
컴퓨터라는 기계는 무엇으로 만드는가?
→ 컴퓨터는 트랜지스터로 만든다. 트랜지스터는 반도체 기술을 이용해서 만든다.
Semiconductor Technology
- 트랜지스터는 1947년에 발명. 상용화 되기까지 10년이 걸림
- 같은 실리콘 판 위에 많은 트랜지스터를 한꺼번에 만드는 집적회로(IC)가 고안
IC기술은 상용화 되는데 5년이 걸림
SSI : 처음에는 칩 안에 많은 수의 트랜지스터를 넣지 못했음. (Small scale integration)
MSI(medium scale integration), LSI(large scale integration)
VLSI: very large scale integration. 현재 계속 사용중 기술. 칩 안에 수십억개의 트랜지스터를 넣을 수 O
- 트랜지스터의 발명 및 IC기술의 발명과 성능의 개선
→ 이게 컴퓨터의 성능을 향상시키는 주요 원동력이 되었음
(컴퓨터는 1950년도 전후에 만들어졌지만 실제 많은 사람들이 쓸 수 있는 실용적인 컴퓨터가 가능해진건
트랜지스터의 발명 및 IC 기술이 발명되고 성능이 어느정도 개선된 1970년도 이후)
Small, Faster
반도체 기술의 핵심은 최소선폭을 작게 하는 것
→ 속도 증가 및 크기 감소 (최소선폭이 1/2가 되면 속도 2배 density는 4배 크기는 1/4가 된다.)
Technology Scaling(Intel)
Minimum feature size: 반도체 크기는 exponential하게 decrease함
6~7년마다 1/3로 감소했다
→ 이걸 주도한 회사가 intel
Speed and density: exponential하게 increase (반도체 크기가 6~7년마다 1/3로 감소하다보니 자연스럽게)
6~7년마다 speed 3배
6~7년마다 density 9배
→ IT 시대의 특징은, 많은 것들이 exponential 양상을 보인다는 것.
소프트웨어 크기도 그렇고, 네트워크 bandwidth도 그렇고,
반도체의 최소선폭, 스피드, 집적도도 그렇고
→ 이렇게 100억배나 증가한 이유에는 반도체 기술의 발달도 있지만 그와 더불어 컴퓨터 설계 기술도 발달되어 왔기 때문
AMD Opteron X2 Wafer
- AMD라는 회사에서 만든 Opteron X2 라는 프로세서. 아직 자르기 전의 상태이다.

- Patterened wafers 상태
- X2: 300mm wafer(직경이 300nm), 117 chips(한 wafer 안에 X2 프로세서 117개 들어감),
90nm technology(이 프로세서는 최소선폭이 90nm인 반도체 기술로 제작)
- X4: 45nm technology (최소선폭이 45nm인 기술로 제작)
Inside the Processor

- AMD Opteron X4
- die(chip) 하나를 확대한 그림
- 같은 패턴이 4개가 보인다.
칩(die) 안에 코어가 4개 있다는 의미
Semiconductor Technology
- Moore's law: exponential growth와 같은 의미로 쓰이는 용어
→ Intel의 공동창업자 중 한명. 직접 발표한건 아니고 발표한 자료가 exponential한 growth를 보이고 있었음
→ Intel의 역사를 살펴보면 시간이 감에 따라 CPU 안에 있는 트랜지스터 수는 약 1년 반마다 2배가 된다.
→ 트랜지스터를 작게 만드려면 첨단의 제조시설과 장비가 필요함.
시간이 감에 따라 fabrication facility를 만드는 비용이 exponentially하게 증가
Processor Technology
마이크로프로세서의 출현과 발전 흐름 이해하기, 전체적인 흐름에 집중. 숫자는 기억할 필요 없음
Computer Architecture Technology
오늘날 컴퓨터의 성능이 빠르게 증가한데는 2가지 요인
- Smaller transistor
- Increased die size to add more functionalities
→ 프로세서의 크기가 증가해왔다는 의미. 트랜지스터의 크기가 작아지면 die 사이즈도 작아져야하는거 아닌가?
왜 증가한걸까? 개선된 설계기술(pipelines, 캐시 메모리 등...)을 구현하기 위해 많은 양의 하드웨어를
추가했기 때문.
→ 개개의 트랜지스터 크기는 작아졌지만 전체적인 프로세서의 크기는 증가했음
Invention of Single-Chip Microprocessors
- Intel: 2차 세계 대전 후, 실리콘 밸리의 여러 반도체 회사 중 하나였음
→ Chip을 주문 설계 및 생산하는 회사
→ 그 당시 실리콘 밸리에 컴퓨터 산업이라는건 없었음.
컴퓨터 산업은 미국 동부가 주도했었음. 특히 IBM 이라는 회사가.
- Breakthourgh: 4004 microprocessor by Intel in 1971
→ 한 고객이 calculator를 위한 chip을 만들어달라고 요청.
→ 이걸 설계하는 과정에서 calculator에 특화된 칩을 만들수도 있지만 Intel의 디자이너는 혁신적인 시도
→ 범용 레키스터를 single chip으로 만들어보자! 해서 나온게 4004 마이크로프로세서
→ 최초의 싱글칩 프로세서를 만듦으로 인해서 인텔은 컴퓨터 회사로 재탄생.
(범용레지스터를 만들고 나면 calculator 기능을 프로그램으로 만들면된다. 즉 이젠 주문이 오더라도
새로운 칩을 만들 필요가 없어짐)
- 당시의 processors for mainframes
→ 1970년대 대형컴퓨터들은 기업이 원하는 계산을 해야했음.
그래서 32 bit 컴퓨터로 시작. 하지만 IC 기술이 발달하지 않아 칩 하나에 트랜지스터 많이 넣지X
32 bit 컴퓨터를 만들기 위해서는 많은 수의 chip이 필요했음
→ PCB(printed circuit boards) : 많은 수의 칩을 쓰기 위해 굉장히 사이즈가 큰 PCB들을 사용
→ 디자인 사이클: 5년
메인 프레임 대형 컴퓨터는 프로세서만 개선해야하는게 아니라 OS도 바꿔야하고 경우에 따라
application을 바꾸는것도 신경써야함. (Intel을 포함한 실리콘 밸리의 기술혁신 따라가기 힘든 구조)
→ 반면에 4004 마이크로프로세서는 4 bit 마이크로프로세서였음
즉, 크기 가능 성능 면에서 micro
→ 그리고 위에서 말한 컴퓨터들은 powerful한 32비트 컴퓨터 이야기이고, 인텔은 목표가 조그마한 임베디드 시스템을
위한 비교적 힘이 작아도 되는 프로세서
- Intel은 설계기술, 반도체 제조기술을 발달시켜가면서
8 bit 8008을 1972년에 발표. 8080을 1974년에 발표
- Altair: 한 잡지회사에서 Intel의 8080 마이크로프로세서를 이용해서 최초의 마이크로 컴퓨터 설계
- 마이크로 컴퓨터 및 거기서 돌아가는 소프트웨어 스타트업이 많이 생김
→ 그들의 비전: "모두의 책상에 컴퓨터를"
- IBM이 마이크로 컴퓨터인 "IBM PC"를 출시하고 PC 시장을 평정
→ 하지만 굉장히 제한된 형태로 참여.
→ CPU와 OS를 자체 생산하지 않았음. CPU는 16-bit 8088(Intel) 쓰고 OS는 MS DOS 사용
인기 있는 응용 프로그램에도 참여하지 않았음
→ PC 시장이 성장해서 메인프레임보다 커질 것이라고 예측하지 못했기 때문에 소극 참여
- Application: Intel CPU와 MS DOS를 사용한 컴퓨터가 시장을 장악하게 되면서 모든 application은
Intel/Microsoft platform 에서 잘 돌아가게 됨. 이 플랫폼이 IBM PC를 장악
- 한 실리콘 밸리의 기업이 IBM의 특허를 피하는 방법을 고안
→ 누구나 IBM PC를 제조할 수 있게 됨
→ 그러나 이미 application들은 Intel/MS platform에서 잘돌아가는 상태
→ 많은 회사들이 PC 제조에 뛰어들게 되는데 이 회사들은 선택의 여지 없이 Intel CPU와 MS OS 사용
- Intel and Microsoft: PC platform의 Owner가 되었음 ("Wintel" 플랫폼이라고도 부름)
- 실리콘 밸리 : 컴퓨터 산업의 주도권을 잡게 됨
Single-Chip Microprocessors
- Intel의 마이크로프로세서는 힘이 부족하긴 하지만 싱글칩이다.
