
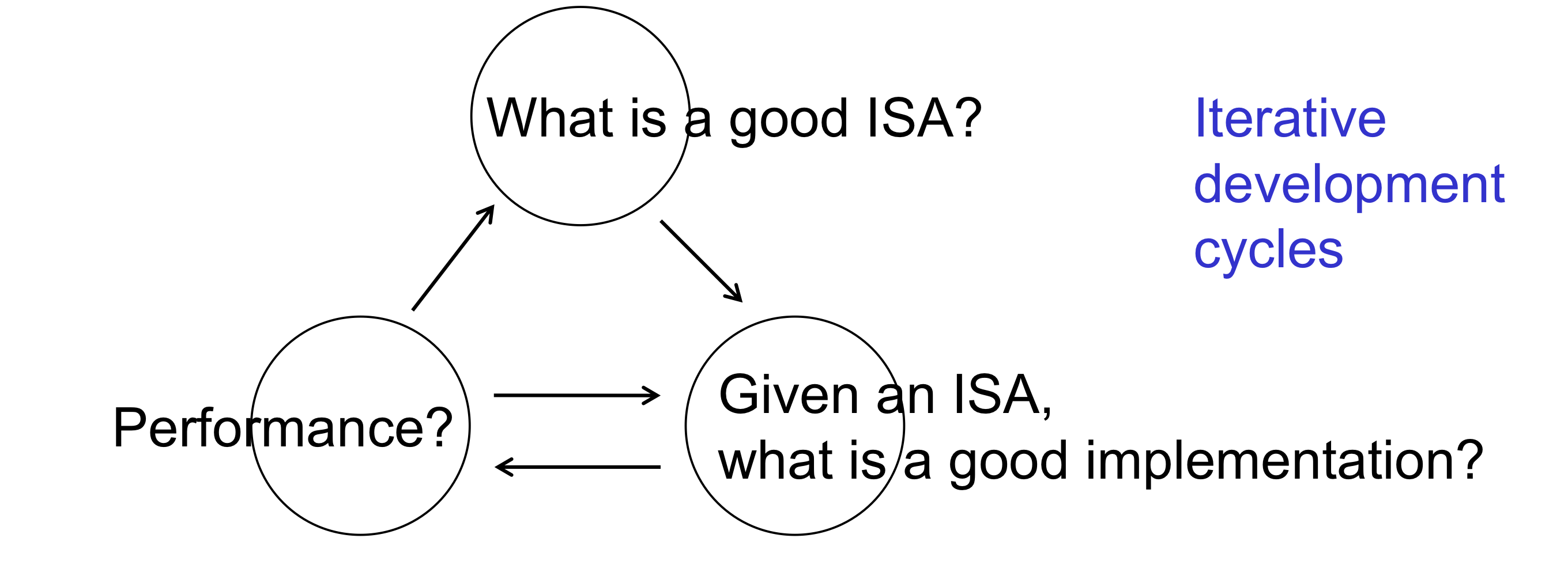
Product Development Paradigm
제품 개발하는 과정 <Iterative development cycles>
: implemenation 하다가 interface 수정하기도 하고 requirement 수정하기도 하고~~
- Marketing requirements analysis and planning
- 어떤 제품을 개발해야 잘 팔릴까. 어떤 제품이 새로운 시장을 생성할 수 있을까 고민하고 아이디어를 낸다.
- Design and implementation
- External interface
: 인터페이스가 먼저 설계되어야한다. interface는 제품의 성능과 기능을 모두 함축하고 있다.
: interface는 외부의 user에게 보이는 거기 때문에 External 이라는 말을 붙인다.
- Internal implemenation
: Implemenation은 user가 몰라도 되는 부분. user로부터 가려졌기 때문에 internal이라는 용어를 붙임
😄인터페이스가 선행되어야한다고 했지만, 사실 인터페이스를 100프로 설계하고 implemenation 에 들어가는건 아니다. iterative하게 진행한다.
- External interface
- Testing and release
- 개발이 끝나면 기능, 성능 test에 들어간다. 성능을 만족 못하면 다시 앞과정으로 돌아갈 수도 있음.
- 원하는 기능, 성능이 나오면 시장에 출시되고 고객의 평가를 받게 된다.
고객들이 사용을 하고 생긴 요구사항들을 반영하고 경쟁사들과 경쟁을 하기 위해 위의 과정이 반복적으로 일어나면서 제품이 enhance 된다.
→ 위의 과정은 기업에서 소프트웨어를 개발할 때도 일어나고, 하드웨어를 개발할 때도 일어난다.
→ interface가 implemenation에 선행되는 개념이지만 위 과정 자체가 iterative 하기 때문에 왔다갔다한다.
Big Picture
Issue1: Fundamental concepts and principles → 저번 챕터에서 배운거
Issue2: ISA design (external I/F Design) → 이번 챕터에서 배울거
Issue3: (High-level) implementation of ISA
핵심 질문) 어떤 ISA가 좋은 ISA인가?
→ 좋은 ISA는 성능이 좋아야하는데, 질문에 대한 답을 하기 위해 'Performance'에 대해 잘 이해하고 있어야한다.
→ ISA 디자인이 일단 주어졌을 때, 이 ISA를 어떻게 구현해야 빠른 컴퓨터를 만들 수 있을까?
구현이 끝나면 'Performance'를 확인하고 다시 구현을 할 수도 있고 아예 ISA 디자인을 고칠수도 있음.
(위 과정도 Iterative하게 일어난다.)
Computer Performance Evaluation
컴퓨터 performance를 evaluation 하는게 왜 중요할까?
- computer performance 를 evaluation 할 수 있어야 우리가 컴퓨터를 구매할 수 있음
→ 우리가 data center를 업그레이드 하는 프로젝트에 투입된다면, 우린 컴퓨터를 매우 똑똑하게 구매해야함. 막 사면 안된다.
- (수업에서 초점을 두는 부분) 디자인 과정에서 이런 선택을 하면 어떤 성능이 나올까? 저런 선택을 하면 성능이 어떻게 나올까?
이런 수많은 질문들을 하게 되는데 이런 질문에 답하기 위해!
질문의 예) LD R1, R31(+1) vs LD R1, R31, 0x10000001 → 앞에꺼 쓰는 이유는?
Paradigms
computer performance evaluaiton을 하기 위해 새로운 패러다임을 배워야한다.
→ Quantitative engineering paradigm 중에서도 Cost-performance trade-off 패러다임!
Key Question (Quantitative Eng. Paradigm)
<Engineering>
- 엔지니어링이 성공하기 위해선 가성비가 좋아야한다.
