을 생성하는 model
즉 p_model(x)가 최대한 p_data(x)에 가깝게 만드는 것이 목표이다.
따라서 얼마나 기존 모델과 가까운 것인가에 대한 지표를 만들어야 하며 그 차이를 최소화하는 방향으로 업데이트함
VAE란?
VAE는 Input image X를 잘 설명하는 feature를 추출하여 Latent vector z에 담고, 이 Latent vector z를 통해 X와 유사하지만 완전히 새로운 데이터를 생성해내는 것을 목표로 함.
* 이때 각 feature는 가우시안 분포를 따른다고 가정함
* latent z는 각 feature의 평균과 분산값을 나타냄
* 마치 AE의 decoder처럼 latent vector로부터 이미지를 생성해낸다고 보면 된다.
예를 들어 한국인의 얼굴을 그리기 위해 눈, 코, 입 등의 feature를 Latent vector z에 담고, 그 z를 이용해 그럴듯한 한국인의 얼굴을 그리는 경우를 생각해보자.
* 이때 latent vector z는 한국인의 눈 모양의 평균 및 분산, 한국인의 코 길이의 평균 및 분산,
한국인 머리카락 길이의 평균 및 분산 등의 정보를 담고 있다고 생각할 수 있음
수식을 곁들여 표현하면 다음과 같다.

p(z): latent vector z의 확률밀도 함수, 가우시안 분포를 따른다고 가정함. 즉, latent vector z를 sampling 할 수 있는 확률밀도함수
p(x|z): 주어진 z에서 특정 x가 나올 확률에 대한 확률밀도함수
θ: 모델의 파라미터
VAE의 구조
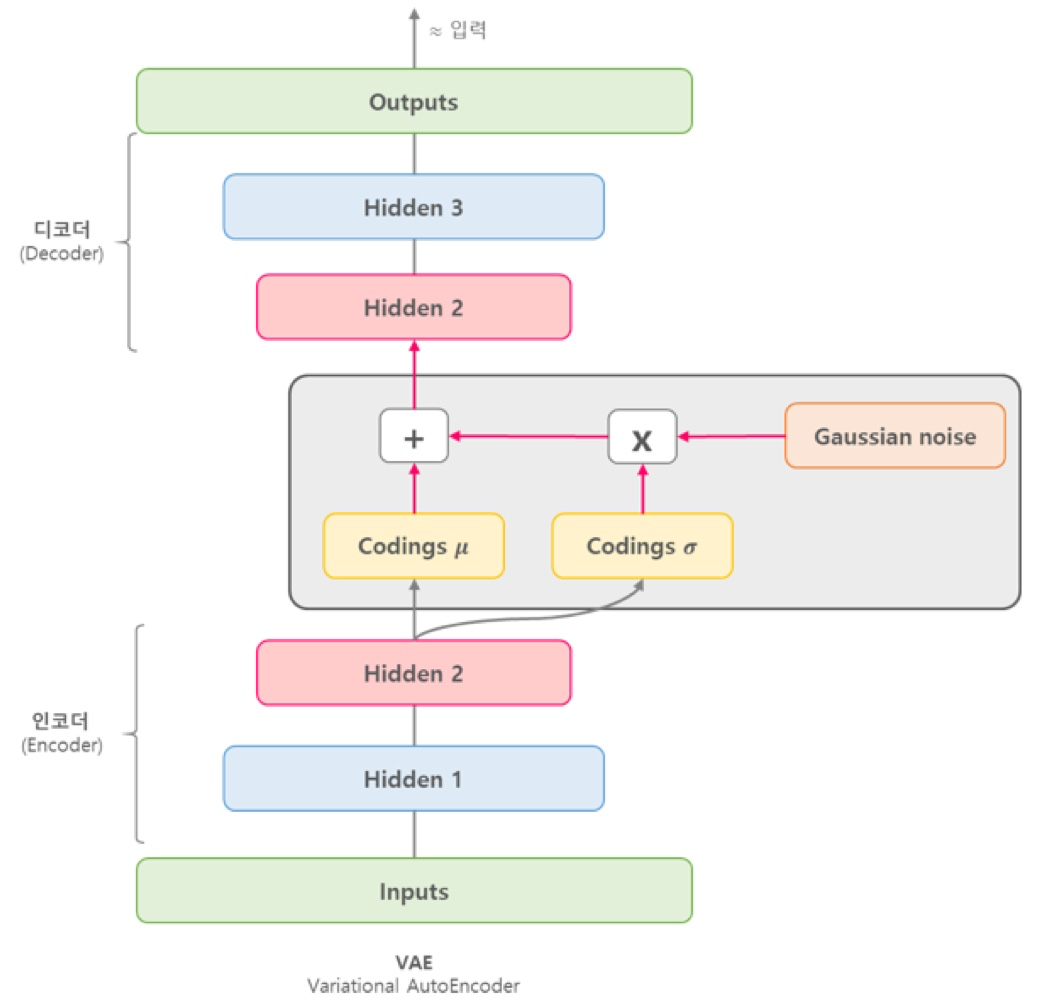
VAE는 Input Image X를 Encoder에 통과시켜 Latent vector z를 구하고, Latent vector z를 다시 Decoder에 통과시켜 기존 input image X와 비슷하지만 새로운 이미지 X를 찾아내는 구조를 가지고 있다.