(+1970년도의 mainframe과 다르게 OS나 application을 신경쓰지 않고 CPU만 설계하면 되니까)
→ 그래서 디자인 사이클이 짧음 (6개월~1년 후면 새로운 프로세서 설계)
→ 싱글칩+ 디자인 사이클이 짧아서 반도체 기술의 발달을 충분히 이용가능
→ 이렇게 인텔은 반도체 기술과 프로세서 설계 기술을 개선해나가면서 프로세서 성능을 지수적으로 개선
- x86 ISA compatibility (golden shackle)
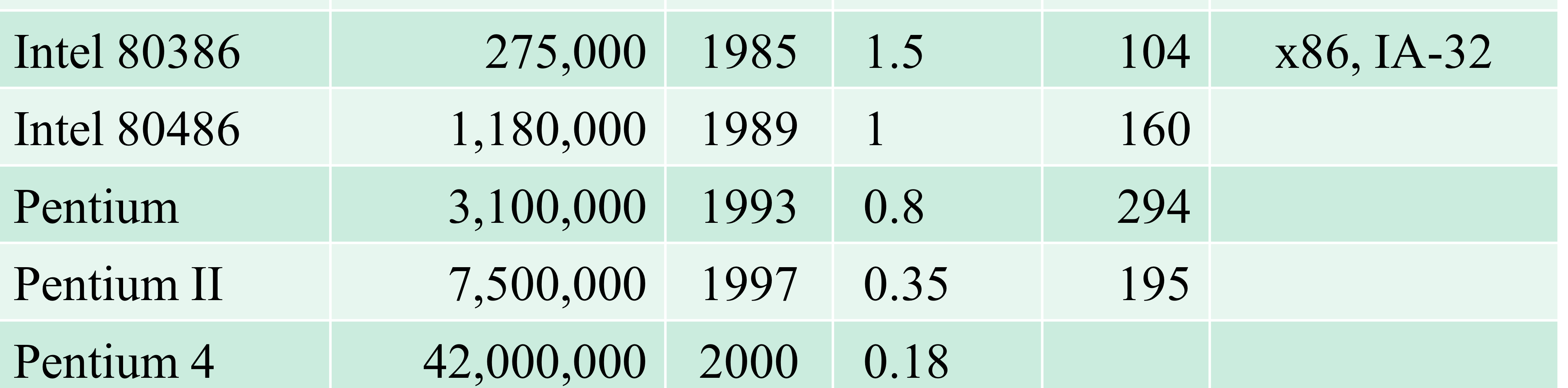
→ 위의 아키텍쳐 라인을 x86 또는 IA-32 라고 부른다.
성능이 다름에도 불구하고 x86이라고 부르는건 무슨 공통점이 있다는거
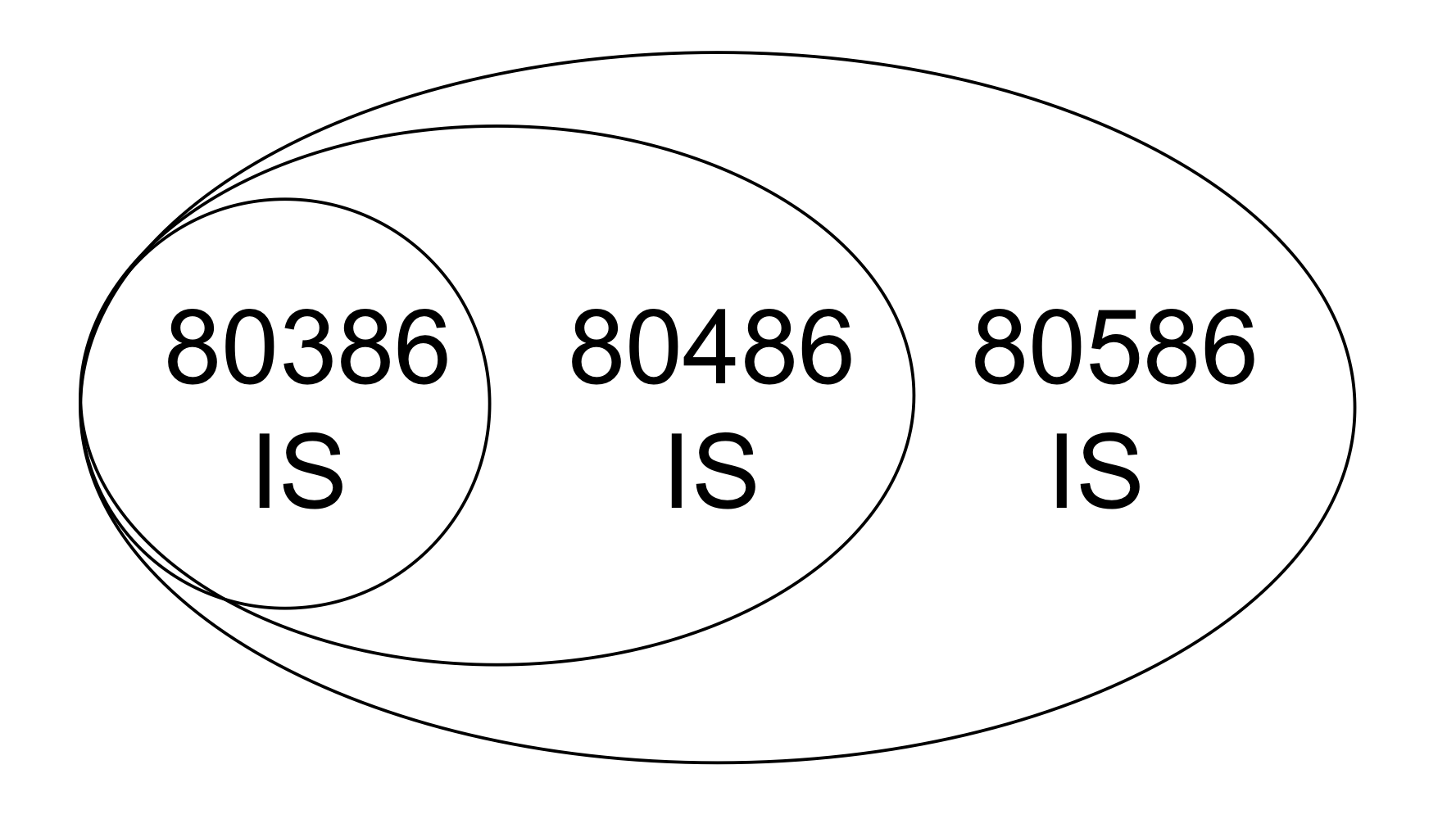
→ 위의 그림과 같이 Instruction set을 개선해서 새로운 Instruction set을 만들 때에는
반드시 과거의 instruction set을 포함하고 새로운걸 추가해야한다. 이걸 ISA compatibility라고 부른다.
→ 그래야 사용자들이 사용하던 응용 프로그램을 그대로 사용할 수 있으니까 충성스럽게 다음 버전 구매
(Approximate) Performance Trend
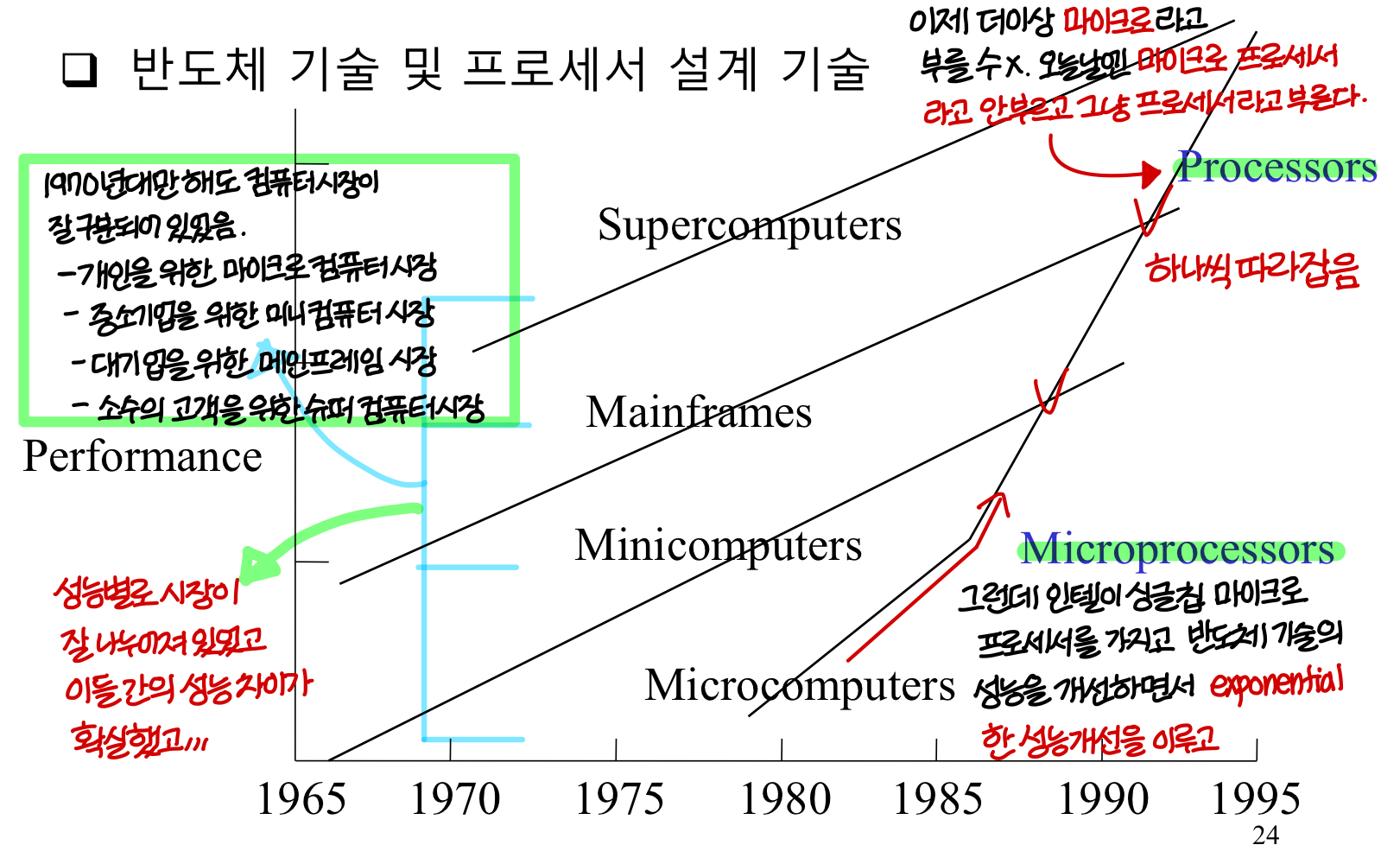
Single-Chip Processors
- 이제 그림에서 봤듯이 마이크로프로세서는 powerful한 프로세서가 되었음.
