
Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor에서 제안하는 방법론에 대한 컨셉을 이해하는 글이다.
1. Soft Actor-Critic(SAC)란?
SAC는 오프-폴리시(off-policy) 액터-크리틱(actor-critic) 기반 딥 강화학습 알고리즘이다. SAC의 기본 아이디어는 "standard maximum reward reinforcement leraning에 entropy term을 추가해서 단순히 reward를 최대화하는 것 뿐만이 아니라, 엔트로피를 최대화하면서 정책의 탐험을 장려"하는 것이다. 즉, task를 수행하면서 가능한 무작위로 행동하려고 하기 때문에, exploration과 robustness를 향상시킨다.
2. 사전지식
2.1 Actor-critic 구조에 대한 설명
SAC 알고리즘은 actor-critic 기반 알고리즘으로 1) Actor network와 2) Critic network로 구성된다.
Actor network는 현재 상태에서 행동을 선택하는 policy를 학습하고, Critic Network는 선택된 행동의 가치를 평가한다. 이 두 Network의 상호 작용을 통해 Actor는 최적의 행동을 학습하게 되고, Critic은 선택된 행동의 가치를 평가한다. 두 네트워크의 상호작용을 통해 Actor는 최적의 행동을 배우고, Critic은 가치 함수를 정확하게 추정하도록 학습된다.
2.2 Off-policy 방식에 대한 설명
off-policy 방식을 설명하기 위해서는, on-policy에 대한 설명이 동반되어야한다.
on-policy 기법은, agent가 현재 정책을 기준으로, 환경과 직접 상호작용을 해서 데이터를 수집하고, 그때그때 정책을 업데이트 해나가는 기법이다. 환경과 상호작용하여 얻은 데이터 (s, a, r, s')로 정책을 업데이트할수도 있고, 특정 횟수만큼 반복한 뒤에 업데이트를 진행할수도 있다. 중요한 점은 업데이트하고 난 뒤, 업데이트에 사용한 데이터는 버려진다는 점이다. 업데이트된 정책은 더이상 현재 정책이 아니기 때문이다. 즉, 수집한 데이터를 재활용하지 않고 한번씩만 사용하고 버려지기 때문에 sample inefficient하다. PPO와 TRPO가 on-policy에 속한다.
off-policy 기법은 데이터를 수집하는 정책(behavior policy)와 업데이트 대상이 되는 정책(target policy)이 다른 기법을 말한다. (on-policy는 두 policy가 동일하다.) 극단적인 예로, 모든 상태에서 임의의 행동을 취하는 policy를 사용해서 데이터를 수집하고, 그 데이터를 사용해서 최적의 target policy를 찾아나간다. off-policy 기법은 수집한 데이터를 여러번 사용해도 되기 때문에 상대적으로sample efficient하지만, 좋은 정책을 찾기까지 오랜 시간이 소요된다. DQN, DDPG 등이 off policy에 속한다.
2.3 엔트로피에 대한 설명
엔트로피는 확률 분포에 대해 정의되는 값으로 확률분포가 가지는 정보의 확신도 혹은 정보량을 수치로 표현한 것이다. 확률분포에서 특정한 값이 나올 확률이 높아지고 나머지 값의 확률이 낮아진다면 엔트로피는 작아진다. 반대로 여러가지 값이 나올 확률이 대부분 비슷한 경우에는 엔트로피가 낮아진다.
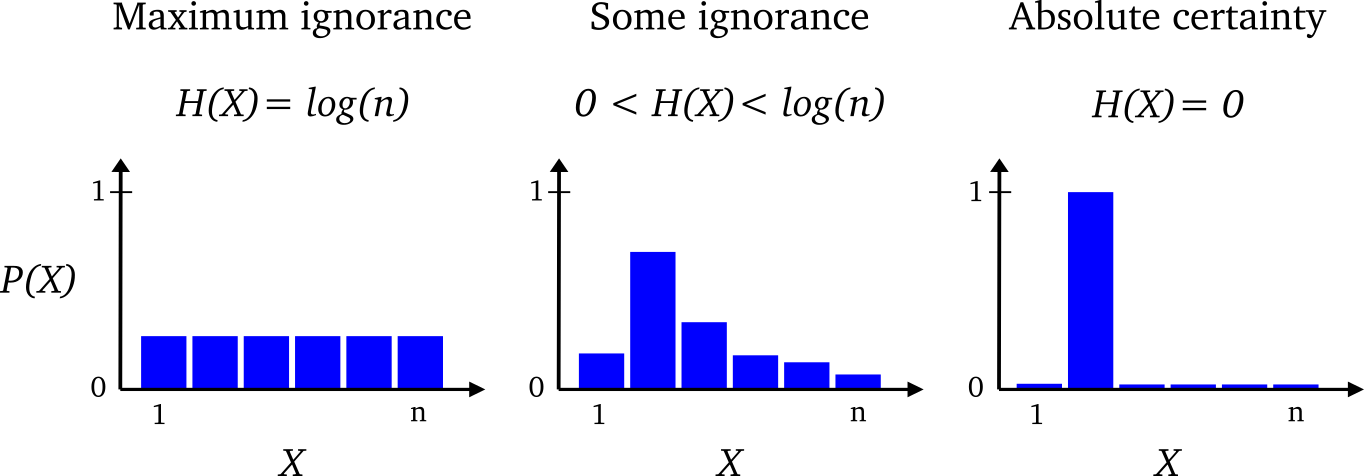
즉, 위와 같은 확률분포가 존재할 때 가장 오른쪽 그림을 살펴보자. 한 값에 확률이 1이고 나머지에 대해서는 확률이 0인 상황이다. 이런 경우에는 X가 2라고 확실하게 말할 수 있으며 엔트로피는 0이다. 반대로 가장 왼쪽의 그림을 살펴보면 모든 값이 확률이 균등하므로 X가 특정값이라고 확실하게 말할 수 없다. 이런 경우에는 엔트로피가 높아진다.