→ Cost/performance trade off
→ 여기서 performance는 속도, 내구성 등 여러가지를 통칭하는 일반적인 개념임
- 엔지니어링은 숫자와 측정으로 하는 분야이다.
→ 엔지니어링은 숫자(number)로 표현된다. 즉, quantitative game이다.
→ 숫자로 나타내기 위해선 Measurement 이 필요하다.
<Three Key Question>
1) 무엇을 측정해야하나? (Performance measures) → 일반인들도 어느정도 질문에 대한 답을 할 수 있음
2) 어떻게 측정해야한다? (Evaluation methods) → 일반인들이 답할 수 있는 질문도 있고, 없는 질문도 있음
→ 제 3자가 납득할 수 있을 정도로 각각의 평가잣대에 대한 측정방법을 정의해야한다.
3) 어떻게 향상시키나?
→ 여기서 나오는게 Performance model) 어떤 요인들에 의해 performance가 결정되는지 나타내는 모델
→ 전문 지식이 필요하다. 일반인들은 답변 못함.
😄 이번 수업에서는 Computer에 대해 quantitative Eng. paradigm 을 적용할거임.
Power of Single Number
숫자가 여러개 나오면 비교하기가 곤란. (이부분에 대해선 얘가 높고, 저부분에 대해선 쟤가 높고..)
→ 그래서 컴퓨터에 대한 performance evaluation 을 할 때에는 가능하면 성능이 single number로 표현되도록 노력해야함.
Quantitative Engineering - Computer Performance
이제 quantitative Engineering 패러다임의 3개 핵심 질문에 대해서 알아볼거임.
(사실 이건 컴퓨터에만 중요한게 아니라 엔제니어로서 본능같은 것이다.
엔지니어들이 quantitative Engineering 패러다임을 모른다면 엔지니어링을 할 수 없음. 이런 선택을 하고 저런 선택을 했을 때 성능이 어떻게 달라지는지
대답을 할 수 없다면, 그건 엔지니어링이 아니다. )
(또한 기업 입장에서 개발자들은 항상 quantitative Engineering을 통해 성능을 측정하지만, 소비자들은 제품 성능의 비교를 쉽게 하지 않길 바람
만약 성능이 쉽게 비교가 되면 가격을 높게 받기가 힘들기 때문. 비교가 힘들어야 가격을 많이 받을 수 있다. )
1) 무엇을 측정해야하나?
Computer Performance: Time, Time, Time
- response time
: 주어진 일을 얼마나 빨리 처리하느냐?
→ 대부분의 유저들은 computer performance를 response time으로 비교한다고 생각하지만 일부 유저들은 다르게 생각하기도 한다.
- Throughput
: 주어진 시간에 얼마나 많은 일을 할 수 있는가?
→ 단위 시간당 transaction을 몇개나 처리할 수 있는지, 혹은 동시에 몇만 유저를 서비스할 수 있는지?
→ data center 에서 일하는 사람들은 response time 보다는 throughput이 더 중요한 척도라고 생각하고 일한다.
- 우리는 이 둘중에서 'response time'이라는 잣대를 사용할거임. 그 이유는?
(1) response time이 빨라지면 throughput 이 자동으로 좋아진다.
(2) 컴퓨터를 설계하는 사람이 throughput으로 실험을 하기가 어렵다.
throughput으로 실험을 하기 위해서는 대규모의 서버가 필요. 대규모의 실험을 매번 하기는 어려움
- response time과 throughtput은 서로 연관성이 있다. 이 둘은 다음의 상황에 어떤 영향을 받을까?
1) 우리가 쓰는 컴퓨터의 프로세서를 2배 빠른 프로세서로 교체한다면?
→ response time 은 반으로 줄고, throughput 은 2배로 는다.
2) 우리가 사용하고 있는 컴퓨터에 기존 프로세서와 똑같은 프로세서를 사서 추가한다면?
→ 우리가 사용하는 응용 프로그램은 대부분 싱글 프로세서에서 돌아가게 되어 있다. 프로그램을 바꾸지 않는 한, response time은 동일
(프로세서가 2개 있더라도 프로그램은 하나의 프로세서에서 돌아가기 때문에 response time이 개선되진 않는다.)
→ 프로세서 2개니까 각각에 다른 일을 주면 throughput 은 2배가 된다.
→ 프로세서를 추가했을 때 response time 을 줄이고 싶다면 parallel programming 을 해야한다.
Multiprocessor Systems
- Parallel programming
- 문제는 하나인데 이걸 해결하는데 많은 시간이 소요된다.
그래서 이걸 여러개의 프로세서에게 일을 나눠줌으로써 프로그램을 빨리 끝나게 하는 프로그래밍이다.
- Super computer(scientific computing) 가 parallel programming을 한다.
- response time 에 초점을 둔다.
- 문제는 하나인데 이걸 해결하는데 많은 시간이 소요된다.
- Natural parallelism (Parallel programming과 대비되는 개념.)
- 각 프로세서들에게 independent 한 일을 하게 한다.
- Data center(business computing)이 Natural parallelism 을 한다.
→ 각자의 작업은 independent 하다.
- 따로 parallel programming 을 하지 않아도 일 자체에 자연적인 parallelism 이 있기 때문에 Natural parallelism 이라고 부른다.(?)
- throughput 에 초점을 둔다.
Execution Time(Designer Perspective)
- UNIX utility: "time a.out"
→ UNIX 머신에는 타임이라는 utility 프로그램이 하나 있다. 실행파일 이름 앞에 time 이라고 치게 되면
똑같이 a.out 이라는 프로그래을 실행시켜주는데 time이라는 프로그램이 a.out 프로그램을 실행하는데 걸린 시간을 측정해서 보여준다.
- 90.7s 12.9s 2:39 65%
→ Elapsed time: CPU time + I/O time = 2:39 = 159s
→ User and system CPU time: 103.6s (앞의 두 시간 합친 결과)
CPU가 103.6s 만큼 바빴다는 의미
첫번째 숫자 90.7s: User CPU time) 유저모드에서 유저코드를 돌리느라 CPU가 바빴던 시간
두번째 숫자 12.9s: System CPU time) 유저프로그램이 시스템 콜을 해서 커널모드에서 커널코드를 돌리느라 CPU가 바빴던 시간
→ I/O time: 159s - 103.6s = 56.4s
CPU가 I/O 장치에 요청을 한 뒤 아직 답이 안와서 기다린 시간이다.
- 위와 같은 시간 분류가 필요한 이유가 무엇일까?