- 컴퓨터 회사들
과거의 컴퓨터 회사들은 자체적으로 프로세서를 만들고 OS를 설계했어야했는데,
더이상 자체적인 프로세서를 설계할 필요X 사서 쓰는게 더 경제적!!!
컴퓨터 회사들이 그동안 하드웨어 & 소프트웨어에 다 만들었다면 → 이젠 하드웨어는 전문회사에서 사고 소프트웨어에 집중!
💡회사들이 하드웨어보다 systems, software, service 에 집중하게 된다.
Instruction Set 변화 and RISC
우리 이때까지 인텔이 설계한 프로세서만 이야기했다. 그런데 인텔 말고는 프로세서 성능 향상에 기여한 회사가 없나???
→ 아니다! 인텔 외에도 상당수의 회사들이 프로세서 설계에 뛰어들었다(80년대).
- 1970년대: 70년대의 프로세서들은 CISC형태의 instruction set 사용. (메모리가 너무 작고 비싸서)
- 1980년대: 인텔 외에도 프로세서 설계에 많은 회사들이 뛰어들었음.
프로세서 전문회사들이 많이 생겨서 프로세서 설계에 집중함. (이때 만들어진 프로세서들은 RISC style)
→ 80년대를 프로세서 디자인의 르네상스라고 부른다.
<왜 이때 많은 프로세서들이 설계되었을까?> → 80년대에 프로세서가 발달하기에 좋은 조건 마련
1) 반도체 기술이 어느정도 발달해서 powerful한 프로세서를 만들 기반이 마련되었음.
→ 그리고 반도체 기술이 발달하면서 메모리 가격도 싸져서 CISC style에서 RISC style로 옮겨옴
2) unix OS가 개발되어 Open으로 제공되었음. 컴퓨터 산업을 할려면 프로세서와 OS 모두 문제인데
이렇게 OS가 제공됨에 따라 프로세서만 설계하면 컴퓨터 산업을 하기 쉬워졌음
3) unix OS와 함께 C 프로그래밍도 전세계로 퍼져서 high level programming이 본격화
프로세서가 바뀌더라도 컴파일러를 이용하면 되니까 포팅 노력이 덜들었다.
- powerful한 32 bit RISC 프로세서가 등장.
→ 오늘날 우리가 쓰고 있는 컴퓨터들은 다 80년대 스타일인(RISC) instruction set 사용
→ x86 ISA는 예외. 하지만 이것도 내부적으론 RISC 스타일
🥵알아두기: 프로세서 쪽은 exponential한 속도 개선이 일어남. 메모리 쪽은 exponential한 capacity 개선
하지만 메모리 쪽의 speed 개선은 굉장히 더디게 일어남.
(DRAM capacity: 매년 25~40%, Flash memory capacity: 매년 50~60%, Magnetic disk capacity: 매년 40%)
More on Computers
X-Bit computers
- 'x-bit computer'에서 x-bit의 의미는?
→ 32-bit computer에서 ALU input operand와 register 사이즈, processor data bus width ~~ 많은게 32비트라 헷갈림
→ 정답은 ALU input operand의 사이즈
- 64 bit computer가 32 bit computer 보다 나은가?
- Larger numbers
32비트 컴퓨터는 우리나라 예산을 가지고 어떤 연산을 할 때 한꺼번에 계산할 수 없음.
예산을 2개의 32 bit word로 나누어서 저장한 다음 더해야한다.
64비트 컴퓨터는 일단, 더 큰 수를 가지고 연산할 수 있음. 우리나라 예산도 한번에 다룰 수 있다.
- Multimedia: speedup with parallel operation
90년대 이후로 멀티미디어 데이터가 많이 사용되었음.
→ 멀티미디어 데이터는 크기가 작아서 Integer로 표현가능.
ex) Audio Data는 흔히 16비트로 표현된다.
64비트 머신 입장에서 보면 register 하나에 4개의 Audio Data 저장 가능
64비트 머신에서는 4개의 Audio Data의 값을 한번에 올릴 수 있음.
즉, 64비트 머신에서는 32비트보다 한꺼번에 더 많은 멀티미디어 데이터를 병렬연산해서 속도가 증가한다.
(32비트 머신에서는 2개의 Audio Data 병렬연산 가능.)
이렇게 작은 멀티미디어 데이터들을 병렬로 연산함으로써 speed를 올리는 기법을
→ SIMD instructions 또는 subword parallelism이라고 한다.
- Larger numbers
Sizes of Address spaces
ALU input 사이즈 외에 중요한 것 → Sizes of address apces!
= 우리가 돌릴 수 있는 최대 프로그램의 크기가 얼마냐?와 연관된다.
History of single chip processor
| Processor | Data size | Address Size | 설명 |
|---|---|---|---|
| 8-bit | 8 | 16 | address space의 사이즈는 2의 16승 = 64K |
| 16-bit | 16 | 16(+알파) | 당시 반도체 기술(IC기술)의 한계로 address size를 8 bit 프로세서에 비해 충분히 늘리지 못함 |
| 32-bit RISC | 32 | 32 | 80년대에 32 bit RISC 프로세서 설계 |
| 64-bit | 64 | ?? | 개념적으로 64비트를 쓸 수 있으나 다 필요한가 싶을 정도로 많음. → 그래서 다 안쓰는 경우 많음 |
→ 싱글칩 프로세서는 8비트에서 시작.
Alignment
- alignment는 memory access speed와 관련된거
→ alignment를 잘 지키지 않으면 하나의 half word 또는 word를 읽기 위해 메모리에 2번 접근해야 할 수 있음
- alignment를 요구하는 32비트 아키텍쳐에서는
1) byte: 어디 저장되든, 상관없음
2) half word: 짝수번지에서 저장 시작
3) word: 4의 배수 번지에서 저장을 시작
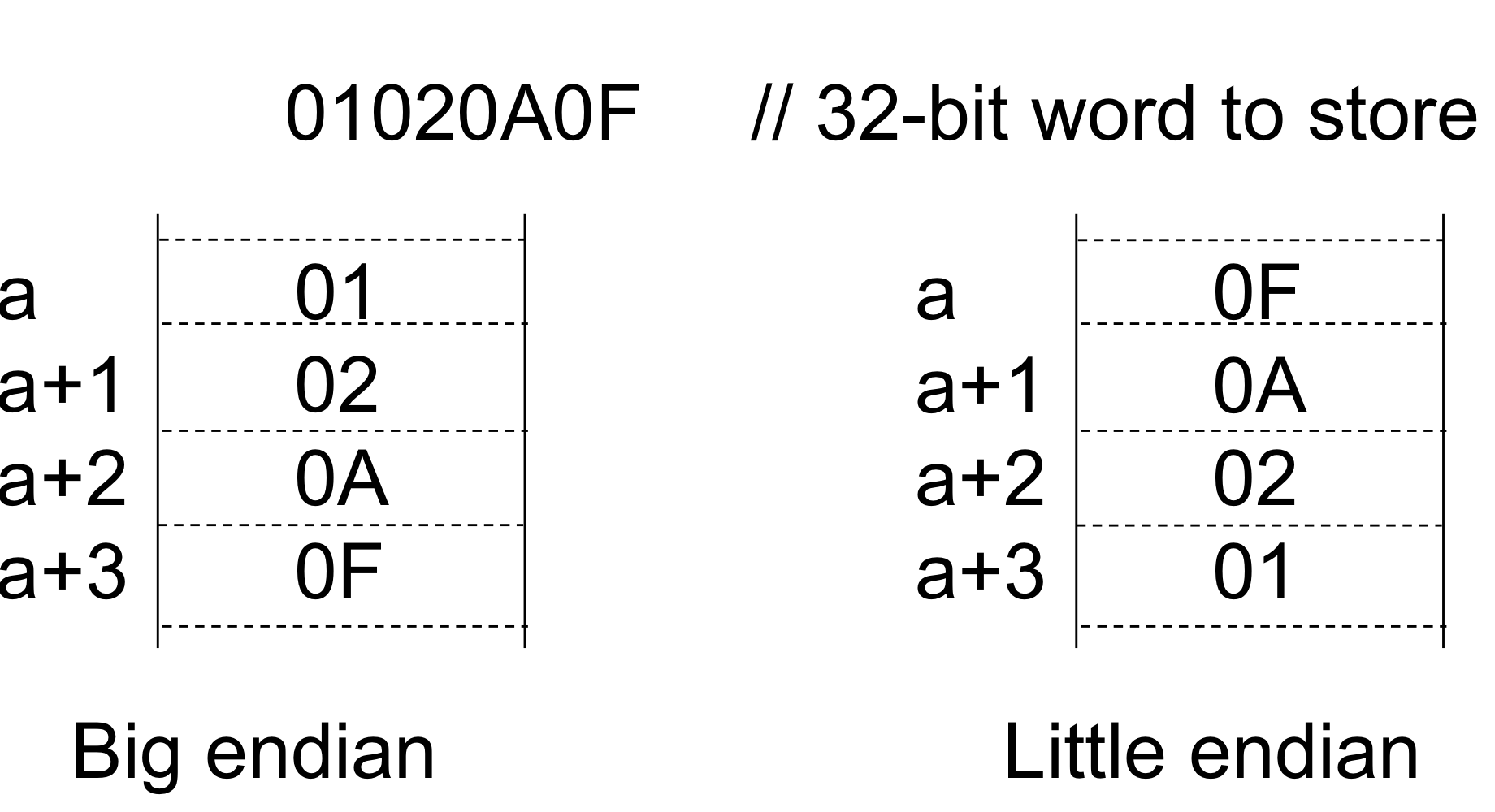
Little Endian and Big Endian
- 1950년대에, A few mainframes in the world들은 "islands"처럼 따로 고립되어 존재했다.
