
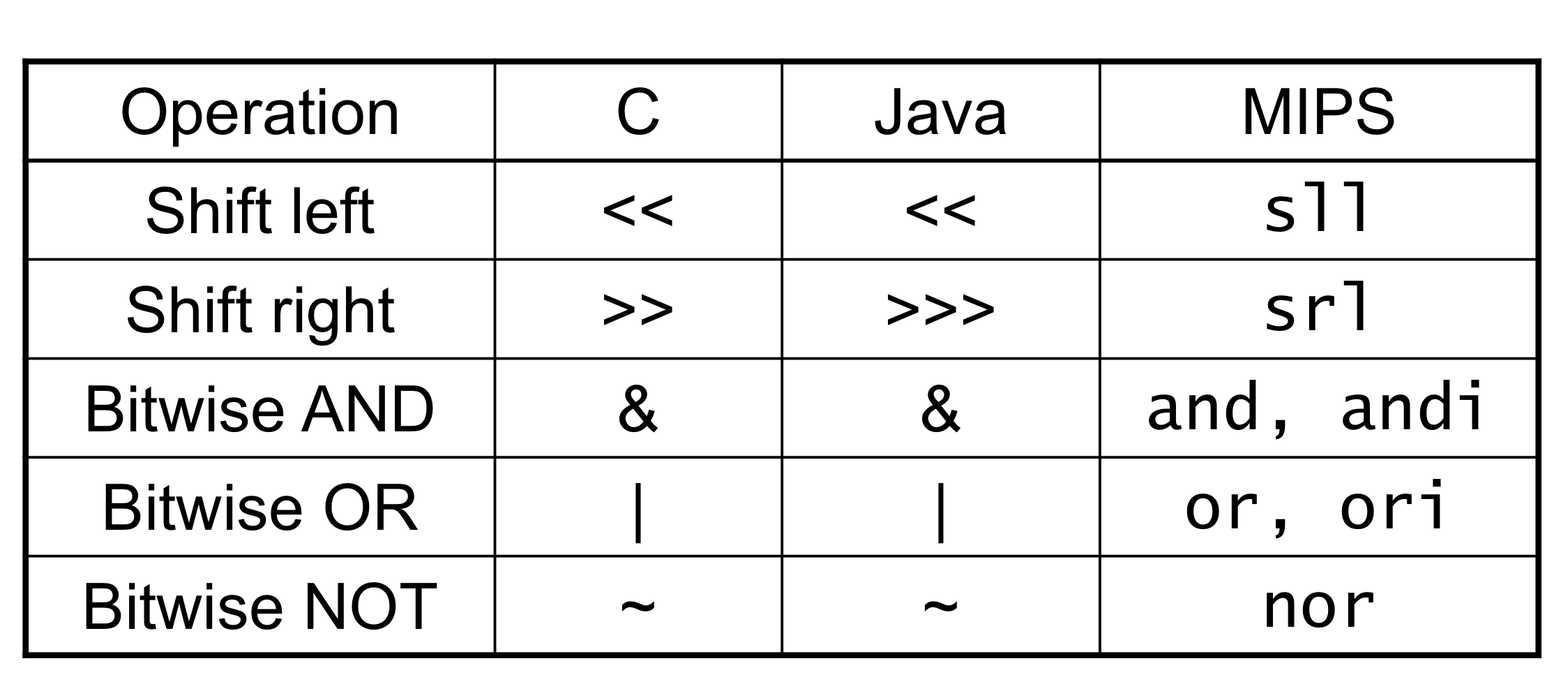
Instruction Set
- 컴퓨터라는 기계가 제공하는 인터페이스이자 서비스
- 1) 초창기의 컴퓨터는 instruction set이 단순했다. (복잡하게 만들 능력이 없었음)
2) 메모리가 너무 비싸서 CISC style의 instruction set이 유행하게 되었음
3) 메모리가 다시 커지면서 다시 단순한 RISC style의 instruction set이 유행
- 오늘날 모든 프로세서가 RISC style의 instruction set을 사용한다.
→ 전체적으로는 모두 RISC 스타일로 동일하지만 세부적인 건 프로세서 회사마다 다름.
- 프로세서 회사들이 서로 다른 instruction set을 만드는 이유는?
→ 프로세서 산업이 독점성이 있기 때문.
한 사용자가 특정 프로세서를 사용할 때 그 사용자가 쓰는 모든 프로그램은 이 프로세서에 맞게
컴파일되어 있다. 이 사람들이 다른 회사의 프로세서로 넘어가기 힘들게 하려면
프로세서 회사들마다 instruction set을 다르게 하여야한다.
The MIPS instruction set
- RISC 스타일의 instruction set 중 하나
- embedded core market의 큰 시장점유율을 가지고 있다.
- MIPS instruction set은 RISC instruction set 중에서도 RISC style의 매우 전형적인 특징을 보여준다.
→ 즉, RISC 의 특징을 잘 본여줘서 교육용으로 많이 쓰인다.
- 실제로도 상당히 많이 쓰이는 instruction set이다.
32-bit 이상 프로세서의 시장 점유율을 보여주는 그래프를 보면 MIPS가 차지하는 비율이 꽤 된다.
(제일 많이 쓰이는건 ARM. 미래에 다가올 모바일 시장을 잘 예측해서 굉장한 성공을 거둔 회사다.
임베디드 시스템에 들어가는 프로세서는 범용 프로세서보다 프로세싱 power는 작아도 되지만 die 크기는
작아야하고, 가격은 저렴해야하며, 32 bit 정도의 성능은 나오면서 power consumpotion은 작아야하는데
ARM은 이런 프로세서를 만들었음.
반도체 제조시설을 동반하지 않는 프로세서 회사로서 기존의 선입견을 깬 회사이기도 하다.)
ISA 감상: 생각의 초점
- RISC ISA는 어떻게 생겼나? 왜 그렇게 생겼나?
→ Commonly-used operations를 single instruction으로 지원한다. 자주 사용되는게
single instruction만으로 되면 빠르게 실행되니까.
- RISC ISA는 program execution을 어떻게 지원하나?
→ high level language의 가장 fundamental 한 개념이 1) Statement, 2) Function 인데
→ RISC ISA에서 Statement 들을 어떻게 지원(컴파일) 하나?
→ RISC ISA에서 Function 들을 어떻게 지원(컴파일)하나?
ALU instruction
- ALU instruction → arithmetic instruction + logic instruction
Arithmetic Operations
- 종류는 많지만 형태는 다 똑같다.
- RISC에서는 2 or 3 operand를 사용하는데 대부분이 3 operand
<MIPS에서 Arithmetic Operation>
- MIPS에서도 ALU instruction의 경우 3 operand를 사용
→ 2개의 sources 와 1개의 destination

- register-based임 (operand가 모두 register 번호로 지정)
- Design Principle 1
→ 가능하면 모든 것들을 단순하게 만들어라. 단순해야 빠른 머신을 만들 수 있다.
Arithmetic Example