컴퓨터는 여러 다른 그룹이 모여서 만들어진 결과물이다.
1) I/O 디자이너들은 I/O time 을 줄이려고 할거임
2) 프로세서 디자이너는 유저 CPU time을 줄이려고 할거임
3) 커널 디자이너는 system CPU time을 줄이려고 할거임
→ 이렇게 프로그램을 돌리는 유저들은 전체 실행시간(total response time = elapsed time)이 보이지만, 실제 설계하는 사람들은 시간을 통째로 보지 않기 때문
😄 프로세서는 바뀌어도 커널이 바뀌지 않는다면 User CPU time과 Kernel CPU time을 같이 생각해도 좋다.
만약 커널이 그대로 유지된다면 프로세서가 빨라질 때 User CPU time도 줄어들고 System CPU time도 줄어들것이다.
즉, 커널이 바뀌지 않는다면 (User CPU time + System CPU time) CPU time을 줄이는게 프로세서 디자이너의 관심사
Relative Performance
- Performance = 1/Execution time
퍼포먼스는 execution time의 역수
- Performance_x/Performance_y = n
x는 y보다 n 배 빠르다고 표현할 수 있다.
- Problem:
Machine A runs a program in 20 seconds
Machine B runs the same program in 40 seconds
→ 이럴 때 A는 B보다 2배 빠르다고 할 수 있다.
2) 어떻게 측정해야하나?
첫번째 질문에 대한 답 → Response time 을 측정해야한다. 그럼 두 번째 질문에서는 이걸 어떻게 측정할것이냐?
Choosing programs to evaluate performance
- 일반인들에게 어떻게 측정해야하나 물어보면 답이 간단하다.
→ 자기가 자주 쓰는 프로그램 돌려보면 되지~
- 컴퓨터 디자이너들 입장에선 조금 다르다.
컴퓨터를 설계하면 많은 사람들이 다양한 응용 프로그램을 돌리게 된다.
→ 하나의 프로그램만 돌려서는 response time 을 정확하게 측정했다고 보기 어렵다.
그래서 많은 사람들이 사용하는 다양한 실제 프로그램들을 대표할 수 있는 프로그램을 모으게 된다.
이런 프로그램 집합을 Benchmarks 라고 부른다.
→ 벤치마크 프로그램들을 정한 뒤에 response time을 측정하게 되는데
이런 과정을 Benchmarking 이라고 부른다.
Many Benchmarks (SPEC)
- 컴퓨터는 종류도 많고 응용 분야도 많기 때문에 아주 많은 벤치마크가 정의되어 있다. 여기서는 SPEC에서 만든 벤치마크를 소개할거임
SPEC 이라는 비영리기관 내에서 많은 벤치마크를 연구하고 있지만 그 중에서도 아주 성공적이였던 CPU benchmark를 살펴보자
- SPEC의 CPU benchmark
→ 우리가 흔히 쓰는 머신들의 프로세서 퍼포먼스를 측정할 때 많이 사용한다.
→ 프로세서 성능이기 때문에 computation-intensive한 프로그램을 돌려서 성능을 측정한다.
→ CPU 2017 (89, 92, 95, 2000, 2006)
89년에 처음 만들어지고 90년도 전후까지는 굉장히 자주 개정을 했다. 프로세서 성능이 매우 빠르게 발전해서
과거에 설정했던 벤치마크 프로그램이 너무 빨리 돌아서 제기능을 못했기 때문.
21세기에 들어와서는 프로세서의 발전 속도가 비교적 느려지면서 개정이 자주 일어나진 않음. 가장 최신 버전은 2017 버전
😄 우리가 살펴볼 건 2006년도에 만들어진 벤치마크
SPEC CPU Benchmark 2006
- Integer 벤치마크와 FP 벤치마크로 나누어진다.
→ Integer 벤치마크: 프로그램이 인티저 데이터만을 사용한다는 이야기 (총 12개 선정)
→ FP 벤치마크: Integer도 사용하지만 FP를 굉장히 많이 쓰는 계산을 한다. (대부분 과학 계산) (총 17개 선정)
→ 나누어서 하는 이유: 실제로 Integer 연산과 FP 연산은 다르다. ALU 가 따로 존재하기 때문에 나누어서 성능을 평가한다.
- Reference machine and SPECint number

SPEC 에서는 Integer 벤치마크 프로그램 12개를 정의한 다음에 그 당시에 통상 시장에서 얻을 수 있는 컴퓨터 하나를 구매하고
이를 reference machine(기준 머신)이라고 한다. 이 기준 머신을 사용해서 선택된 12개의 인티저 프로그램을 하나씩 돌린다.
그렇게 나오는 실행시간을 Ref time 으로 기록한다.
Ref time을 구하고 나면 SPEC 에서 할 일은 모두 끝났다. 이젠 컴퓨터 회사에서 개발한 컴퓨터의 성능을 위의 자료를 통해 평가하면 된다.
A라는 컴퓨터 회사에서 새로운 컴퓨터를 개발하고 프로세서 성능을 확인하기 위해 SPEC Intger 벤치마크 프로그램 12개를 하나씩 돌려봄
perl을 돌렸더니 637초(Exec time) 만에 끝났다. 그럼 새로 개발한 머신은 기준 머신에 비해 15.3배나 빠르다. → 이걸 SPECratio 라고 부른다.
이렇게 각각의 프로그램에 대해 SPECratio를 다 구하고 이를 평균 낸 number를 SPECint number라고 부른다.
이렇게 SPECint number와 SPECFP number를 통해 상대적으로 내 컴퓨터가 얼마나 빠른지 확인할 수 있다.
Benchmarking
퍼포먼스 벤치마킹을 할 때 고려해야할 몇가지 사항
1) 제 3자가 결과를 재생산 할 수 있어야한다.
벤치마킹이 되면 기업에서는 벤치마크 결과를 사람들에게 알리고 홍보할 수 있다.
이때 결과를 얻을 당시의 hardware configuration, 컴파일 환경 등 측정조건들을 같이 공개해야한다.
→ 이런 공개된 데이터를 가지고 경쟁사에서 결과를 재생산해서 확인해볼 수 있다.
2) 머신의 가격도 같이 공개해야한다.
3) Single number로 나오는 것이 가장 바람직하다.
벤치마킹의 결과는 single number로 나오는 것이 가장 바람직하다. 이 single number 는 기준머신에 비해 몇배 빠른지를 나타내는 숫자
4) Hard to cheat
벤치마크 프로그램은 cheat 하기가 어려워야한다.