→ 오늘날처럼 랜이나 인터넷으로 전세계의 컴퓨터가 연결되는건 꿈도 못꿀 시절
- 그리고 컴퓨터 Scientist 들은 우리가 개발한게 아니면 쓰지 않겠다는 경향을 보임.
→ 이때문에 많은 용어상의 혼란이 야기되었다. 그 중 하나가 Little Endian과 Big Endian
- Little Endian과 Big Endian은 "Byte address"와 관련된 convention
More on Computers(Memory Map, Microcontroller)
8/16-Bit "Microcontroller" Board
마이크로 컨트롤러 뒤에서 배울거임. 여기서 잠깐 살펴보기만 할건데,
8/16-Bit 마이크로프로세서를 이용해 만든 손바닥만한 컴퓨터 보드라 생각하면 된다.
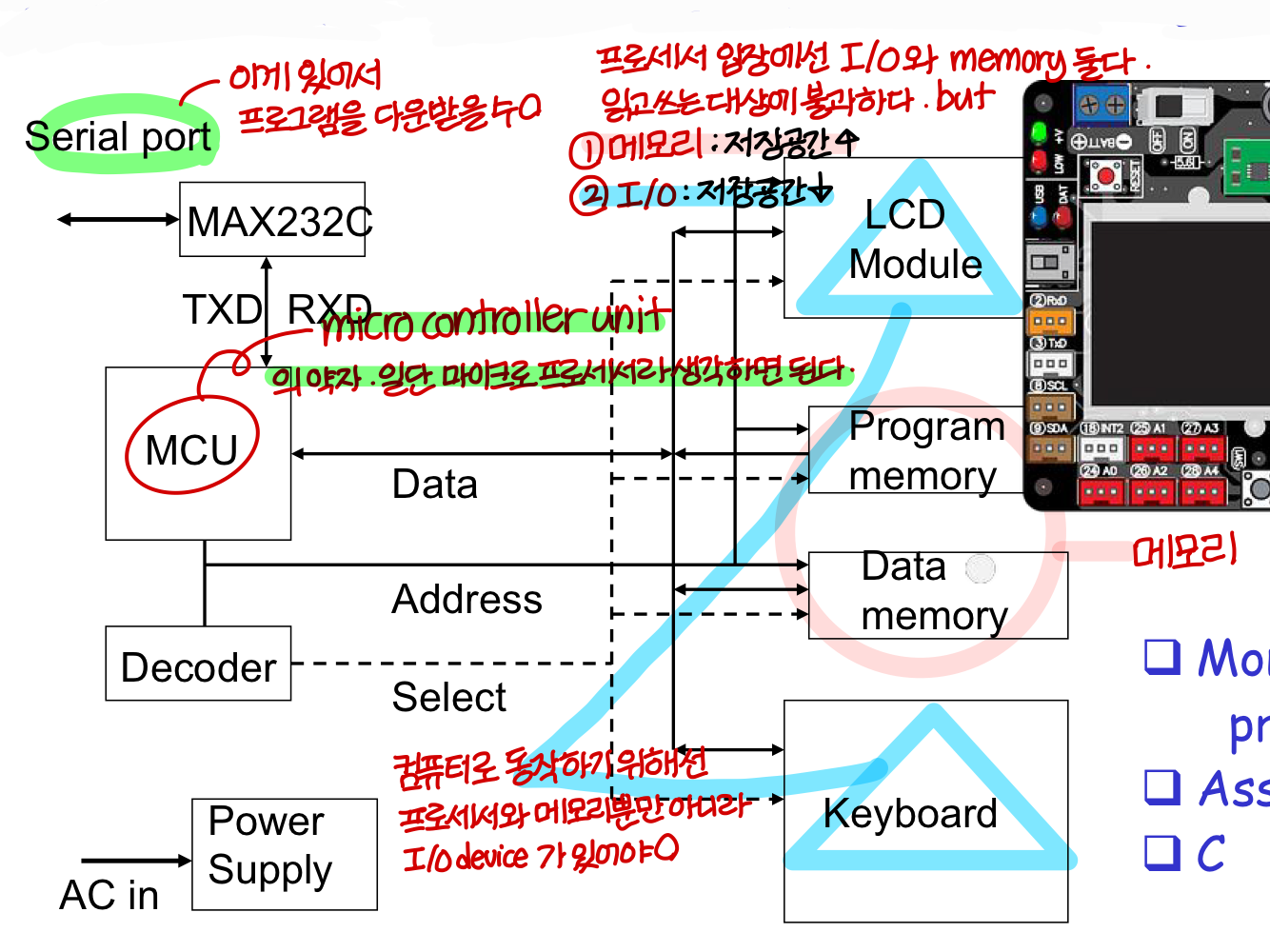
Memory map
- (위의 그림에서 봤듯이) processor 입장에선 메모리나 I/O device 모두 읽고 쓰는 대상에 불과
하지만 Program memory에는 많은 Instruction이 들어가야해서 많은 저장공간이 필요하다.
Data memory에도 많은 양의 data를 저장해야해서 많은 저장공간이 필요
반면에 I/O device는 그렇게 많은 저장공간을 필요로 하지 않는다. 그래서 address space도 많이 쓰지X
- 컴퓨터 하드웨어를 설계할 때 program memory, data memory의 address 몇번지에서 몇번지까지?
LCD와 keyboard같은 I/O device는 각각 몇번지를 할당할 것인지?