- MIPS는 32개의 범용 레지스터를 가지고 있다.
머신 레벨에서 R0 ~ R31 이라고 부른다.
→ 근데 32개는 사람이 기억하기에 너무 많은 숫자. 그래서 이걸 용도별로 나눠서 Assembler name을 붙여줌
- $t0, $t1, ...$t9 : tempory라는 의미. 임시의 value를 위하 레지스터
- $s0, $s1, ...$s7: saved라는 의미. variable들을 save하기 위한 용도
- ALU 연산은 레지스터 기반으로 돌아간다.
- 그래서 위의 C code에 사용되는 variable들의 값은 이미 레지스터 안에 들어와있어야한다.
→ 아직 안들어와있고 메모리에만 존재한다면, load instruction을 통해 레지스터로 가지고 와야한다.
- Register addressing mode
Addressing mode: instruction이 어떤 operand 를 갖고 있고 이걸 어떻게 사용하는지에 대한 약속
Register Addressing mode: operand로 register operand를 사용한다. 뒤에 있는 두개의 register에 있는 값을
사용해서 operation을 한 결과를 앞의 register에 넣는다.
Register Operands
- Arithmetic instruction은 register opernad를 사용한다.
- MIPS는 32 X 32 bits register file(R0-R31)을 가지고 있다.
→ 레지스터 묶음을 register file이라고 부른다.
→ 레지스터에는 프로그램을 실행하기 위해 필요한 데이터들을 저장한다.
→ 어느 variable을 어느 레지스터에 저장할 것인지는 통상 컴파일러가 지정.
만약 어셈블리 프로그래밍을 하게 되면 어느 레지스터에 지정할건지 직접 지정이 가능하다.
- 왜 레지스터 32개밖에 안쓰나? general register의 경우 캐시 역할한다면서 많으면 좋은거 아닌가?
→ 범용 레지스터의 개수를 정하는건 매우 중요한 결정임. 여러가지 요인들에 의해 영향을 받는데 그 중 2가지 살펴볼거임
1) 32비트 instruction의 공간을 얼마나 쓰냐와 관련
32개의 레지스터를 사용한다는건 우리가 몇번 레지스터인지 표현하는데 5 bit가 필요하다는것을 의미한다.
즉, 32비트 안에 한 instruction 다 들어가야하므로 무작정 레지스터를 많이 만들 순 없다.
(MIPS의 경우 32개의 레지스터를 사용하지만 모든 프로세서가 그런건 아니다. ARM은 16개 사용.
64개 사용하는 프로세서도 있음 → 뭐가 옳다는건 없음. 설계해보고 벤치마크 제일 빨리돌리는거 택하면 된다. )
2) Design Principle2: smaller is faster
프로세서 입장에선 레지스터를 적게 만들수록 레지스터에 있는 데이터에 접근하는 것이 빠르다.
(메인 메모리의 경우 저장공간이 엄청나게 많아서 CPU가 메인 메모리에 접근하기 위해선 millon of locations 중 하나를
찾아야하는거임. 이러한 과정을 디코딩이라 부른다.)
Data Transfer Instruction - Load and store
ALU instruction은 종류 엄청 많은데 그 중 우리는 add와 sub만 본거고,
Data transfer instruction은 정말 종류가 2개밖에 없다. → load랑 store
Memory Operands
- 프로그램 짤 때 complex한 데이터들 (Array, structure, dynamic data) 은 메인 메모리에 저장된다.
<arithmetic operation을 하기 위해서>
- 이런 complex한 데이터들에 arithmetic operation을 적용하기 위해서는 사용할 데이터를 Load해서
레지스터로 가져와야한다.
- 가져오고 나면 ALU 연산을 레지스터 기반으로 하게 되고
- 연산이 끝나고 결과를 메모리에 저장하고 싶다면 store operation을 쓰면 된다.
- MIPS는 Big Endian 방식을 사용한다. → 이유가 있기보단 관습
Memory Operand Example 1

- load의 경우 ALU instruction과 addressing mode가 다르다.
→ load의 경우에는 operand 레지스터 2개와 상수값 하나로 이루어져있다. 뒤의 레지스터에 저장된 값에 상수를
더하면 메모리 주소가 나오는데 그 메모리 주소를 사용해 memory read나 write를 한다.
→ 이런 방식을 Base addressing mode 라고 부른다.
→ 이렇게 부르는 이유는 메모리의 주소를 나타낼때 base register 값에다가 offset을 더하는 방식으로 접근해서
Memory Operand Example 2

😀 load, store에서는 src, dest가 아니라 register, memory address 순으로 나온다.
- load나 store instruction이 메모리에 저장될거임. (머신 instruction은 프로그램 일부니까 당연히 저장)
올라왔을때의 상황 생각해보면