컴퓨터를 개발했는데 성능이 생각보다 안나오면 기업 & 개발자들이 곤란해짐. 이런 상황에서 어떤 기업들은 좋지 않은 방법으로 cheat 를 하는 경우가 있다.
(벤치마킹 결과를 억지로 끌어올리는거) 이런게 쉽지 않아야한다.
Many Benchmarks(TPC)
또다른 성공적인 벤치마크 중 하나가 TPC 벤치마크
- TPC라는 비영리기관이 만들어서 성공을 거둔 벤치마크로 대상은 비즈니스 컴퓨팅
- 기업이나 조직에서 쓰는 서버들(transaction processing server)을 대상으로 하는 벤치마킹이다.
- throughput에 초점을 둔 벤치마크이다.
- TPC라는 기관에서 다양한 종류의 벤치마크를 만들었다.
1) TPC-C
아마존 같은 e-commerce 를 대상으로 한다.
우리 서버는 사용자 한사람 한사람에게 타당한 Response time 을 주면서 초당 몇명의 유저를 서버할 수 있다! 이런 performance 를 측정한다.
2) TPC-E
증권회사 같은 곳을 대상으로 하는거.
거래를 할 때 response time을 유지하면서 초당 몇명을 서버할 수 있는가로 퍼포먼스를 측정한다.
3) TPC-H(decision support systems; data mining)
기업에서는 기업이 가지고 있는 데이터베이스를 통해 미래의 경영전략을 구축한다. 그때 쓰이는 벤치마크
Many Benchmarks(PC Benchmarks)
PC 벤치마크라는 것도 존재한다.
→ 일반인들은 PC를 구매할 때 PC 벤치마크 거의 사용안한다.
Clock cycle, memory size, disk capacity, display 를 보면 벤치마크 안돌리고도 얼추 비교가 가능
→ PC를 만들어 파는 제조회사에서는 이런 벤치마크가 필요하다.
우리 회사에서 만든 PC 가 다른 회사에서 만든 PC 보다 얼마나 우수한지 보여주기 위해
Many Benchmarks(EEMBC)
- EEMBC: 임베디드에 필요한 벤치마크를 정의하고 있는 기관임.
- 임베디드 시스템은 종류가 매우 많음. 그래서 EEMBC에서 모든 임베디드 시스템에 대한 벤치마크를 정의하는건 불가능
- 우리가 산업체에서 임베디드 시스템을 설계하고 있는데 벤치마크가 필요한데 없다면, 스스로 벤치마크를 만들어서 벤치마킹 해야함
→ 지금까지 배운 벤치마크 외에도 여러 벤치마크들이 존재한다.
→ 컴퓨터 퍼포먼스에 관한 벤치마크만 있는건 아님. 우리가 흔히 사용하는 consumer product에 대해서도 벤치마킹을 한다.
(quantitive eng. paradigm 에 의거해서)
→ 컨설팅 회사의 경우 기업과 학교같은 곳에 대해서도 벤치마킹을 한다. (마찬가지로 quantitive eng. paradigm 에 의거해서)
3) 어떻게 향상시키나?
이건 일반 사용자의 질문이 아니라 디자이너의 질문이다.
그리고 이 질문에 답하기 위해선 response time이 어떤 요인에 의해 결정되는지 performance model을 알고 있어야한다.
그리고 어떻게 개선할건지 알기 위해선 전공지식(domain knowledge)가 필요하다.
CPU time을 줄이기 전에 CPU clocking에 대해 먼저 살펴보자.
CPU clocking
- CPU 처럼 큰 디지털 회로가 의미있게 협업을 하기 위해선 동기되어 동작해야한다.
그래서 CPU의 모든 회로에는 clock이라는 신호가 제공된다.
- Clock period 와 Clock frequency(rate) 는 역수 관계
Clock period: 한 clock의 지속시간
Clock frequency: 1초에 cycle 몇번 인지
→ 우리는 프로세스 디자이너로서 CPU 타임을 줄이는 것이 목표이다.
😀 n(나노) = 10 ^-9
😀 G(기가) = 10 ^ 9
CPU time

- CPU time을 풀어쓰면 위의 식이 나온다. → 우리는 위의 2식 중 첫번째 식을 주로 다룰거임
- 위의 식 자체를 퍼포먼스 모델로 볼 수 있다. (우리는 더 자세히 쪼갤거지만)
이 모델을 가지고 어떻게 퍼포먼스를 개선할 수 있을까? : clock cycle의 수를 줄이거나, clock cycle time을 줄이거나 하면 된다.\
하지만 주의해야하는건 우리가 하나를 줄였을 때 부작용으로 다른게 늘어날 수 있음.
예를 들어 clock cycle의 수를 줄이면 clock cycle time이 늘어난다.
따라서 한 요인을 개선하면 되겠지? 라는 생각은 매우 단순한 생각
Performance Model
- Clock cycle은 아래의 식처럼 표현할 수 있다.

- 첫번째 식을 아까본 CPU Time에 대한 식에 대입하면 두번째 식이 나온다.
- 이 외에도 다양한 모델들을 생각할 수 있다. 하지만 핵심은 오늘날 우리가 프로세서를 디자인하는데 유용한 모델이냐임. 즉 "효용성"
IC, CPI, cct를 사용하는 두번째 식이 오늘날 프로세서 디자이너들이 사용하는 모델.