VAE는 Input Image가 들어오면, 그 이미지에서의 다양한 특징들이 각각의 확률 변수가 되는 어떤 확률 분포를 만들게 된다.
이런 확률 분포를 잘 찾아내고, 확률값이 높은 부분을 이용하면 실제에 있을법한 이미지를 새롭게 만들 수 있다.

VAE의 수식적 증명
모델의 파라미터 θ가 주어졌을 때 우리가 원하는 정답인 x가 나올 확률인 p_θ(x)가 높을수록 좋은 모델이다.
즉 p_θ(x)를 최대화 하는 방향으로 VAE의 파라미터 θ를 학습시키게 된다.
즉, 우리가 VAE를 통해 얻고자 하는건 true parameter θ이다!!!
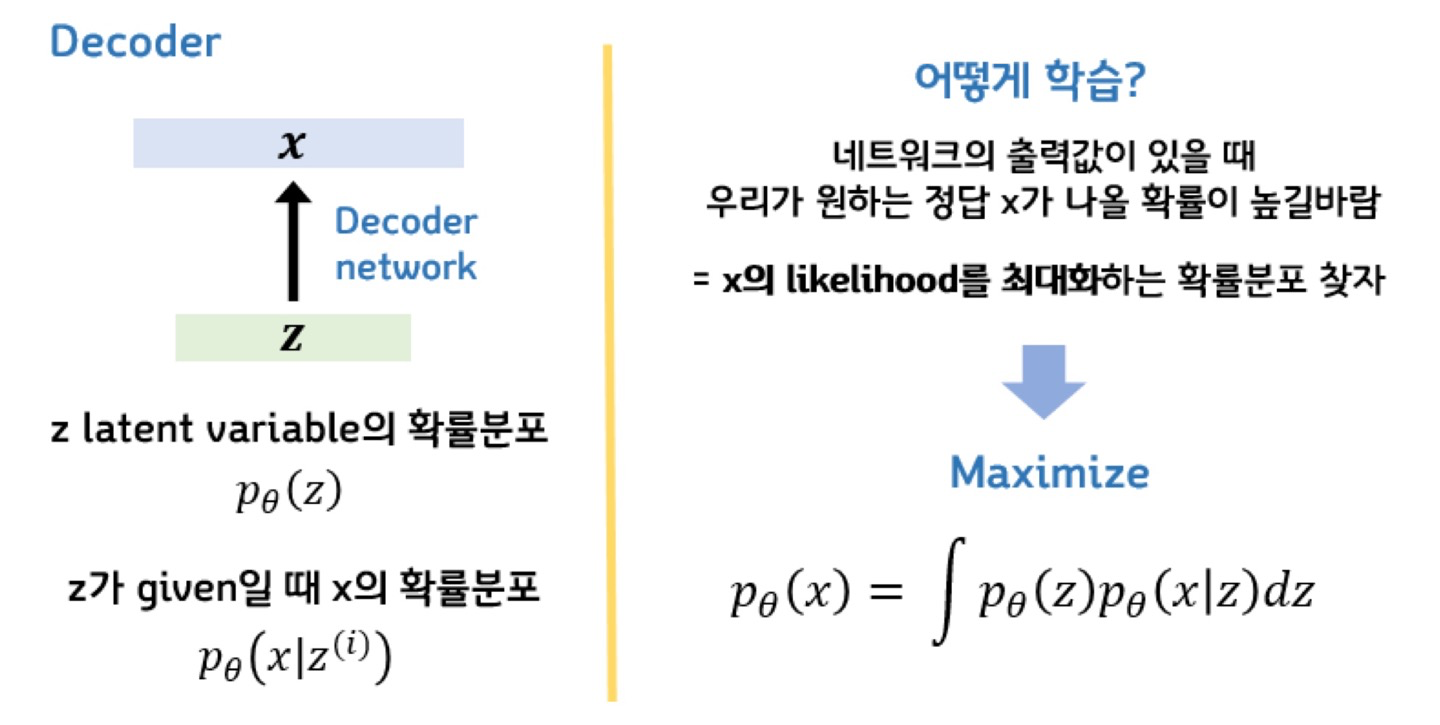
model을 training 시키기 위해 FVBN(Fully Visible Brief Network)를 사용하게 된다.