→ 이렇게 address space를 어떻게 사용할 것인지 결정해야
이걸 바탕으로 하드웨어 설계 및 프로그램을 짤 수 있음
→ 이런걸 Memory map을 결정한다고 표현
Memory Map- 80196 Example (16bit processor의 예)
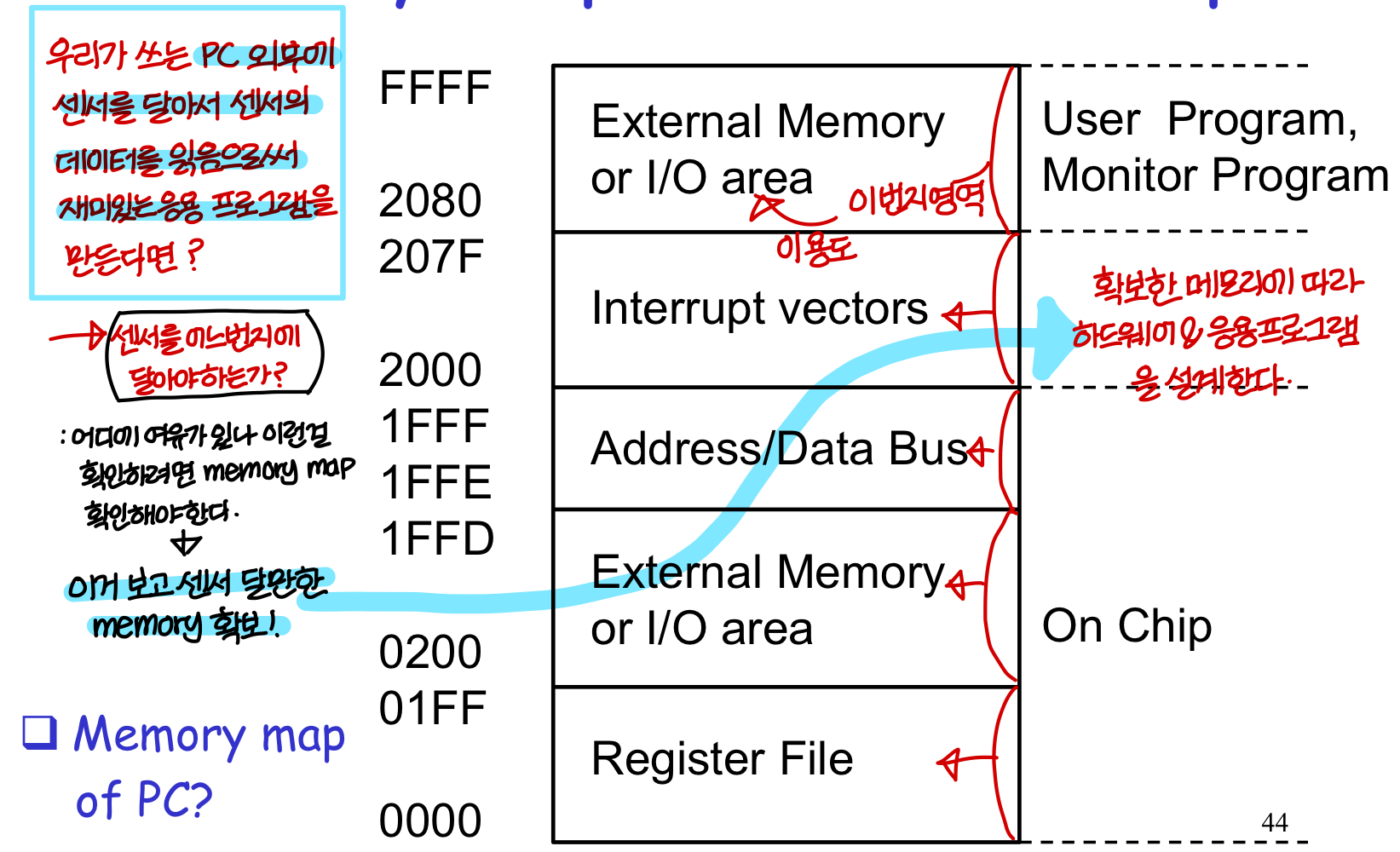
Processor Databook
실제로 embedded system을 만들게 되면 프로세서를 가지고 여러가지 하드웨어 & 소프트웨어를 다루게 되는데
그럼 프로세서에 대한 사용법을 얻어야한다. → Processor Databook에서! (설계법은 몰라도 된다. 사용법만 알면된다)
- ISA(프로그래머를 위한 사용법) : instruction set에 대한 설명이 담겨있다.
- Physical interface(HW designer 를 위한 사용법) : 프로세서 핀에 대한 설명 등 하드웨어를 만들기 위한 정보들이 담겨있음
Microcontrollers
- Embedded system(e.g., 냉장고 controller) 과 관련된 개념
: 임베디드 시스템을 위해 마이크로 프로세서를 만들 때는 반드시 마이크로 컨트롤러 형태로 만든다.
- 마이크로프로세서 + set of commonly used peripherals(주변기기) 가 "싱글칩"으로 만들어진 형태
- 싱글 칩으로 만들면 less expensive, more reliable(크면 선들로 막 연결해야하니까 고장요인이 많아짐), faster
System on Chip(Soc)
→ 마이크로 컨트롤러의 규모, 성능이 높아진 버전
- 요즘은 embedded system도 상당히 powerful해짐. 우리가 쓰는 mobile device의 경우
상당한 power를 갖춘 32비트 프로세서를 사용한다.
→ 이런 powerful한 임베디드 시스템에서도 역시 필요한 모든 기능들이 "싱글칩"에 들어가야함
- 규모가 커지다 보니 마이크로라는 말을 붙이기가 그래서 System on Chip(Soc)라 부른다.
- Mobile AP
AP: application procesor 의미. 특정 application에 비교적 특화되었다는 뉘앙스
Mobile AP의 대표적인게 스마트폰에 들어가는 프로세서. 얘도 SoC(System on Chip) 개념을 사용해서
프로세서와 가능하면 모든 기능들을 싱글칩으로 구성한다.
Mobile AP는 경량, user와의 interface를 담당한다. 실제 할 일이 있으면 멀리 있는 서버에 communication network을
통해 보내, 실제 일을 서버가 하도록 한다.
More on Computers(I/O, Interconnection)
Interconnection
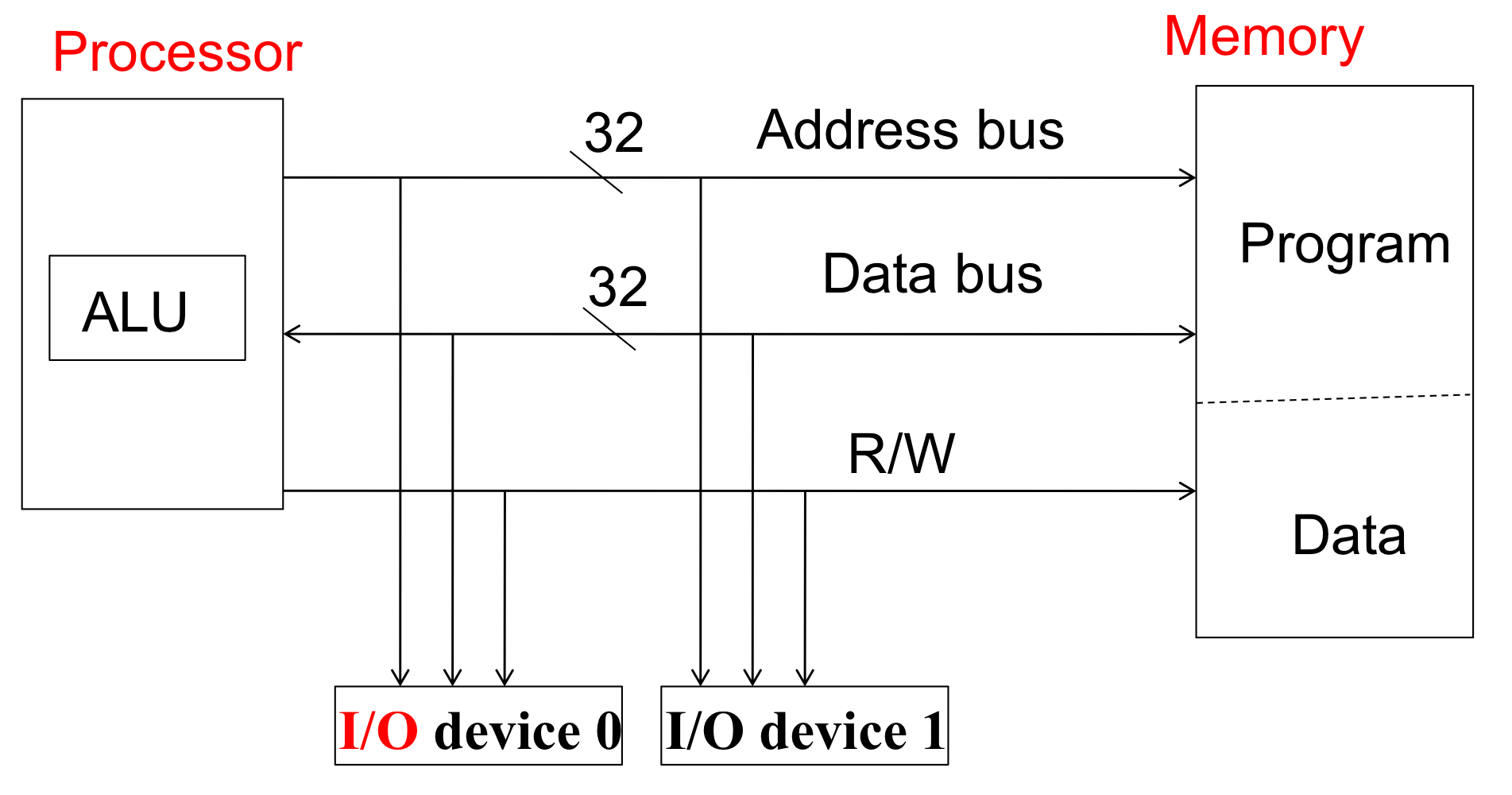
- 컴퓨터라는 머신을 build하게 되면, 불가피하게 여러가지 디바이스들을 연결하게 된다.
PC의 경우 프로세서, 메모리, I/O 디바이스가 서로 연결된다. 이들을 어떻게 연결할까?
→ 1) Unique addressing: 여러개의 component를 연결하려면 각자가 고유의 주소를 가지고 있어야한다.