→ 이렇게 될텐데, 만약 뒤에 나오는 offset 값이 너무 크면 어떡하지? 비트 수가 32비트로 제한되어 있으므로
상수값에 제한이 생기는데..(이문제에 대한 답을 뒤에서 배운다.)
Quiz
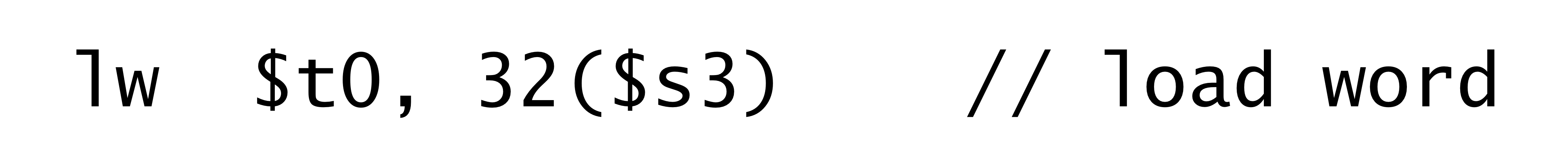
→ 이 코드를 왜 다음과 같이 나타내지 않을까?
1)
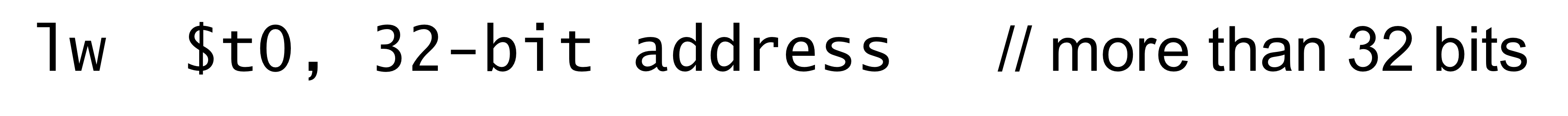
→ (앞에서도 언급했었음) 메모리 address를 32비트 주소로 주면 너무 직관적이고 좋지만,
이렇게 32비트 address를 32비트로 표현해서 instruction을 만들면 instruction 길이가 32비트가 넘어가버린다.
instruction 길이가 32비트가 넘어가버리면 instruction을 fetch하기 위해서 메모리에 2번 이상 access 해야한다.
이렇게 되면, instruction의 실행이 느려지고, 성능에 큰 악영향을 미치게 된다.
2)
operand로 2개의 레지스터와 하나의 상수를 준다고 했는데 왜 레지스터 3개를 주는 형태는 쓰지 않나?
상수 대신에 레지스터 쓰면 operand가 레지스터 3개인거니까 ALU랑 통일성있고 좋지 않나?
상수를 직접 쓰게 되면 공간 제한때문에 매우 큰 수 못쓴다고 했는데 register 쓰면 이것도 해결되는데??
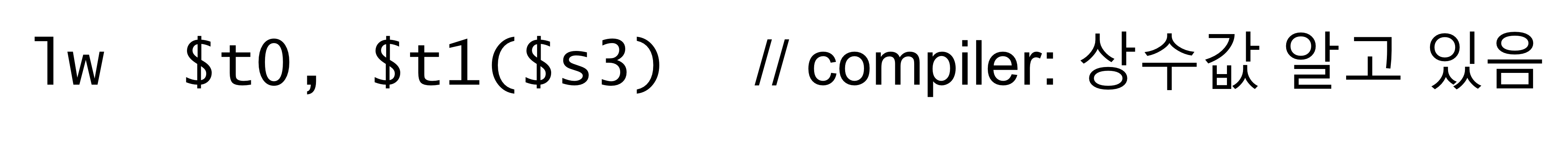
컴파일러는 컴파일러를 하다 보면 variable의 주소가 기준 레지스터로부터 얼마나 떨어졌는지 상수값을 알게 된다.
위와 같이 base register과 offset으로 나타나게 되면 컴파일러는 자기가 알고 있는 상수값을 바로 사용할 수 있다.
하지만 레지스터 2개로 주소를 표현하기 위해서 일단 offset 값을 레지스터에 넣어줘야한다.
→ 이 과정에서 instruction 하나가 소요되기 때문에 성능이 나오지 않는다.
Registers vs Memory
Register Allocation and Spill
Register allocation: 프로그램에 사용되는 variable들이 Register에 올라올 때 몇 번 register에 올라와야하는지
컴파일러가 결정해주는 활동을 의미. 어셈블리 프로그래밍을 할 경우 프로그래머가 Reister allcoation을 직접 한다.
Register Spill: register 의 개수가 한정되다 보니 register 들을 사용하다보면 공간이 부족해진다. 이때 덜 사용되는
variable들을 다시 메모리로 빼주는 작업을 의미한다.
어셈블리 프로그래밍을 할 경우 프로그래머가 Register spill 을 직접 해준다.
→ 이 두작업을 잘해주어야 좋은 성능이 난다. 하지만 이 두 문제 모두 optimization 하는 알고리즘이 존재하지 않음
컴파일러 디자이너는 이 두 작업이 잘 이루어질 수 있는 적절한 알고리즘을 제공해줘야한다.
→ Register optimization is important! = Register allocation과 Register spill을 잘해줘야한다
Quiz on Load-Store Architecture
다음 3개의 instruction을 load-store 아키텍쳐에서 수행한다. 질문에 답하기
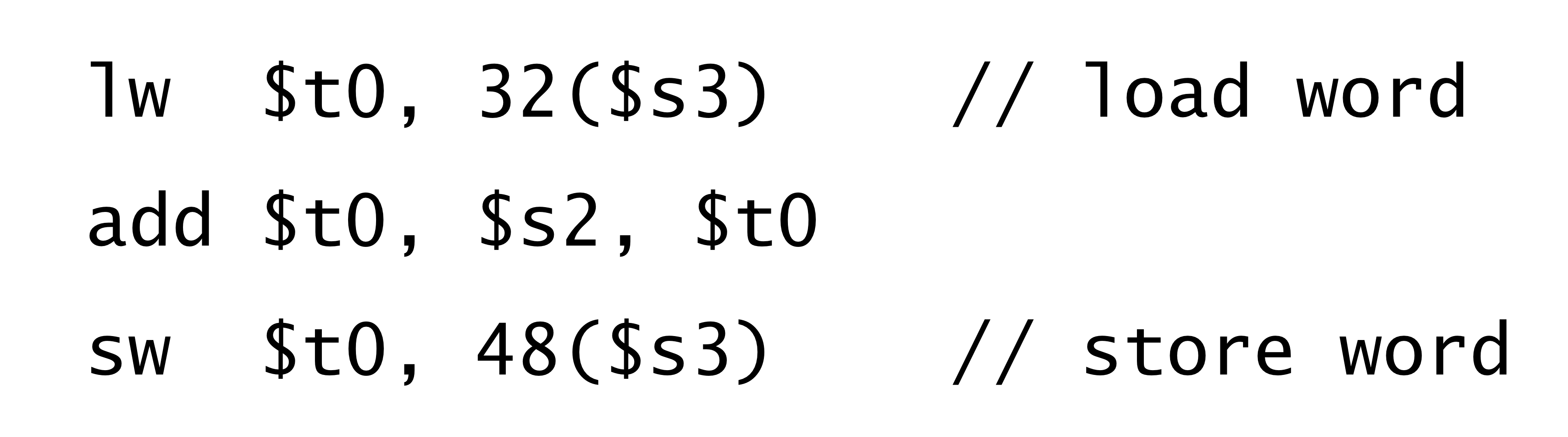
- Number of memory access? → 답) 5번
일단 3개의 instruction을 fetch 하는데 memory access가 한번씩 필요하다.
add의 경우 reisgter 기반 isntruction 이므로 더이상 메모리 access를 안하지만
load 와 store의 경우 한번씩 메모리 access를 한다. 그래서 총 5번
<Memory access를 instruction과 data 관점으로 나누어서 볼때>
- Number of instruction access → 답) 3번
fetch 과정에서 instruction 마다 한번씩 일어난다 .
- Number of data access → 답) 2번
load와 store의 execute 과정에선 instruction 이 아니라 data에 access 한다.
<Memory access를 reads와 write 관점으로 나누어서 볼 때>
- Number of memory reads → 답) 4번
instruction을 fetch 하는건 메모리에서 instruction들을 읽어오는거. 그리고 load도 메모리에서 data를 읽어오는거
- Number of memory writes → 답) 1번
store는 메모리에 data를 write 하는거
The Constant Zero
<MIPS register 0> 에 대한 이야기를 해볼거임
- MIPS register 0 를 어셈블리 용어로는 $zero 라고 부른다.
- 0번 레지스터라서 $zero 라고 부르는게 아니라 이 레지스터는 항상 0의 값을 가지고 있다.
사실 이 레지스터에는 값을 write 할 수 없으므로 사실상 레지스터가 아님.
즉, 이 레지스터를 쓴다면 32개의 레지스터중 하나를 포기하는 셈 but 이점이 많다.
<MIPS Register 0를 사용하므로서 얻는 이점>
- Move between registers 를 하기 위해 새로운 instruction을 만들어줄 필요가 없음.
add $t1, $s1, $zero
→ 이렇게 복사하고 싶은 값이 있는 레지스터에 zero 레지스터의 값을 더해서 다른 레지스터에 값을 넣어주면 된다.
- Clear register 를 하기 위해 새로운 instruction을 만들어줄 필요가 없다.
add. $t2, $zero, $zero
→ 값을 clear 하고 싶은 register에 zero 레지스터 값과 zero 레지스터 값을 더한 값을 넣어주면 된다.
→ 이 이외에도 MIPS Register 0는 다른 instruction 에서 편리하게 사용할 수 있다.
Review: Representation of Numbers
2's-Complement Signed Integers
- MSB가 sign bit에 해당한다.
- Non negative numbers 는 signed 와 unsigned에서 차이가 없다.
- 표현범위는 음수쪽으로 하나 더 크다.
→ 8비트로 수를 나타내는 경우 '-2^7 ~(2^7-1)' 범위의 수를 나타낼 수 있다.
- Some specific number
→ 0000...00: 모든 비트수가 0일 때 이 수는 0을 의미
→ 1111...11: 모든 비트수가 1일 때 이 수는 -1을 의미
→ 1000...00: MSB만 1이고 나머지가 0일 때 Most negative인 수를 의미한다.
→ 0111...11: MSB만 0이고 나머지가 1일 때 Most postive인 수를 의미한다.
Signed Negation (2's Complemenation)
- complement는 1의 보수를 의미하는거
negation은 2의 보수를 의미하는거
- ex) negate +2 (+2의 2의 보수를 구하라는 의미임)
→ 2의 보수를 구하기 위해선 1의 보수를 구한 다음 +1 를 하면 된다.

- 왜 1의 보수 대신 2의 보수를 사용하나?
1의 보수로 표현했을 때 x와 -x를 더하면 1111....111이 나온다. 계산과정에서 1111...111이 나오면 0의 값으로
처리하는 보정이 필요하기 때문에 사칙연산을 빠르게 할 수 없다.
하지만 2의 보수를 사용하면 x와 -x를 더했을 때 항상 0000...000이 나오기 때문에 보정이 필요없다.
그 이외에도 2의 보수를 사용하면 여러 계산 상의 이점이 있다.
Representation of Instruction
이제 instruction 들이 binary로 어떻게 표현되는지 알아볼거다.
Stored Program Computers
최초의 컴퓨터인 애니악은 stored program computer가 아니였음. 그러나 사람들은 곧 executable 파일이
메모리에 들어가야한다는걸 알게 되었음. 메모리에 들어가기 위해선 binary 로 표현이 되어야한다!
(데이터, instruction 모두 메모리에 들어가기 위해선 binary 로 표현되어야한다.)
Representing Instruction
- 어셈블리 Instrution이 binary로 encoded 된 형태를 machine code 라고 부른다.
→ 어셈블리 instruction과 machine code는 1:1 대응이다. 단지 어셈블리가 인지상 사람에게 훨씬 편할 뿐
- MIPS instructions
→ 모든 instruction 길이가 32비트로 통일되어 있다.
→ 32비트를 쪼개 opcdoe와 operand 들을 표현해야하는데 이를 나누어 사용하는 방법을 format 이라고 부른다.
→ MIPS에서는 3개의 format을 지원한다.
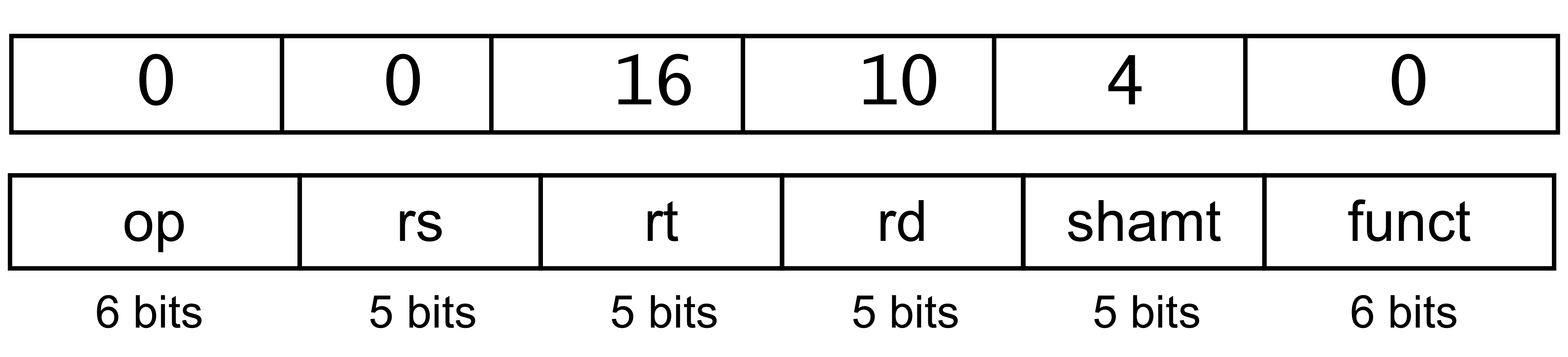
R-format
- 어셈블리를 쓸 때는 dest를 관례적으로 먼저 쓰지만 실제로 MIPS에서 binary로 표현할 때는 src를 먼저 쓴다.
→ 하드웨어적으로 구현할 때 src를 먼저 쓰는게 더 편하다.
- R은 register 의 약자. Register 기반의 ALU instruction은 R-format을 사용한다.
- Instruction fileds