FVBN은 Generative model을 training하기 위해 사용되는 전략이다.
어쨌든 여기서 알아야하는건 training data의 Likelihood를 최대화하는 모델의 parameter를 구해야하는 것이다.
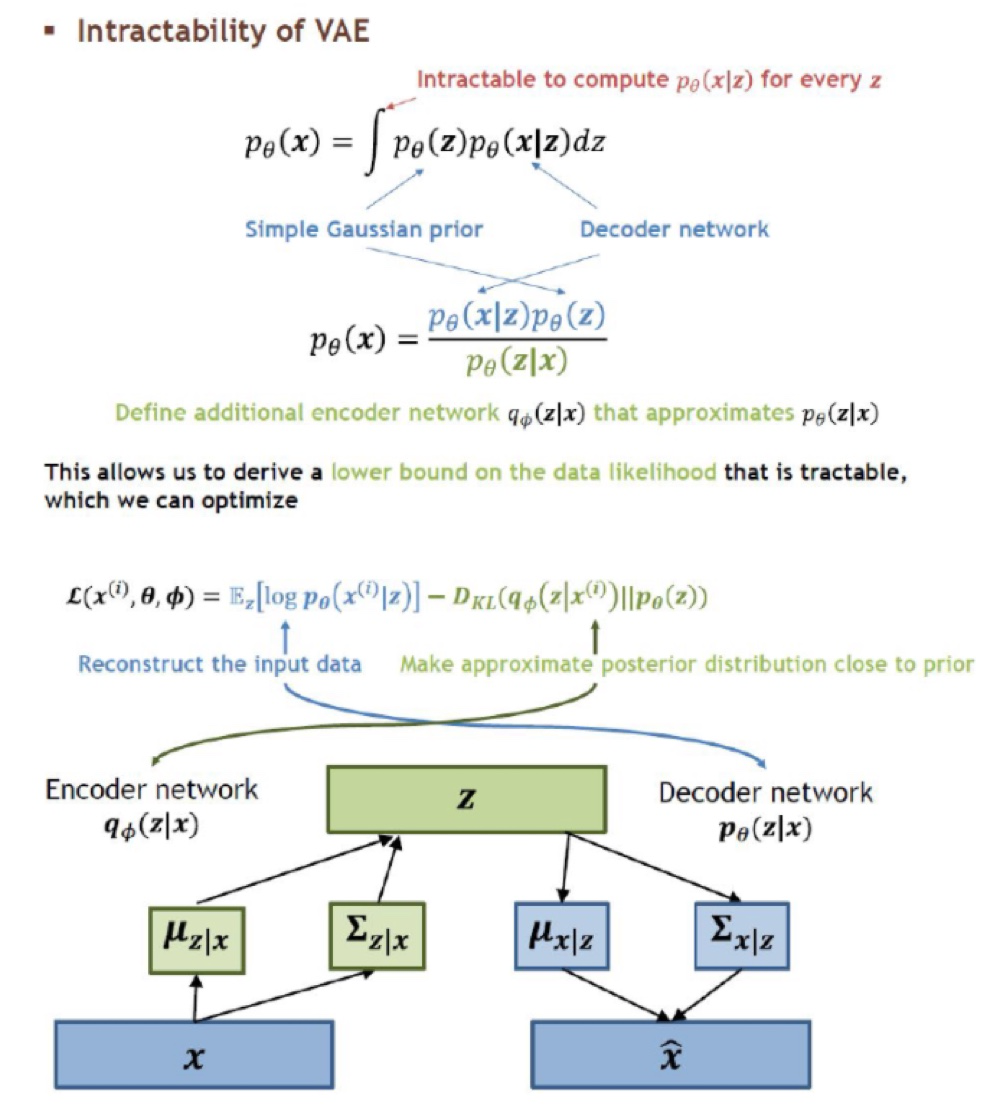
이 과정에서 VAE는 Intractable Density를 구할 수 있으며, 최적화를 직접적으로 할 수 없기 때문에 lower bound로 유도하여 likelihood를 구하게 된다.