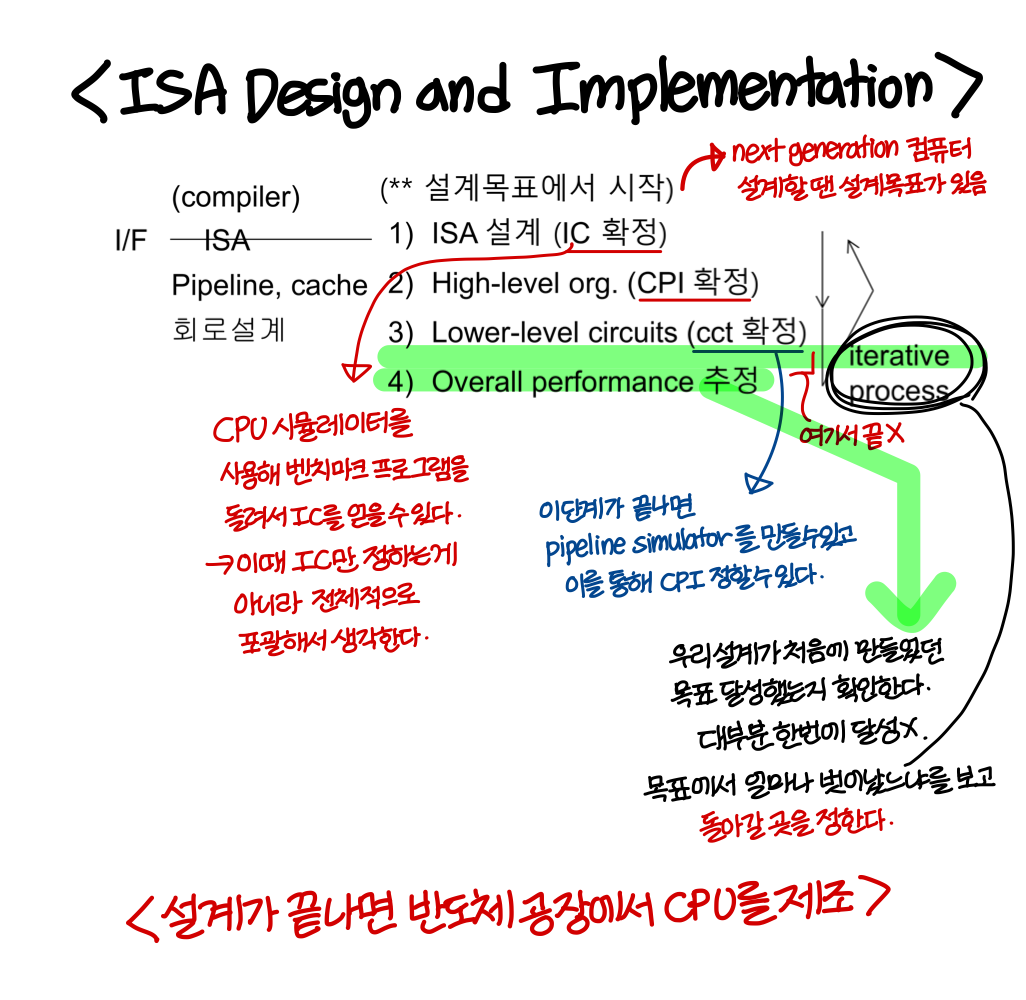
What determines performance?
- CPU time = IC * CPI. * clock cycle time
- 위 3개의 요인은 개발단계와 관련이 있다.
interface design은 implemenation에 선행된다. 그리고 필요에 의해 implemenation 을 2단계로 나누었다.(high level이랑 low level로)
< 위쪽으로 갈수록 상위레벨>
1) ISA: interface design이 끝나면 컴파일러를 설계할 수 있게 된다.
(벤치마킹 프로그램은 high level language이고, ISA 와 HHL(high level language) 사이에 있는게 컴파일러이니까)
그리고 IC 가 확정되게 된다 (CPI과 cct도 결정되는건 아니고 이 단계에서 고려된다.)
2) High-level implementation : 전체적인 구조 설계.
(e.g., 파이프라인을 어떻게 설계할 것인가. 캐시 메모리를 어떻게 할 것인가?)
Pipeline이 확정되면 CPI가 확정된다.
3) Low-level implementation: cct는 하위레벨 설계에서 확정된다.
<아래쪽으로 갈수록 하위레벨>
- 위의 3단계들은 Iterative 하게 진행된다.
- 상위 레벨 설계는 하위 레벨에 영향을 미친다.
(예를들어 ISA 디자인할 때 instruction set 을 RISC 스타일로 만들면 instruction 하나가 하는 일이 줄어든다. 그럼 CPI가 당연히 줄어든다. )
(pipeline 어떻게 설계하는지에 따라 cct가 달라진다.)
- 하위 레벨은 상위 레벨에 영향을 못미친다.
(즉, Implemeation을 개선해도 IC는 불변한다.)
(pipeline 설계를 아무리 다르게 한다해도 ISA가 달라지지 않는다.)
Three Factors: IC, CPI, cct
- IC(instruction count)
→ 최상위 개념
→ 실제 실행되는 instruction의 수 (dynamic number)
→ dynamic(runtime) count를 의미한다.
→ static IC 였다면: static은 compile 타임을 의미하는거. 컴파일 했을 때의 instruction count니까 executable file 크기 의미
→ 같은 프로그램이라도 input data 가 달라지면 IC가 달라진다. (dynamic IC 니까..)
(이런 경우에 비교를 위해서 Input을 고정하거나 여러 Input에 대한 평균을 취하면 된다.)
→ ISA(I/F) 설계에서 결정된다.
ISA가 확정되면, 컴파일러를 설계 할 수 있게 된다.
CPU가 아직 하드웨어로 만들어지지 않은 상태이기 때문에 CPU simulator로 벤치마크를 돌려서 IC를 얻는다.
이에 따라 implemenation(CPI 및 cct)도 영향을 받는다.
- CPI(cycle per instruction)
→ 차상위 개념. high level implemenation에서 결정된다.
→ 정해진 magic number 가 있는게 아니다. 기본적으로 instruction 마다 CPI가 다름. (ex: 더하기는 1 사이클, 곱하기는 5 사이클)
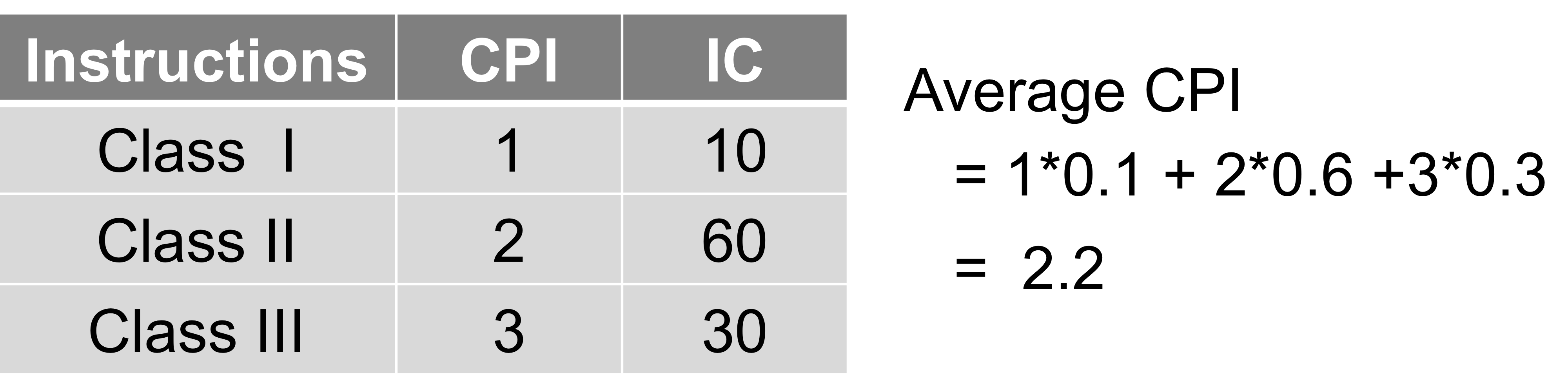
전체적인 CPI를 구하기 위해 빈도를 고려한 Weighted average CPI를 사용한다.