나는 누구다!라고 말할 수 있어야 통신이 된다.
2) Routing: component 사이에 어떻게 메세지를 전달할건지
(인터넷을 예로 들자면 Unique addressing을 위해 IP주소를 사용하고 Routing을 위해 TCP/I 알고리즘을 사용한다.)
- Bus
: Shared medium을 놓고 연결하고자 하는 것들을 medium에 map 시키는 방식을 의미한다.
→ 간단하고, 비용이 적게 들고 제일 널리 쓰인다.
→ 하지만 한번에 하나만 보낼 수 있기 때문에 performance 적으로 한계가 있음.
컴퓨터 내부의 여러 component 들을 연결하는데는 문제가 없지만
데이터 센터나 슈퍼컴퓨터에서처럼 아주 많은 프로세스들을 연결하고 싶을때는 사용 못함
→ Unique addressing을 위해 연결되는 컴포넌트들은 고유의 id가 배정되어 있어야한다.
→ routing 문제 고민안해도 됨. medium이 공유되어 있어서 한 친구가 신호 보내면 다 받음(broadcast)
→ 버스에 연결된 디바이스들은 버스를 지금 누가 사용하는지 확인하고 사용해야한다.
이 과정을 "Bus arbitration"이라고 한다. 이게 표준화가 되면 bus protocol 이라고 한다.
- Fully connected
→ 가장 비싼 방식. 가능한 모든 조합을 다 연결한다. pair 별로 전용링크를 만든다.
→ 프로세스 N개 있으면 N(N-1)/2 개의 링크 만들어야함 (complexity N^2)
→ IP 주소로 unique address 매기고 TCP/IP 알고리즘으로 routing
→ 실용도가 떨어진다.
- Bus와 Fully connected는 극단적인 경우. 그 사이에 서로 다른 가성비를 갖는 많은 interconnection 존재
PC에 사용되는 BUS
PC에는 크게 2가지의 bus가 사용되고 있다.
1) Processor-memory bus: proprietary
→ 이 설계는 프로세서 전문 업체와 메모리 전문 업체가 협의해서 만든다. 따라서 각 프로세서 설계 회사마다 독자적인 연결방식 사용
2) I/O bus: standard (industry-driven)
→ 많은 peripherals(주변기기)가 연결되는 부분. 표준화된 버스를 사용하는 것이 가장 중요하다
→ 디스크 컨트롤러를 만드는 사람이라면 표준화된 버스에 맞춰 제작한다음 완성했을 때 바로 Plug and Play가 되어야하기 때문
More on Computers(I/O , Interrupts)
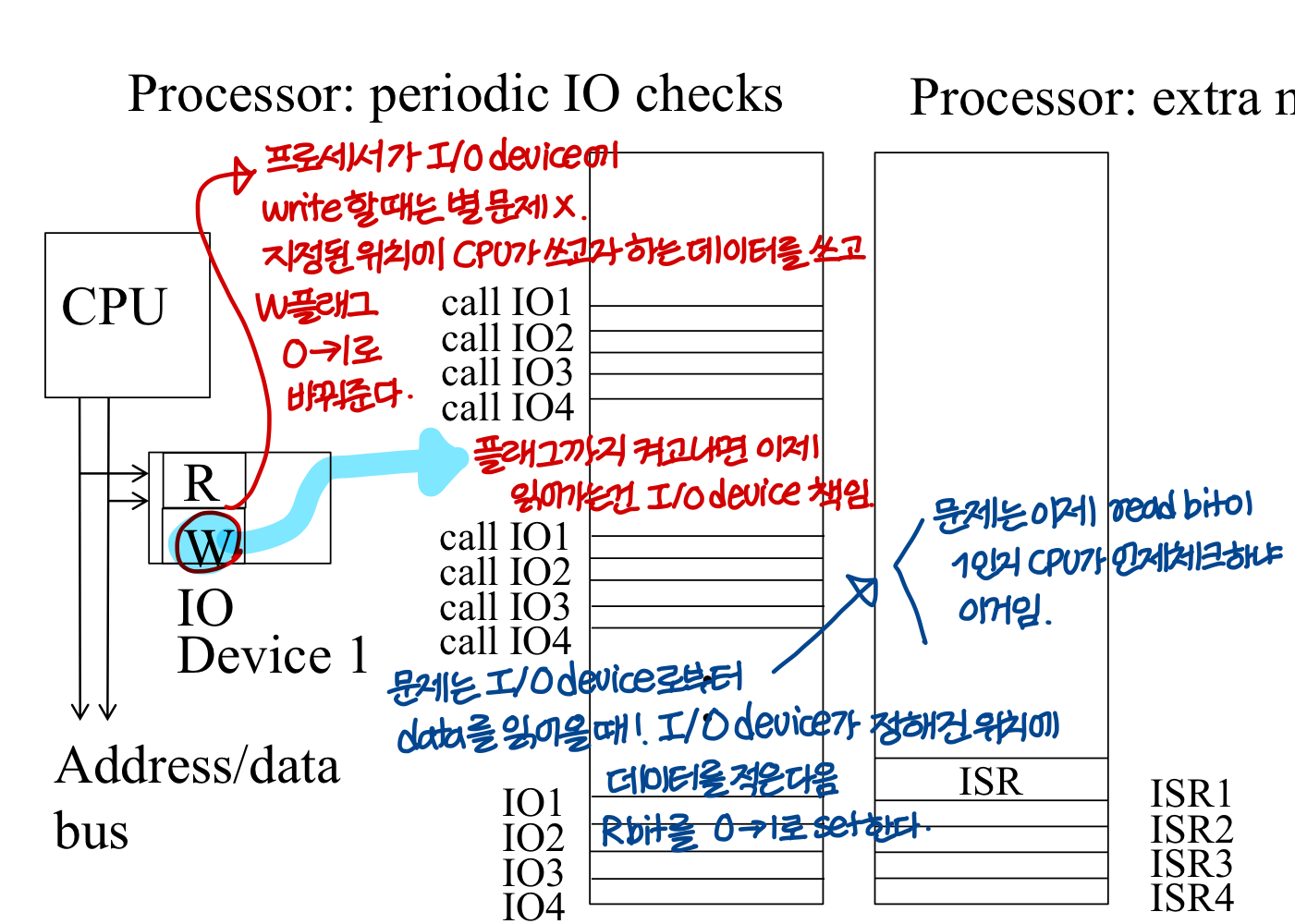
Programmed I/O vs Interrupt
I/O 디바이스: 굉장히 수가 많고, 느리다. 그리고 간헐적으로 사용됨
- Programmed I/O
: 주기적으로 existing hardware를 체크하는 방식
→ I/O 디바이스에 write는 문제 없음. 하지만 read 해올 때가 문제
주기적으로 I/O 디바이스를 체크해서 읽어올게 있는지 확인한다.