op: operation code (opcode)
rs: 첫번째 source register number
rt: 두번째 source register number
rd: destination register number
shamt: shift amount. 나중에 shift instruction을 할 때 사용하게 된다.
funct: function code(extends opcode) opcode에서 부족한 부분을 보충하기 위해 사용한다.
- function code를 사용하는 이유는?
→ operation 개수가 64개가 넘어서 6-bit의 opcode로 모든 operation을 나타낼 수 없기 때문에.
- 그럼 처음부터 8-bit의 opcode를 사용하면 안되나?
→ opcode로 쓸 비트 수를 늘리면 다른 용도로 쓸 비트가 줄어들기 때문에 opcode로 쓸 비트가 더 많이 필요한데도
불구하고 6비트만 쓰는걸 선택한거.
- 실제 예시
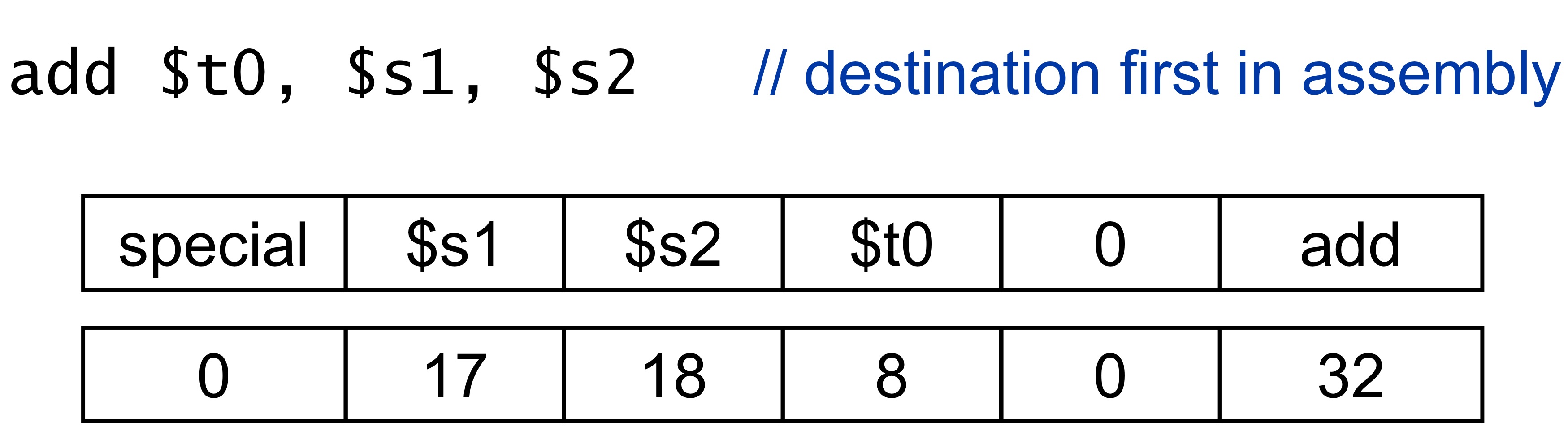
→ add의 opcode는 0이다. 그런데 register 기반의 alu instruction은 모두 opcode가 0이다.
opcode가 0인 operation이 여러개라면 0인 애들끼리 구분해줘야하는데
그 때 사용하는게 function code(funct)
I-format