(물론 여기서 빈도는 실제 실행될때의 다이나믹 카운트를 고려한 값이다.)
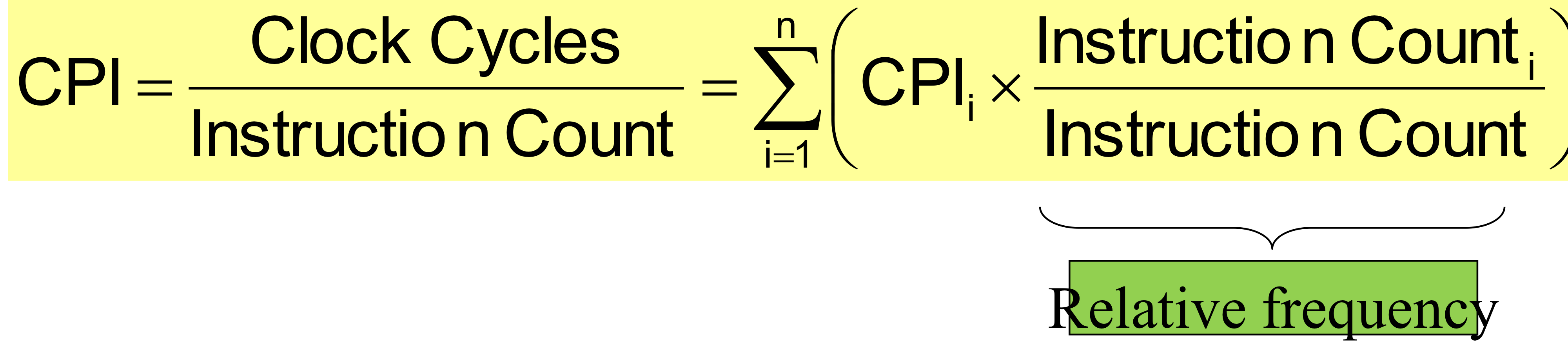
ex) 이런식으로 구한다.
→ 프로그램에 따라, 또 같은 프로그램에서도 input data에 따라 instruction mix가 달라지므로 CPI(average)도 변한다.
→ CPI가 high level implemenation에 의해 결정된다고 했는데 이 부분에 대해 조금 더 자세히 살펴보자.
<high level implemenation에서 사용되는 Key speedup 테크닉>
1) Pipelining
2) Cache memory
: 이 두 기술은 CPI를 줄이는 핵심적인 기법이자 cct에도 영향을 준다. "RISC의 핵심적인 구현 기술"이기도 하다.
- cct(clock cycle time)
→ 하위 개념. low-level implemenation
→ clock 한주기의 길이를 의미한다.
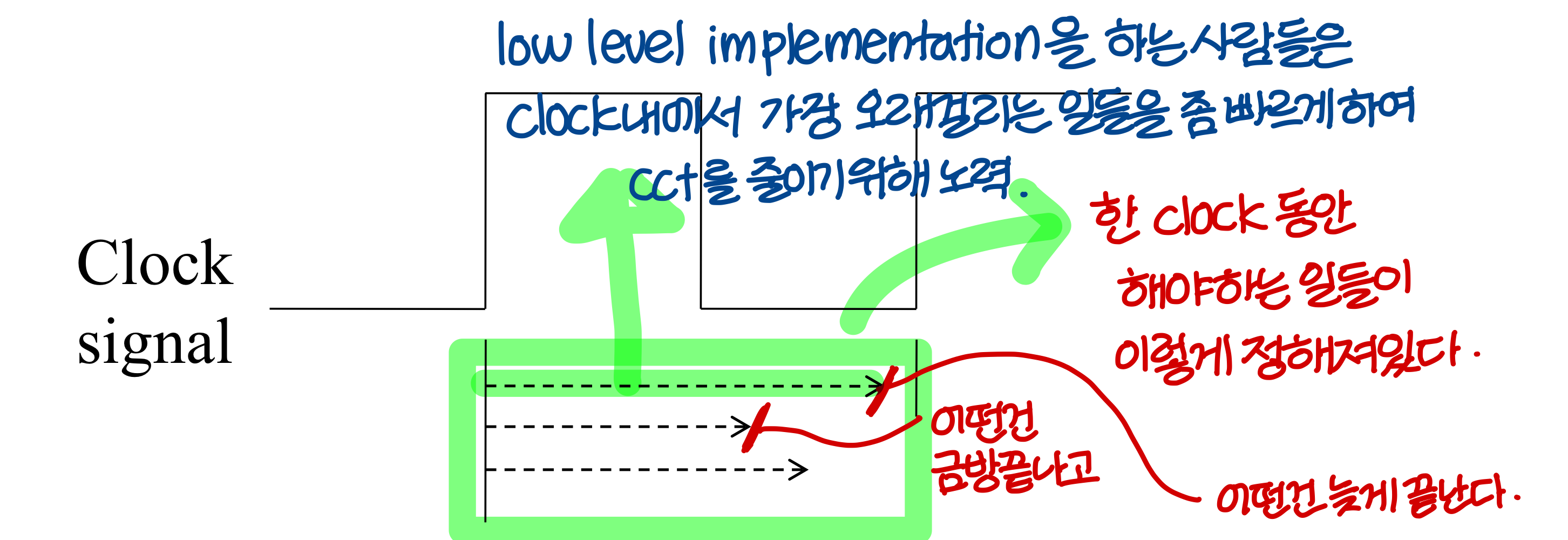
→ "ISA 및 high level implemenation 이 결정되면 한 클럭 내에 할 일들이 결정된다. "
low level implemenation 을 하는 사람들은(회로 설계하는 사람들) clock 내에 해야하는 일들을 보고
오래 걸리는 일을(critical(slowest) path)를 찾아 빠르게 하는 방법을 고민한다.