→ 주기적으로 체크해야한다는 사실이 프로세스에게 부담스러움, "Response time"이 존재하는 경우 더 부담스러움

- Interrupt
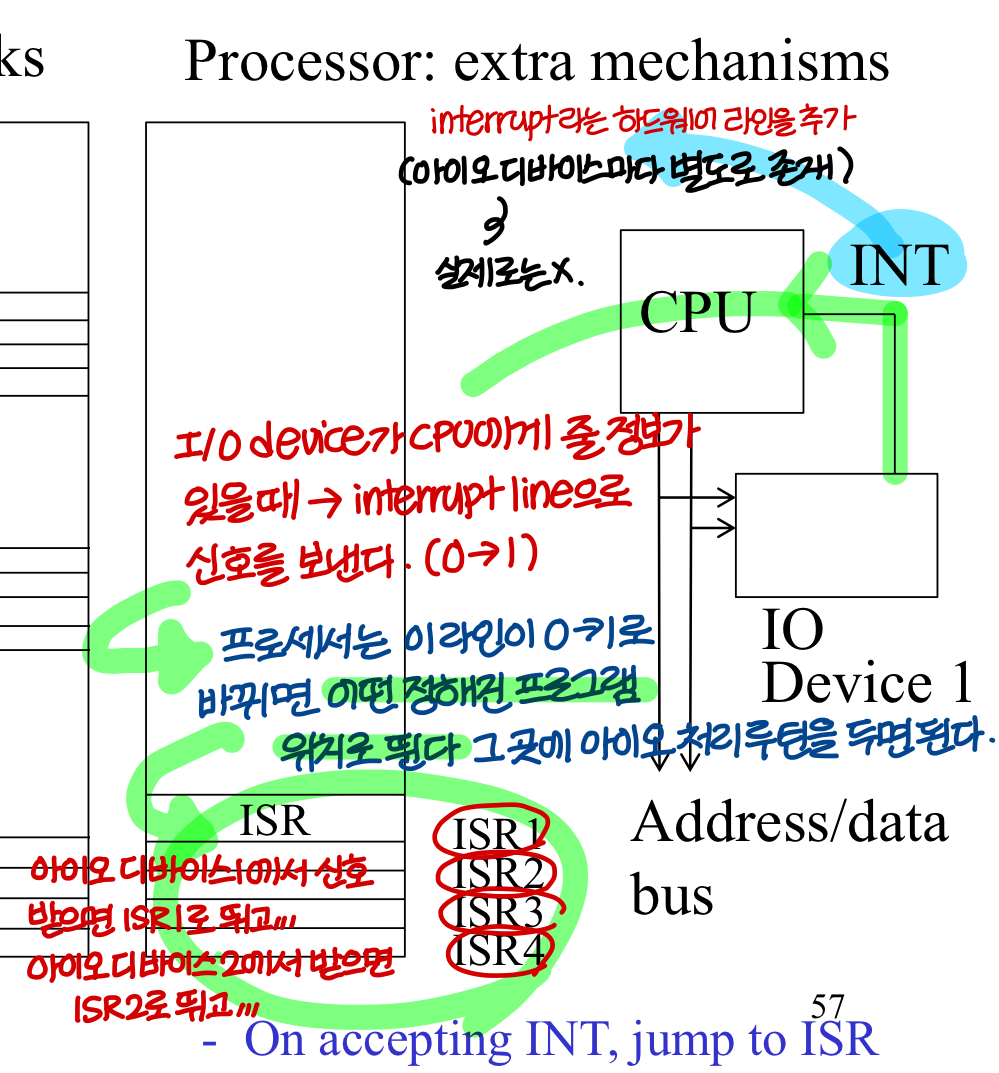
→ I/O device와 데이터를 주고받기 위해 특별한 하드웨어를 추가하는거임
→ interrupt 메커니즘을 사용하면 I/O 디바이스가 주기적으로 체크할 필요가 없어서 I/O의 효율이 상승
→ 특정 interrupt line에서 신호가 들어오면 PC값과 레지스터 값을 정해진 위치에 저장해놓고
PC값을 정해진 위치로 바꾼다. 바뀐 위치에서 I/O 루틴이 돌아가게 되고(마찬가지로 Fetch-Decode-Execute로) 이게 다 끝나면
원래 위치로 돌아가야함. 그러기 위해서 특별한 instruction인 IRET가 필요
IRET 실행하고 나면 PC와 레지스터값 복원
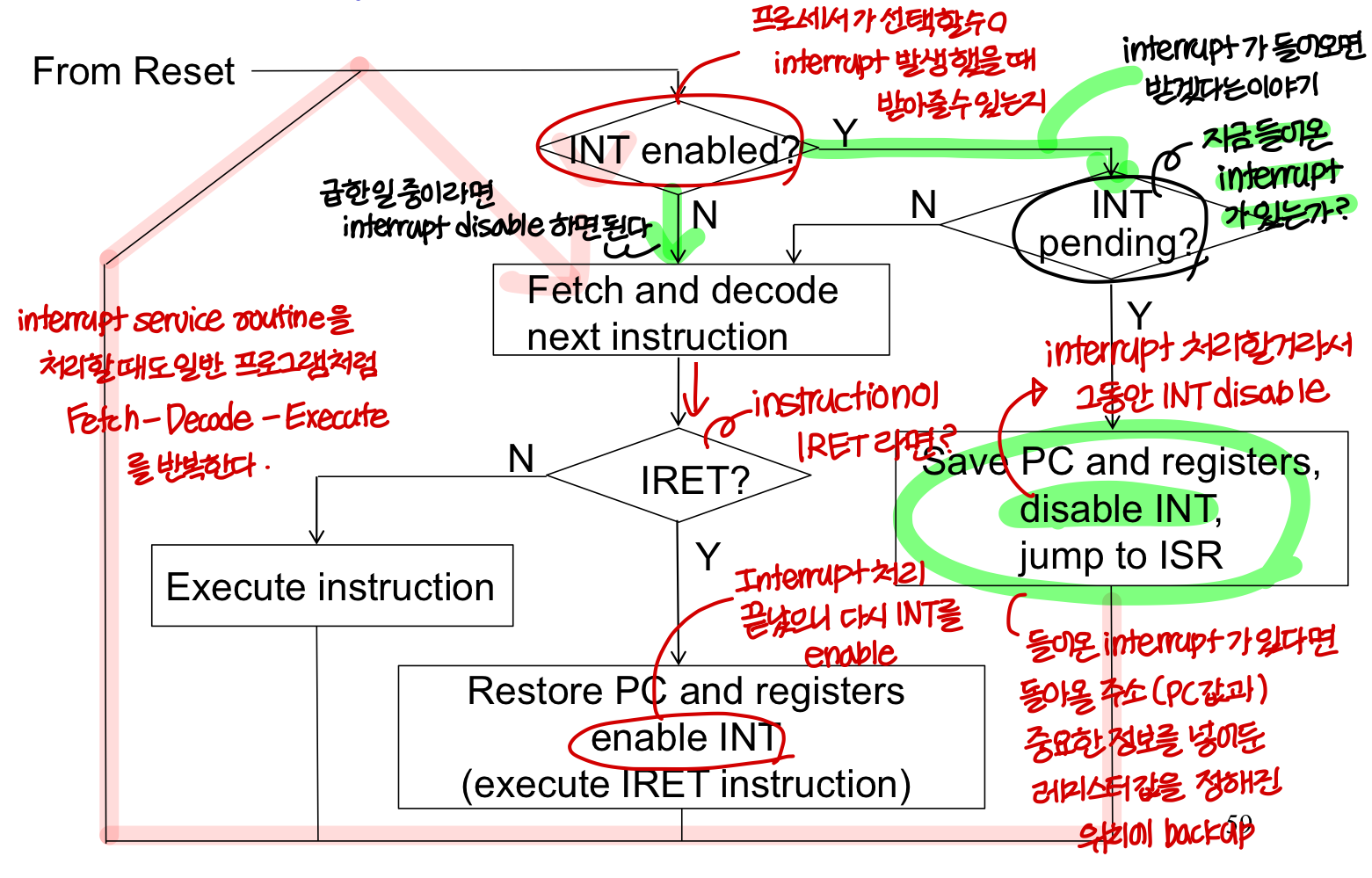
→ interrupt line이 I/O device 마다 있는건 아님. 그렇게 하면 너무 많이 필요함.
interrupt line 하나에 여러개의 I/O device들이 연결되어있음.
→ Interrupt Nesting : interrupt service 수행하다가 또 다른 interrupt를 받는거
우선순위에 따라 중간에 멈추고 새 interrupt 처리할지 무시하고 하던거 다 처리할지 결정
Interrupt Processing and F-E-D
Multiple INTs and INT Priority
- Interrupts vs exception
→ 유사하지만 다르다.
→ Interrupt: 프로세스가 외부 device(I/O device)랑 데이터를 주고 받기 위해 쓰는 방식
→ exception: 프로그램 중 사정이 생겨서 나 봐줘!! 하는거
(범용 컴퓨터에서는 두 경우 다 OS가 불려진다.)
Interrupt Nesting
- Interrupt service 루틴을 수행하다가 또 다른 interrupt를 받는걸 Interrupt Nesting이라고 한다.
- Interrupt 처리 하던 중 자신보다 우선순위가 높다면 중간에 받아주고 아니라면 무시하고 처리하던 ISR 계속 수행한다.