- I는 Immediate의 약자
operand 에 register 번호들이 나오는데, 실제 operand는 이 register 번호가 아니라 그 register에 있는 값
→ 그래서 register access를 한 번 해야한다.
하지만 offset의 경우 그냥 번호이기 때문에 register 같은 곳에 접근할 필요가 없음. instruction 만 보면 값을
바로 알 수 있다고 해서 이걸 immediate number 라고 부른다.
- R format과 전반부는 동일하다. opcode와 레지스터 2개를 먼저 표현. 그리고 남은 16비트엔 상수를 표현
rs: base register number
rt: destination or source register number (load인지 store인지에 따라 rt의 용도가 다름)
offset: 표현범위) -2^15 ~2^15-1
- Data transfer instruction(Load와 store)은 I format을 사용한다.
- 왜 R format을 사용하지 않고 새로운 format을 적용하였을까?
→ 규칙적이게 단순한 format을 적용하면 좋겠지만 R format은 opcode와 이어서 오는 Register 2개를 제외한
16비트가 5, 5, 6 비트로 나누어져있다. 상수를 5 또는 6 비트로 표현하기엔 범위가 너무 작기 때문에 새롭게
I format을 만들어서 적용한거
→ 그래도 R format 과 전반부를 동일하게 표현. 이렇게 전반부를 동일하게 만들면 아예 다르게 만드는것보다
하드웨어를 구현할 때 편하다. 가능하면 format을 적게 만드는 것이 좋고, 새로 만든다면 기존의 format과 유사하게
만드는 것이 좋다.
- 실제예시
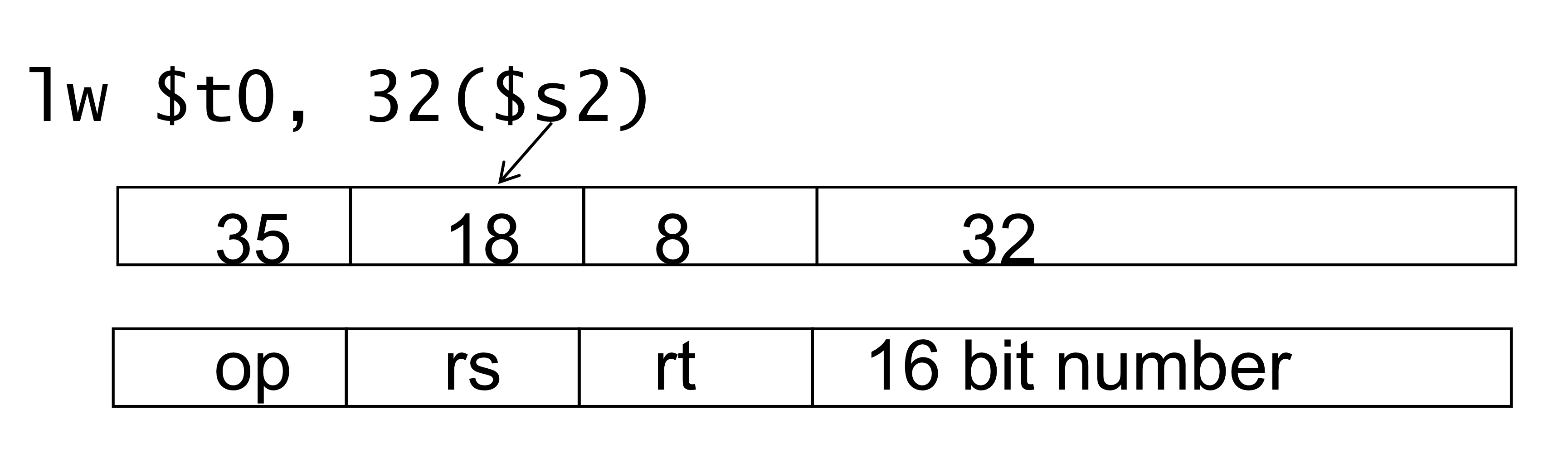
→ lw는 레지스터 기반으로 돌아가는 ALU instruction이 아니므로 opcdoe는 0이 아닌 값을 갖는다.
→ opcode가 35면 바로 load instruction임을 알 수 있다. (여기서는 function code 사용안함)
To Think about: R and I format
- Format이 2개라는 건 무슨 의미일까?
→ 뒤에 16비트를 5, 5, 6으로 나누어 쓰는 하드웨어도 존재해야하고
뒤에 16비트를 한꺼번에 쓰는 하드웨어도 존재해야한다.
→ format의 종류가 많으면 그만큼 하드웨어가 다 지원할 수 있어야해서 하드웨어가 complex 해진다.
하지만 MIPS는 format이 3개밖에 존재하지 않아 하드웨어가 비교적 단순하고 빠르다.
→ format이 다르더라도 R과 I 처럼 전반부가 동일하다면 전반부를 처리하는 하드웨어는 하나만 있어도 된다.
To Think about: I-format Instruction
<과연 offset을 위한 자리를 16비트로 한 것은 좋은 선택일까?>
→ offset에 할당할 비트 수를 결정하기 위해선 opcode에 사용할 비트수, register 개수를 결정해야한다.
(MIPS에서 offset에 16비트를 준건 opcode에 6비트를 사용하고 레지스터를 32개로 만든 결과다)
→ 수없이 많은 선택 중에서 아키텍터들이 최선이라고 생각되는 후보들을 뽑아서 이 후보들을 가지고 구체적인
설계를 한 다음에 벤치마크 프로그램을 돌릴거다. 그리고 벤치마크 프로그램을 제일 빨리 돌리는 애가 선택된다.
그렇게 선택된게 6-bit opcode, 32 Reigsters, 6-bit opcode
→ 프로세서의 핵심은 instruction set 설계인데 instruction set 설계를 할때 가장 중요한건
소프트웨어(벤치마크 프로그램)을 누가 빨리 돌릴 것이냐?
Sign Extension
- instruction에서 offset은 16비트다.
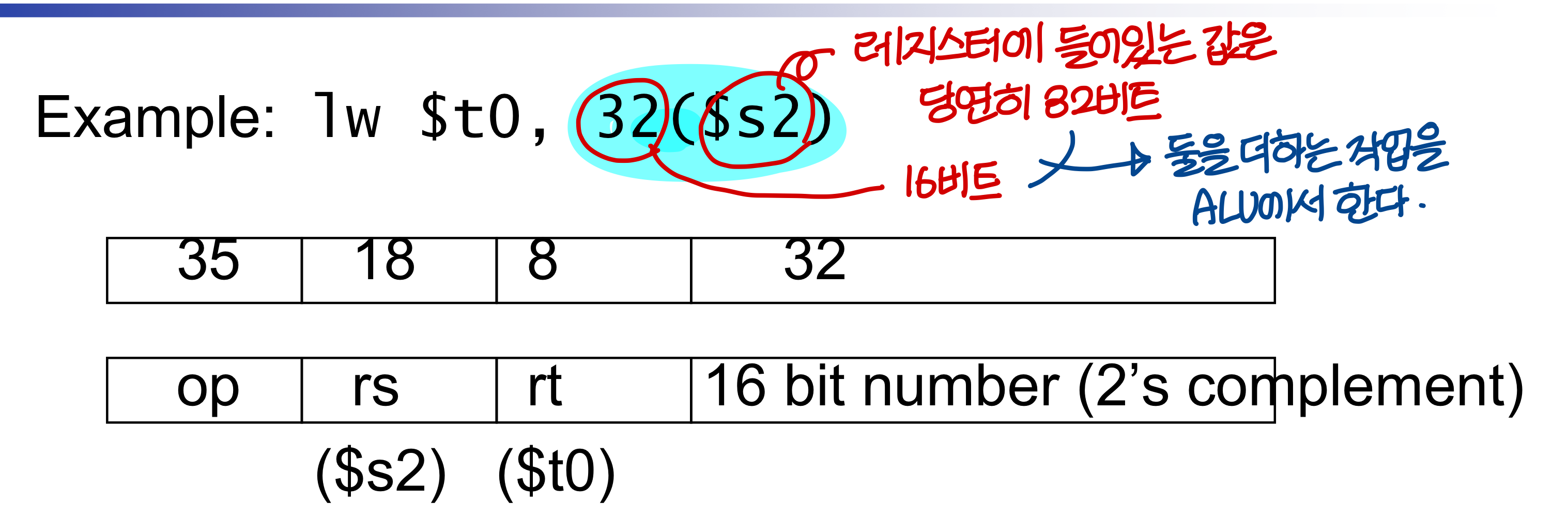
→ ALU에서 계산을 하기 위해선 32비트로 맞춰져있어야한다.
그래서 16비트 상수가 부호와 값을 유지하면서 32비트로 확장되어야함
→ 이런 작업을 sign extension이라고 부른다.
- 2의 보수에서 sign extension을 하기 위해 sign bit를 앞에 복붙해주면 된다.