→ 이 부분은 컴퓨터 설계라기 보다 회로 설계 분야(그 중에서도 VLSI circuits design)
Pipelining: 3-Stage Pipeline
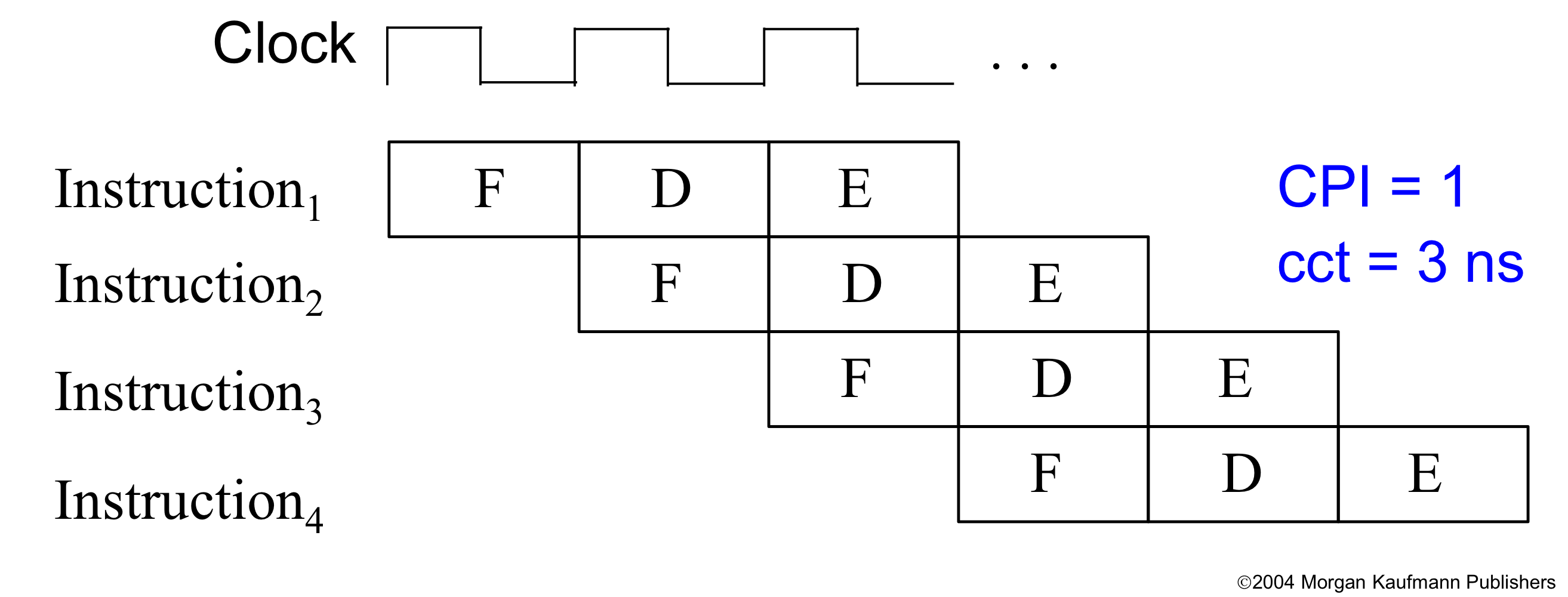
- 우리가 생각한 한 cycle에 fetch-decode-execute 로 한 instruction을 실행할 때
CPI = 1, cct = 9ns(cct는 가정임)
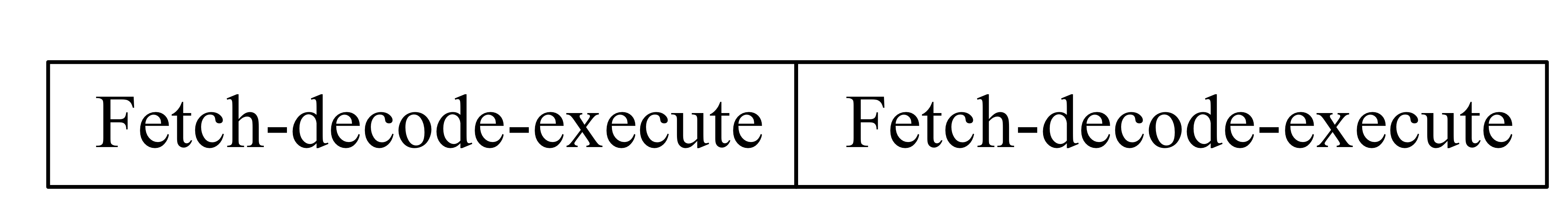
- 3 stage로 나누어서 한 cycle에 fetch 하나, decode 하나, execute 하나 실행한다면
CPI = 3, cct = 3ns(하는일이 1/3로 줄어들었으므로)

- 3 stage로 나누어서 파이프라이닝을 한다면
CPI = 1(매 cycle마다 instruction 1개씩 끝나니까), cct = 3ns
- 단계를 더 잘게 나눠서 9단계로 나눈다면
CPI = 1(매 cycle마다 instruction 1개씩 끝나니까), cct = 1ns(하는일이 처음에 비해 1/9로 줄었음)
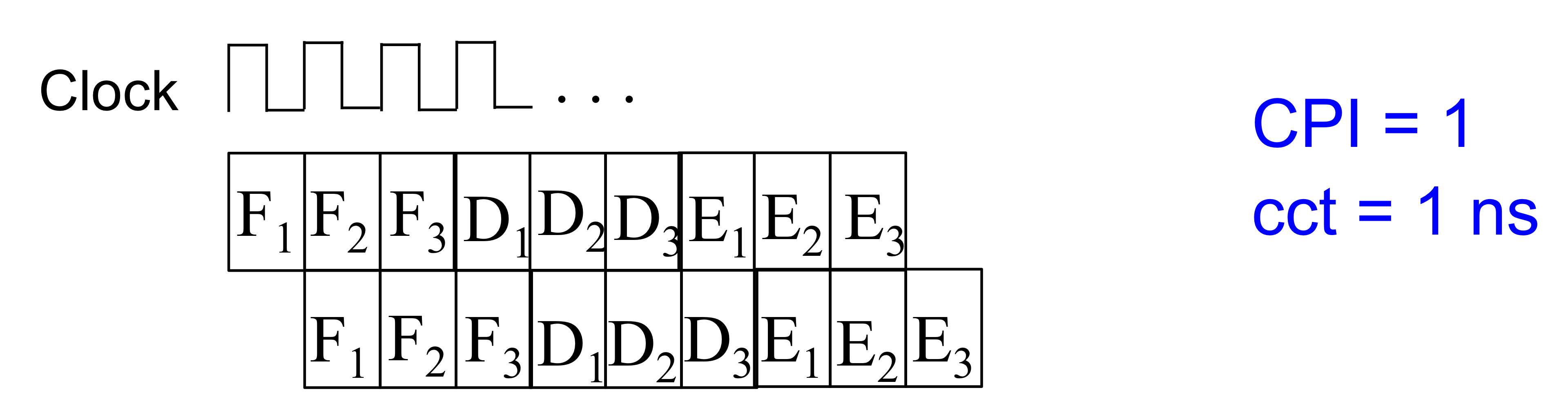
- 만약 프로세스마다 4개의 파이프라인을 만들게 된다면?