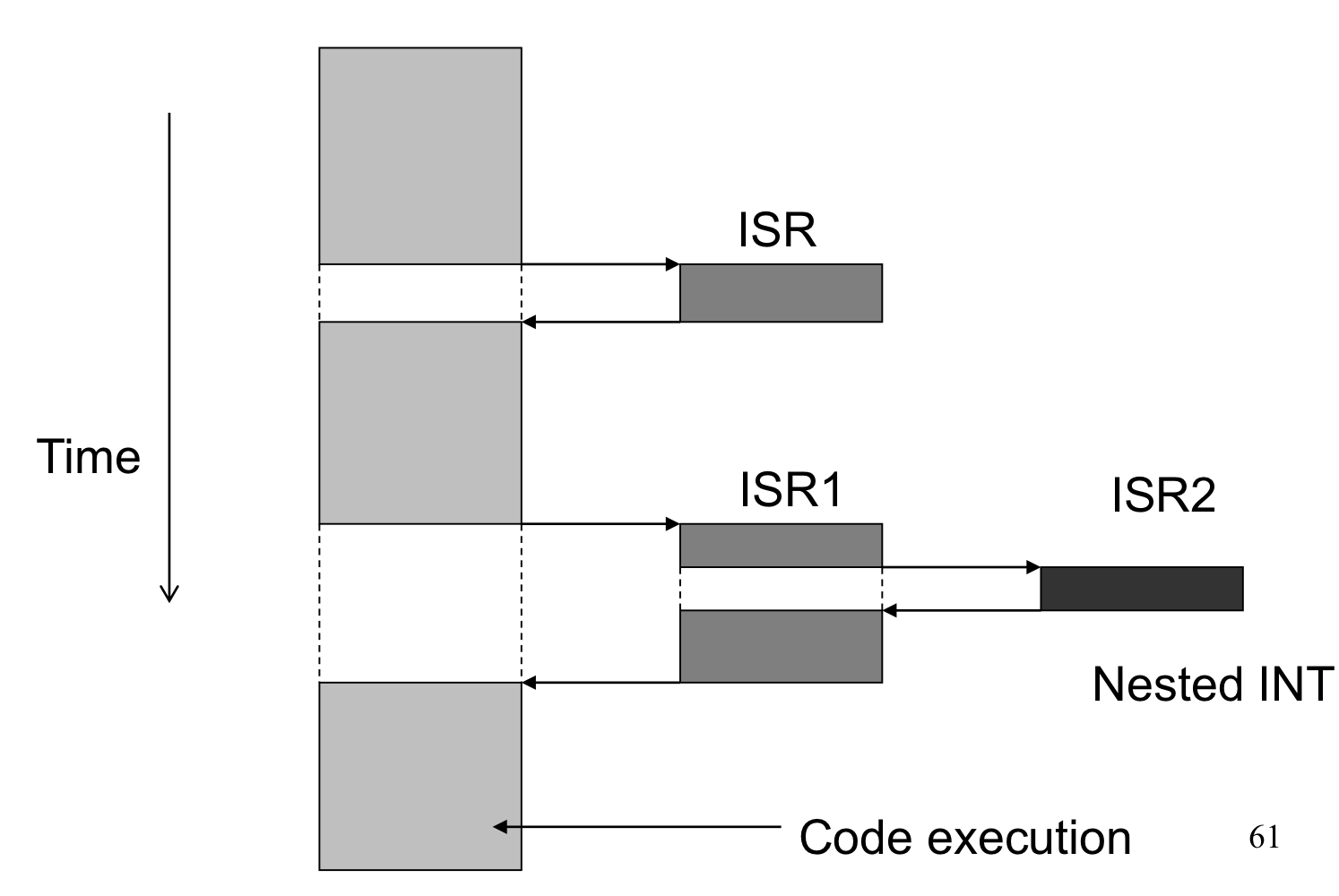
→ 위의 경우는 ISR1의 우선순위보다 ISR2의 우선순위가 더 높은 경우
→ 만약 아니라면 ISR1이 중간에 중단시키지 않고 끝까지 돌린다.
Atomic(all or nothing) Operation
- 컴퓨터에는 special 한 instruction 있음 : enable INT, disable INT 등
→ 근데 enable INT랑 disalbe INT는 범용 컴퓨터에 존재하지만 쓸 수 없음. privileged instruction이라 커널모드에서만 쓸 수 있음
- machine instruction은 atomic operation이다.
→ Fetch가 되면 일단 execute까지는 보장한다.
→ 시작하면 다 실행하고 아니라면 아예 실행을 하지 않는다.
→ Fetch 전에 interrupt 들어왔는지 체크하고 Fetch 했으면 무조건 decode, execute 까지 연속적으로 실행한다.
F-D-E 중간에 interrupt 걸리는일은 허용하지 않는다.
- 하나하나는 무조건 atimic. 그런데 Sequence of machine instructions 이 atomic하게 실행되어야하는 경우도 있음
→ Critical section in OS, Transaction in database
- atomic operation의 구현
→ 작은 embedded system일 경우 "enable INT"와 "disable INT" instruction으로 구현 (우리 그림에서 봤듯이)

→ 범용 컴퓨터에서는 위의 instruction으로 구현 못함.
일단 다음 Instruction이 범용 컴퓨터에선 프리빌리지드 instruction이라 커널 전용이라 일반 유저들은 사용할 수 없음.
또한 범용 컴퓨터엔 많은 프로세스들이 존재하는데 이들 모두 다 연관이 되어있는게 아니다. 많은 unrelated process들이 존재한다.
그런데 critical sections 또는 tranactions이 발생하는 건 shared resource를 공유하는 소수의 프로세스들 사이에서 발생하는 문제 해결 위한거임
대부분의 프로세스는 특정 resource와 관련이 없다. 근데 우리가 atomic한 operation을 위해 disable INT/ enable INT를 쓰게 되면
모든 프로세스들이 다 영향을 받게 된다.
우리가 disalbe INT를 하면 timer interrupt도 disable 될텐데 → 이러면 OS는 시간 기준을 잃어서 프로세스 스케줄링이 엉망이 된다.
이런 일이 발생해서는 안된다.
대신 special instruction인 "synchronization Instruction" 사용 → 이걸 이용해서 라이브러리 디자이너들이 lock library를 만들었는데
이걸 쓰면 atomic 한 operation을 구현할 수 있다.
Atomicity and Recoverability
- 복잡한 SW는 한 덩어리로 만들지 않는다. 여러개의 모듈로 나누어서 만든다.
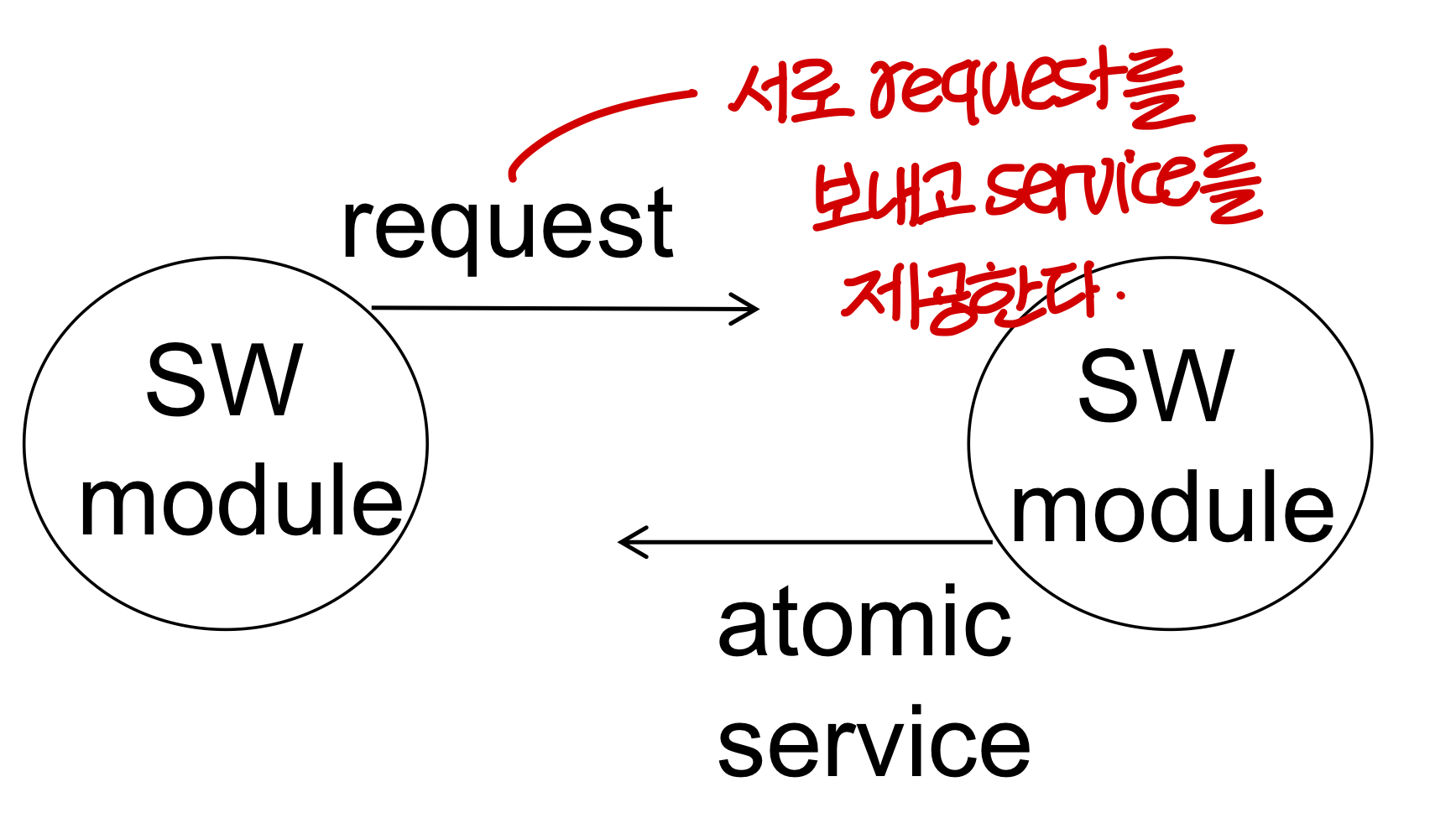
- 소프트웨어를 만들 때 각 모듈에 전혀 버그가 없다면 좋겠지만 현실적으로 그건 어렵다.
→ 그럼 중요한게 Recoverability! (Recoverability를 높이기 위해선 Atomicity를 높여야한다.)
- 예를 들어, 어떤 소프트웨어 모듈이 request에 대해 atomic service를 보장해주면 확인하기 굉장히 편하다.
→ All or nothing이기 때문에 request가 처리 되었는지 안되었는지만 확인하면 된다.
Uploaded by N2T