- 만약 unsigned value라는 확신이 있다면 sign extension을 할 필요 없이 앞을 0으로 채우면 된다.
- lw, sw : offset에 sign extension을 한다.
addi 처럼 immediate value를 쓰는 연산에서도 sign extension을 한다.
bet, bne: displacement에 sign extension을 한다.
Back to ALU instruction (Immediate addressing mode)
Revisit ALU instruction
- ALU 연산에서 우리가 지금까지 본 variable과 variable 의 연산이 아닌 variable과 상수의 연산도 많다.
(벤치마크 프로그램을 분석해 본 결과 ALU instruction의 25퍼)
(variable과 상수의 ALU 연산에서 특징적인건 → 대부분의 경우 상수의 값이 작음.)
- 레지스터 기반의 기존 ALU instruction으로 컴파일을 한다면?
→ instruction에 나온 상수를 메모리에 정해진 위치에 load하는 과정이 필요함. 그리고 실제 연산이 일어나게 되면
메모리로부터 상수값을 불러오는거. 즉, single instruction으로 해결이 안된다.
- 그래서 MIPS에선 상수를 직접 사용할 수 있는 새로운 arithmetic instruction을 추가함
(물론 기존의 ALU instruction 과 차이를 두어야하기 때문에 operation 이름 및 opcode를 다르게 한다.)
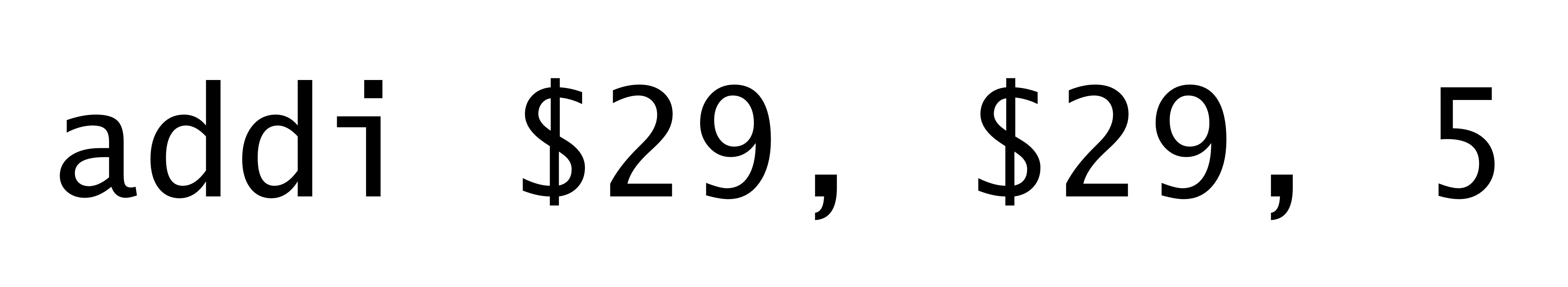
→ 위의 5와 같은 숫자를 immediate number라고 부른다.
- 사용하는 addressing mode를 Immediate addressing mode
→ operation으로 register 2개와 immediate number를 하나 사용한다. 뒤에 나오는 register에 있는 값과
immediate number를 사용해서 연산을 하고 그 결과를 앞에 있는 register에 집어넣는다.
→ load, store과 형태는 비슷하나 사용하는 방식은 다르다. 걔네는 뒤에 나오는 레지스터와 offset을 가지고
연산을 하는게 아니라 메모리 주소를 계산하고 그 주소에 access 하는거
- binary로 나타낼때 load랑 store와 마찬가지로 I format을 사용한다.
→ addi에서 쓰는 immediate value는 signed 이기 때문에 얘네도 sign extension이 필요
→ ori과 같은 logic 연산에서는 unsigned이기 때문에 sign extension을 해줄 필요 없이 0으로 채우면 된다.
- subtract immediate instruction은 필요없음
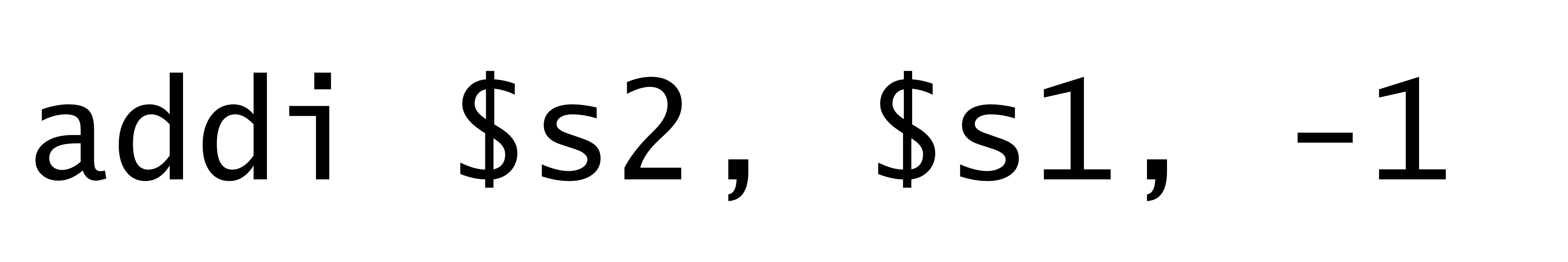
→ immediate number에 음수를 넣으면 된다.
To Think about: I-format Instruction (반복)
arithmetic immediate instruction에서 상수를 위해 뒤에 16비트를 setting 한 것은 좋은 선택일까?
→ 마찬가지로 벤치마크 프로그램을 돌려서 판단해보면 된다. 벤치마크 프로그램을 컴파일 한 뒤
arithmetic instruction 에서 immediate 넘버들이 얼마나 큰지 분포들을 확인하고 16비트로 표현했을 때
대부분의 경우를 single instruction으로 커버할 수 있겠다 싶으면 상수를 위해 16비트를 할당하는거
Large Constants
<1. immediate arithmetic operation에서 상수값이 너무 크면 어떡하냐?>
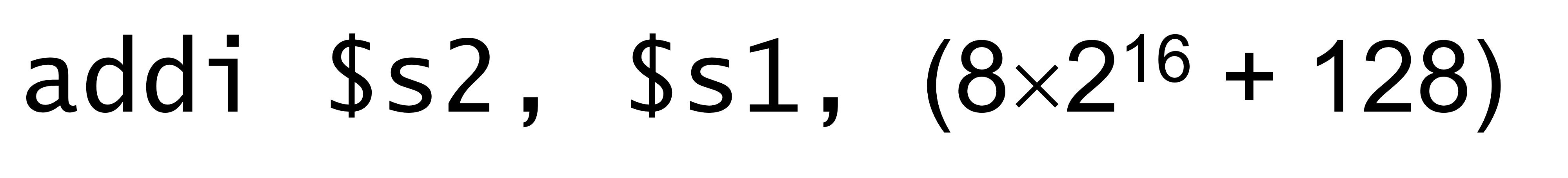
→ 이 경우엔 당연히 addi 연산 할수없음. 뒤에 있는 immediate number를 16비트로 표현 불가.
→ 총 3개의 instruction으로 연산을 한다.
1) 이럴땐 큰 constant number를 일단 register에 넣는다. (2개의 instruction 필요)

RISC instruction에서는 32비트 수를 instruction 에 표현할 수가 없음. 그래서 upper 16비트를 먼저 넣는다.
lui(load upper immediate): upper 16비트만 세팅하는 special instruction이다.
위의 경우 upper 16비트만 보면 8임
ori: ori 연산을 통해 하위 16비트를 세팅한다.
s0 레지스터에 있는 값과 128(extension을 한)을 or 연산을 해서 s0에 다시 집어넣는다.
ori 연산은 logical instruction이라 뒤에 나오는 숫자가 2의 보수로 표현된게 아니다. 그래서 extension을 할 때
sign extension을 할 필요가 없고 그냥 0으로 채우면 된다.
2) 레지스터 기반 arithmetic 연산 하기
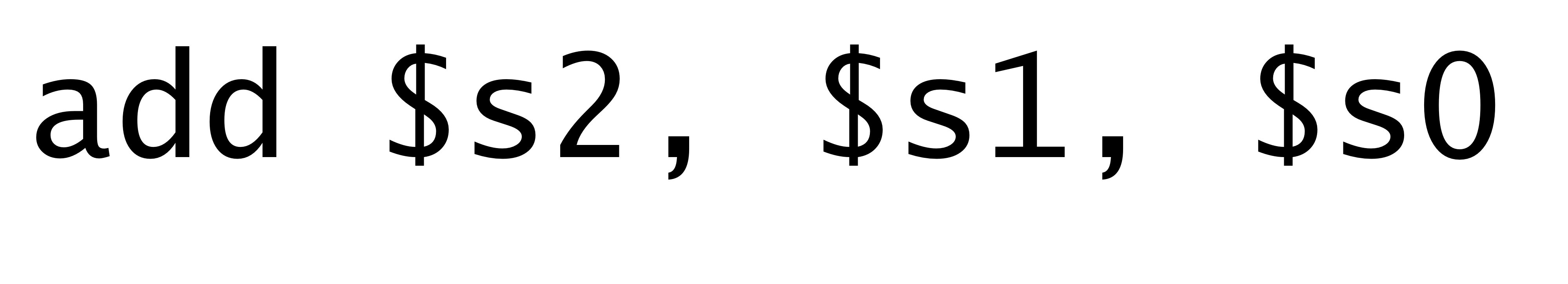
→ 레지스터에 필요한 값을 넣었으니 이제 레지스터 기반 add를 하면 된다.
<2. data transfer 연산에서 offset 값이 큰 경우>
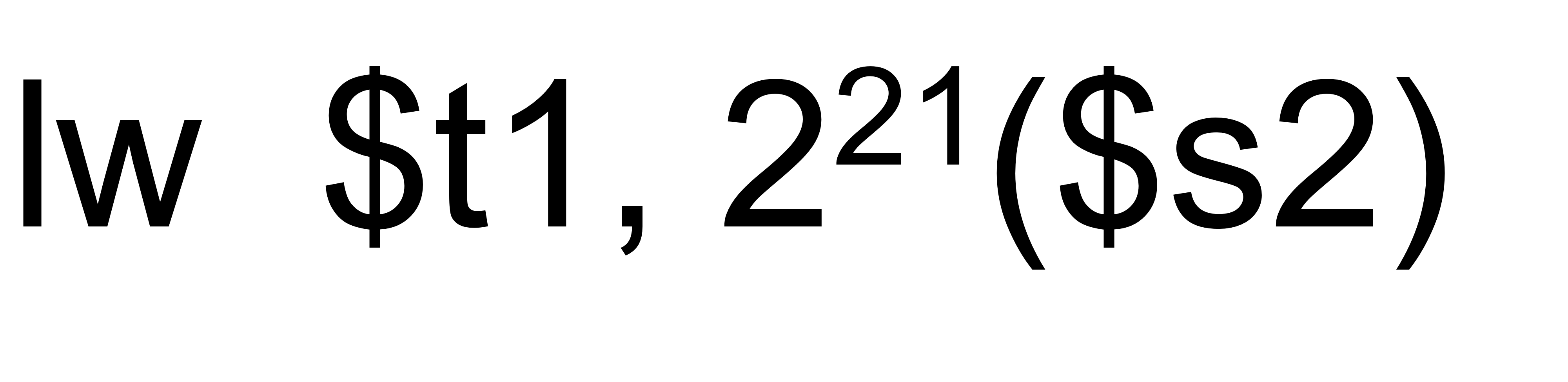
lui와 ori를 사용해 2^21을 레지스터 t0에 넣고
add를 사용해 s2 레지스터에 있는 값과 t0 레지스터에
있는 값을 더해서 메모리 주소를 만든다.
그리고 lw operation을 수행하는데 이미 메모리 주소를
t0에 만들어놓았으므로 offset으로 0을 주면 된다.