AE와 VAE의 비교
앞서 잠깐 언급하기는 했지만 AE와 VAE를 조금 더 자세하게 비교해보자.
VAE(Variational AutoEncoder)는 기존 AE(AutoEncoder)와 탄생 배경이 다르지만 구조가 상당히 비슷해서 Variational AE라는 이름이 붙게 되었다. 하지만 수학적으로는 아무런 관련이 없으며 목적 자체도 다르다.
VAE와 AE의 목적 비교
* AutoEncoder의 목적은 Encoder에 있다! 즉, AE는 Encoder의 학습을 위해 Decoder를 붙인 것이다.

* 반대로 Variational AutoEncoder의 목적은 Decoder에 있다! 즉 VAE는 Decoder의 학습을 위해 Encoder를 붙인 것이다.
(VAE는 Generative model이기 때문에 Decoder를 학습시키는게 목적이다.)

VAE와 AE의 latent vector의 비교
* AE에서 latent vector는 어떤 하나의 값으로 나타나게 된다.
* VAE는 단순히 입력값을 재구성하는 AE에서 발전한 구조로, 추출된 latent vector의 값을 하나의 숫자로 나타내는 것이 아니다.
VAE의 latent vector는 가우시안 확률 분포에 기반한 확률값으로 나타내게 된다.

아래 그림은 MNist 데이터를 AE와 VAE로 특징을 추출해 표현한 그림이다. 각 점의 색깔은 MNIST 데이터인 0~9의 숫자를 나타낸다.
* AE가 만들어낸 latent space: 군집이 비교적 넓게 퍼져있고, 중심으로 잘 뭉쳐져 있지 않음
* VAE가 만들어낸 latent space: 중심으로 잘 뭉쳐져있음
따라서 원본 데이터를 복원해내는데 AE에 비해서 VAE가 더 좋은 성능을 보인다는 것을 알 수 있다.
즉, VAE를 통해서 데이터의 특징을 파악하는게 더 유리하다.

Reference
1) VAE(Variational Auto-Encoder)
## VAE란? VAE는 Input image X를 잘 설명하는 feature를 추출하여 Latent vector z에 담고, 이 Latent vector z를 통해 X와 ...
wikidocs.net
https://deepinsight.tistory.com/121
[모두를 위한 cs231n] Lecture 13 - Part 2. VAE(Variational AutoEncoer)
VAE(Variational AutoEncoder) 안녕하세요 Steve Lee입니다. 오늘은 cs231n 13강의 Variational AutoEncoder에 대해 알아보도록 하겠습니다. 바로 시작하겠습니다! (모두를 위한 딥러닝의 강좌들은 아래의 목차를..
deepinsight.tistory.com
'수업정리 > 딥러닝 이론' 카테고리의 다른 글
| 딥러닝 수업정리) 03_Shallow Neural Network (2) | 2022.12.23 |
|---|---|
| 딥러닝 수업정리) 02_WramingUp-Logistic Regression (4) | 2022.12.23 |
| 딥러닝 수업정리) 01_Quick Introduction (2) | 2022.12.23 |
| MoE(ME) model (0) | 2022.07.20 |
| CVAE 설명 (0) | 2022.07.20 |