(이상적으로 4개가 병렬로 돌아간다면 CPI는 1/4로 줄어들게 된다. 1보다 작아지는거임) → 매 cycle마다 instruction 4개가 끝나니까
cct는 변화없이 여전히 1ns (clock 하나의 시간은 변화가 없지)
- 파이프라인을 하게 되면 instruction과 데이터를 더 빨리 소모하게 된다.
즉, instruction과 데이터들을 메모리에서 더 빨리 가져와야한다. 이 속도를 맞춰줄려면
high speed cache memory를 크게 해서 프로세스 안에 넣어줘야한다.
즉, 캐시 메모리는 파이프라인을 쓰게 되면 반드시 동반되는거
(트랜지스터가 작아짐에도 불구하고 CPU가 점점 커지는 이유도 이런 하드웨어가 계속 CPU에 추가되기 때문)
Quantitative Engineering Computer Performance 종합
책 제목 computer organization and design
→ 여기서 organization: high level implemenation의 의미에 가깝다.
→ 여기서 design: instruction set design에 가깝다. 즉, 인터페이스 설계에 가까움.
Example(compare execution time)

😀 CPU가 같고 compiler가 다르다고 할 때 → cct는 완전히 동일. 같은 instruction에 대해선 CPI도 동일.
그런데 CPI는 실제 실행되는 instruction에 대한 average CPI를 써야한다. compiler 가 다르면 실행해야하는 instruction mix가 달라져서
같은 instruction에 대한 CPI는 동일하더라도 (average) CPI는 달라진다.

Story of CPU Company
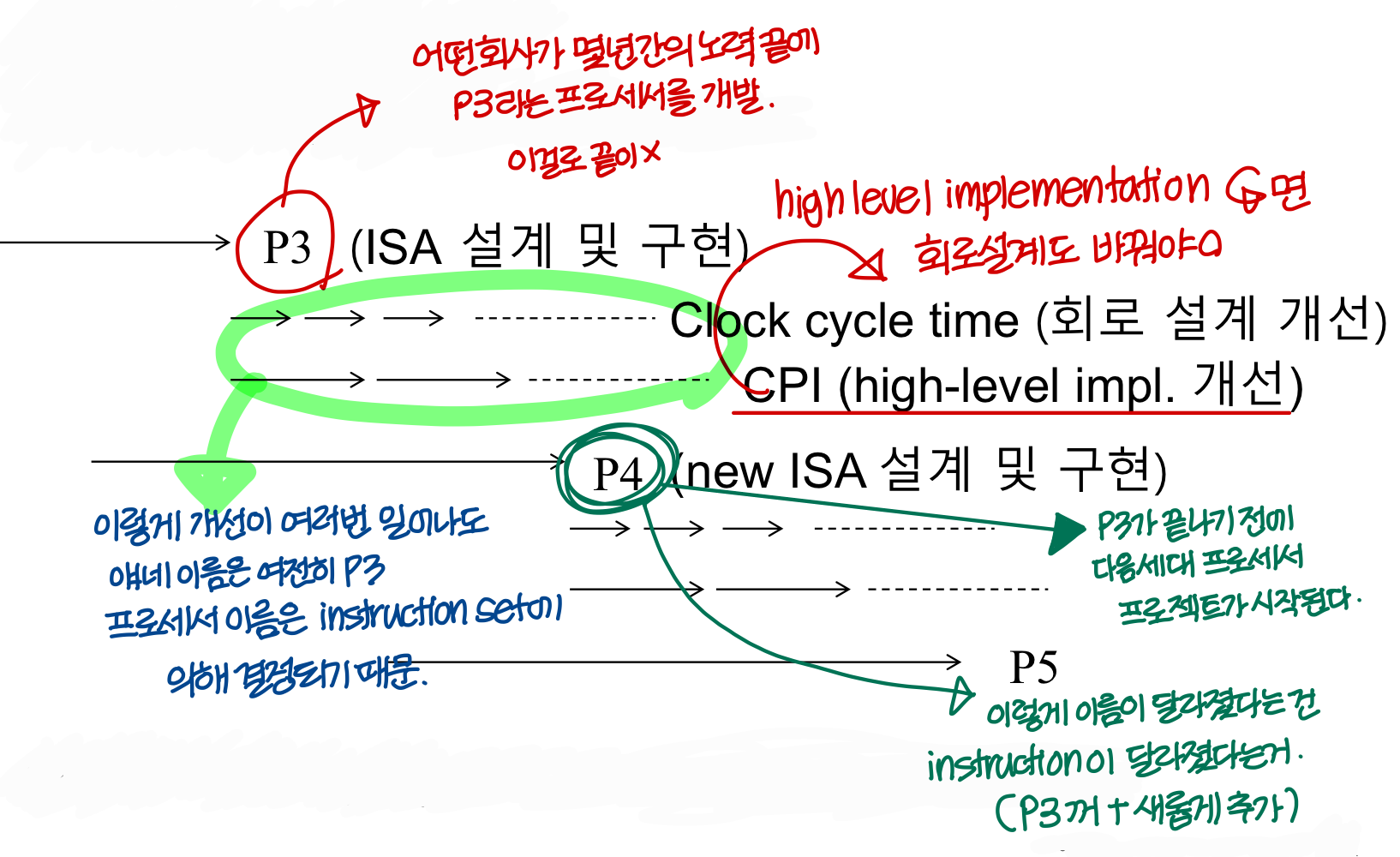
- P3, P4, P5
→ 이렇게 새로운 이름을 붙이는 이유는? : instruction set에 새로운게 추가되었기 때문
→ 왜 계속 새로운 ISA를 만드나? : 새로운 응용 프로그램들이 나오는데 과거의 ISA가 미래의 응용 프로그램을 효율적으로 돌리지 못할 수 있으므로.
새로운 응용 프로그램들을 효율적으로 돌리기 위해 프로세서가 진화하는거
Uploaded by N2T