Example

Back to ALU instruction(Logical Instructions)
Logical Operation
Logical 연산: 컴퓨터사이언스에서는 32비트 word를 통째로 연산하는 것이 아니라 일부 bit 들에 대해 하는 연산
이라고 의역을 하는게 이해하기에 편하다!
(비트들을 이동시키거나, 32비트 안에 있는 하나나 여러개의 비트들의 값을 1이나 0으로 바꿀 수 있음)
→ 이런 operataion들은 high level lagnuage에서도 지원한다.
→ 비트들을 이동시키거나 : shift left, shift right
→ 하나 또는 여러개 비트들의 값을 바꾸는거: AND, OR, NOT
Shift Operation
1) Shift left logical: 비트들을 왼쪽으로 옮기고 생기는 오른쪽의 빈칸들은 0으로 치운다.

왼쪽으로 i 비트만큼 옮기면 2^i를 곱한 효과가 있다.
(그래서 컴파일러는 간혹 곱하기 oepration이 나오면 이걸 shift로 바꿔준다. shift 연산이 곱하기보다 빠름)
- 레지스터2 개와 상수 1개를 쓰는데 I-format 아니라 R-format을 쓴다. 왜??
→ op: R format을 사용하는 모든 instruction의 opcode는 0이다.
그래서 funct를 보고 무슨 operation을 해야하는지 구분한다.
→ rs: R format에 레지스터 들어갈 자리 3개 있는데 shift instruction에서 레지스터 2개밖에 안써서
rs 자리를 비운다.
→ rt: src register인 s0를 넣음
→ rd: dest register인 t2를 넣음
→ shamt: shift amount라는 의미. shift 동작에서 최대 shift할 수 있는 비트는 32비트
그런데 shamt의 길이가 5비트이므로 32까지 충분히 표현가능하다.
- 근데 I format 써도 되는데 굳이 R format을 쓰는 이유는?
→ Opcode에 할당된 bit를 줄이기 위해 operation 개수가 64개보다 많음에도 불구하고 opcode에
6비트를 할당했음. 그래서 R format 사용하는 애들에게 Opcode 0으로 부여하고 funct로 구분하는
trick을 사용했음. 현재 Nonzero opcode는 여유가 없는 반면 funct로 표현할 수 있는 operation의
수는 여유있는 상황.
→ shift를 표현하기 위해 여유없는 Nonezero opcode를 쓰는 대신 여유있는 funct를 사용하기 위해
I format 대신 R format을 사용하는거임.
2) Shift right logical: 오른쪽으로 움직이는거. 얘는 곱하기가 아니라 나누기랑 관련이 있음
(주의) unsigned 일때만 나누기랑 관련이 있음. shift right logical은 빈곳을 채우기 때문에
i로 shift left 했을때 unsinged만 2의 i승으로 나눈 효과가 있다.
→ signed 일때 shift로 division을 하고 싶으면 sra instruction을 쓰면 된다. (shirt right arithmetic)
3) variable bits of shift
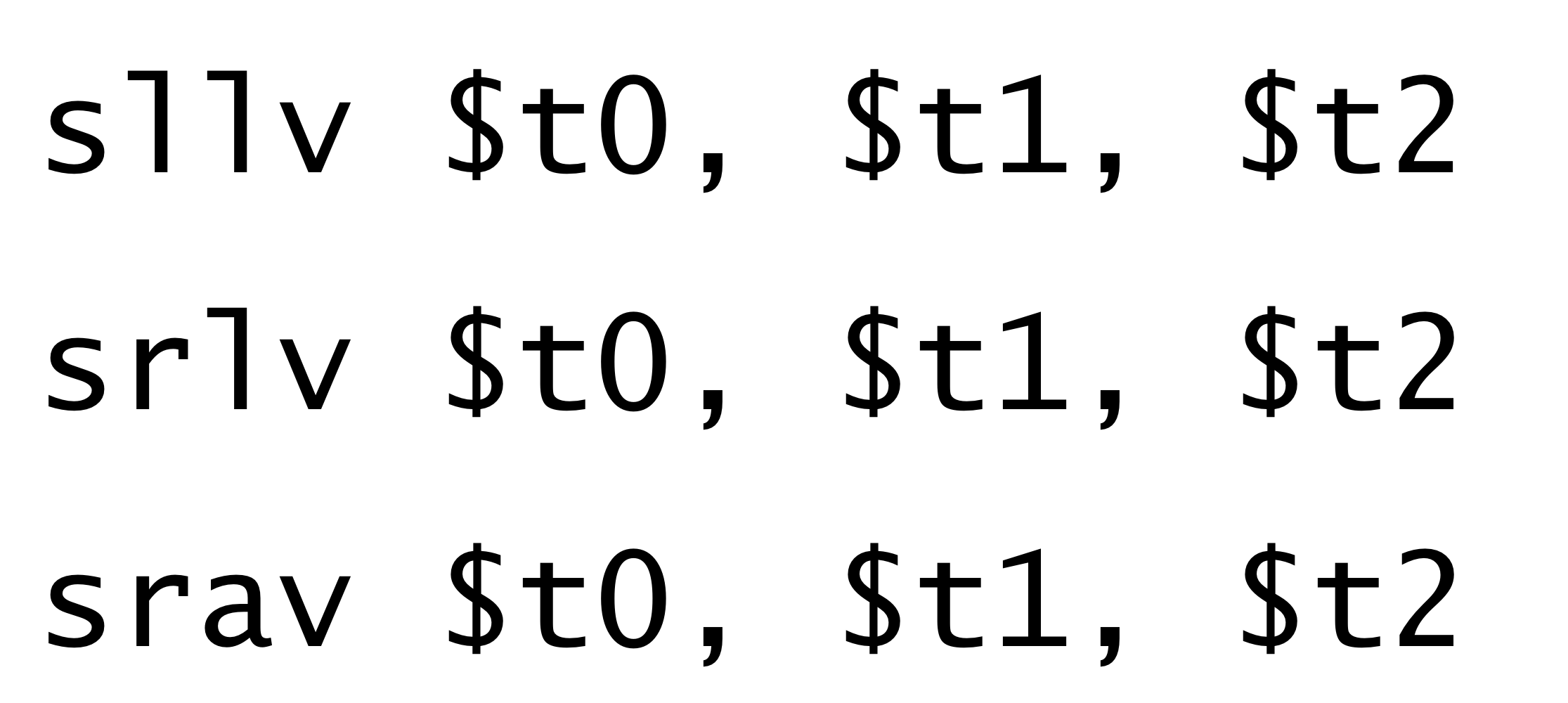
아까처럼 상수를 주고 이만큼 shift 해라고 할 수도 있지만 실제로 상수를 정해줄 수 없는 경우도 있다.
그런 경우에는 variable 이 저장된 레지스터 number를 사용해서 shift를 하면 된다.
→ 만약 t1에 저장된 value를 k라는 variable 만큼 shift 하라고 하면, k 의 값은 런타임에 결정되기 때문에
컴파일타임엔 이 값을 알 수 없음. 그럼 위와 같이 Instruction을 만들어야한다.
Bitwise AND Opeation & Bitwise OR Operation
- 내가 원하는 일부 비트들을 0으로 만들 수 있다.

→ t2에 있는 value들 중 색칠된 영역을 제외하고 모두 0을 만들고 싶다면
→ 색칠된 위치에 해당하는 비트만 1로 놓고 나머지를 다 0으로 세팅한 value와 and 연산을 시키면 된다.
- and instruction은 위의 식처럼 operand로 레지스터 3개가 와야하고
andi instruction을 쓰면 immediate number를 사용할 수 있다.
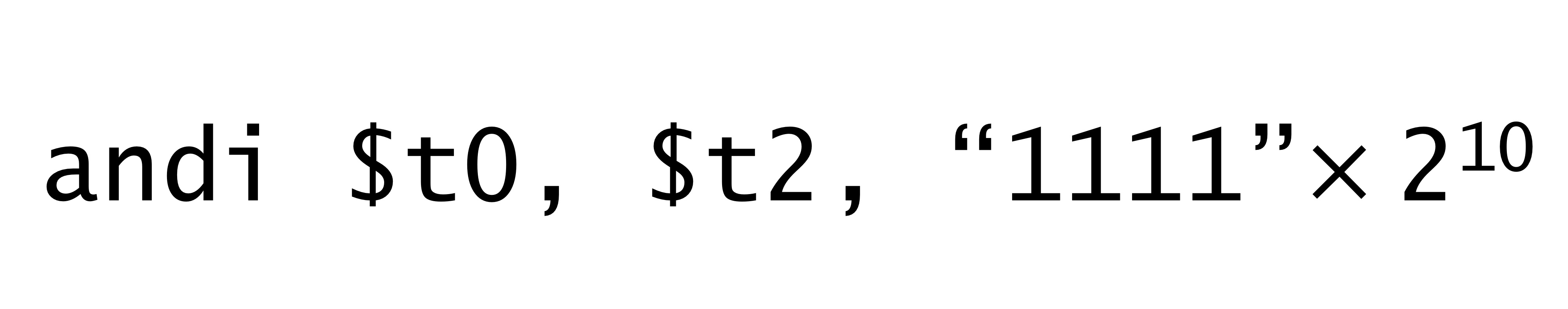
→ 뒤의 상수는 16비트로 주어지고 t2와 AND 연산을 하기 위해 32비트로 extend 해야하는데
logical 연산에 사용되는 상수는 unsigned이므로 그냥 앞 16비트 0으로 채우면 된다.
- Bitwise OR operation은 AND 와 반대로 내가 원하는 일부 비트들을 강제로 1로 만들 수 있다.
and와 마찬가지로 or instruction 또는 ori instruction을 사용할 수 있다.
Bitwise NOT operation
- MIPS에서 NOT operation을 직접 제공하지 않다. nor operation 으로 커버가 가능하기 때문

Syntactic sugar
If에서 사용되는 &&, ||, ! 는 프로그래밍 language에서 꼭 필요한건 아니다.

AND 는 이런식으로 구현 가능
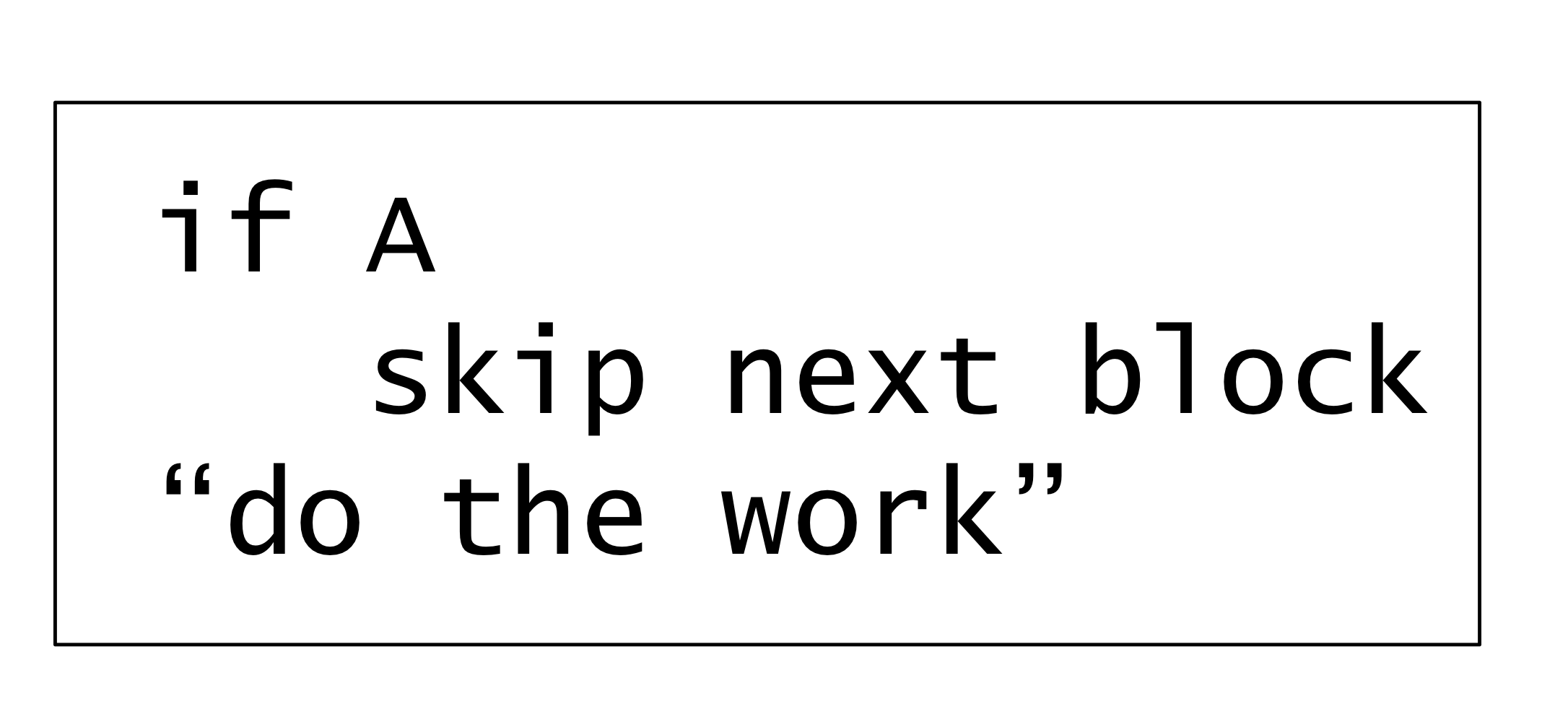
NOT 은 이런식으로 구현 가능

OR 은 이런식으로 구현 가능
하지만 제공하지 않으면 프로그래머들이 싫어한다. 이렇게 programming language에서 꼭 필요하진 않지만
제공하지 않으면 프로그래머들이 불편해해서 싫어하기 때문에 제공하는걸 syntactic sugar라고 부른다.
Operand Types to Support
Instruction set에서는 word, half word, byte 중 어떤 operands를 지원해야하는가?
(32비트 머신이니까 32비트 operand만 지원하면 되는게 아닌가? → 아니다!)
- Character Data: 아스키 코드에서는 1 Byte로 표현되었고,
유니코드에서는 한 Byte로 표현하기도 하고 half word로 표현하기도 하고, 한 word로 표현되기도 한다.
→ Character Data는 굉장히 자주 쓰이는 데이터인데 byte, half word, word 모두 사용하니까
Instruction Set에서 byte, half word, word 를 효율적으로 처리할 수 있는 Instruction이 필요하게 됨
- Multimedia data: 보통 8 bit 또는 16 bit로 구성된다.
→ Multimedia data도 1990년 이후 엄청나게 쓰이고 있는데 8 bit와 16 bit 사용하니까
Instruction Set에서 8 bit 또는 16 bit를 효율적으로 처리할 수 있는 instruction이 필요하게 됨
Byte/Halfword Operation
1) load instruction
lw (word)뿐만 아니라 lh, lhu (half word) lb, lbu (byte) 5가지의 load instruction을 제공한다.
- 메모리에서 32비트보다 작은 비트를 읽어서 레지스터에 올리면 빈 공간이 생기는데
내가 가져오는게 signed 일 경우 → 1h, 1b 사용해야함 (sign extension 해서 올림)
내가 가져오는게 unsgined일 경우 → 1hu, 1bu 사용해야함 (zero extension 해서 올림)
- 그냥 5종류의 load를 만들지 말고 lw를 사용해서 가져온 다음 bitwise로 연산을 하면 안되나??
half word, byte 단위 load는 굉장히 많이 사용된다. 자주 사용되는건 single instruction으로 빠르게 지원해야함.
2) store instruction
sw 뿐만 아니라 sb (byte), sh(half word) 3가지의 store instruction을 지원한다.
- load instruction 과 다르게 빈공간을 발생시키지 않는다.
지정된 주소로 가서 지정된 부분만 건들어야한다.. 오히려 다른 부분을 건들이면 큰일남.
Uploaded by N2T