강화학습에는 Maximization Entropy 기법이 많이 등장한다. 즉, 행동을 결정하는 분포가 균등하게 되도록(행동의 선택이 랜덤하게 되도록) 학습시킨다는 의미인데 이런 항은 학습을 저하시키게 된다. 그럼에도 불구하고 이런 항을 사용하는 이유는 탐험을 유도하기 위해서이다. 임무를 성공적으로 수행하면서 가능한 한 무작위로 행동하도록 하여 다양한 탐험을 하게 만들어, 모델의 강건성을 증가시킬 수 있다.
3. Soft Actor-Critic(SAC) 알고리즘에 대한 설명
3.1 Soft policy iteration
policy iteration은 주어진 정책의 행동가치함수를 계산하는 policy evaluation과 계산된 행동가치함수를 바탕으로 정책을 개선하는 policy imporvement을 반복하며 optimal policy를 찾는 방법이다. Soft policy iteration은 SAC 알고리즘의 기반을 이루는 주요 이론적 프레임워크로, maximum entropy 강화학습의 목표에 맞게 policy iteration을 확장한 것이다.
3.1.1 Soft policy evaluation
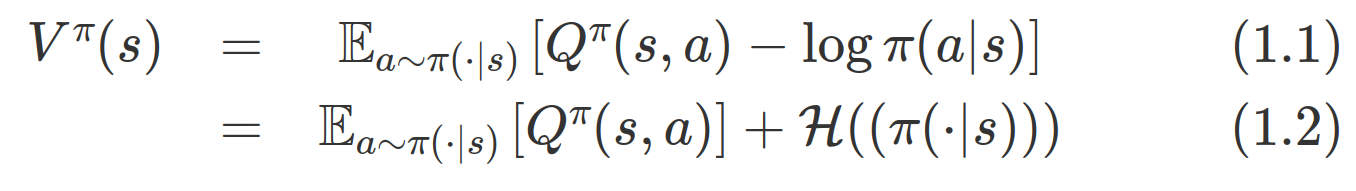
일반적인 policy evaluation과는 다르게 soft policy iteration에서는 우리가 알고 있는 상태가치함수의 식에서 엔트로피항이 추가된다. 즉, 엔트로피가 클수록 상태 s에서의 가치함수도 커진다는 것인데, 다양한 행동을 할수록 높은 가치를 준다는 것을 알 수 있다.
3.1.2 Soft policy improvement
우리가 알고 있는 policy iteration에서의 policy imporvement에서는 각 단계에서 행동가치함수가 가장 높은 행동을 하도록 정책을 수정한다. 즉,
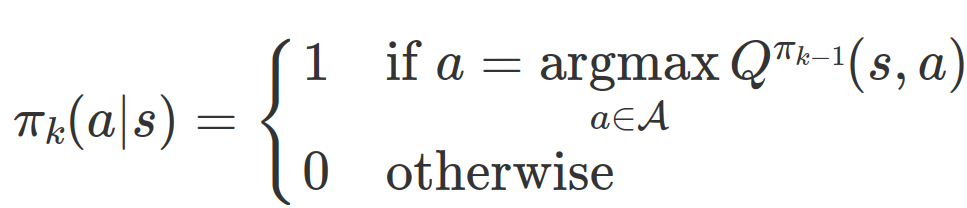
하지만 SAC에서는 행동가치함수가 높을수록 점점 더 높은 확률을 부여하도록 정책을 수정해간다.
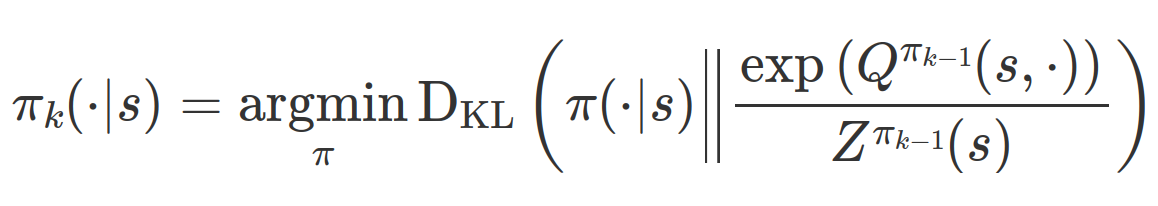
3.2 Soft Actor Critic
이제 본격적으로 SAC에 대해 살펴보자. 개념적으로, soft policy iteration 방식에 off policy 기반 actor critic을 적용한 것이라 생각하면 된다. SAC의 sudo code는 다음과 같다.

(Sudo code에 대한 설명 추가 예정)
요약하면...
SAC Key Features
- SAC(Soft Actor-Critic)는 엔트로피 최대화 프레임워크 기반의 Off-policy Actor-Critic 알고리즘
- SAC는 정책과 가치함수 근사를 기반으로 하는 Soft Policy Iteration알고리즘
- SAC의 특징은 기존 RL 알고리즘들과 동일하게 보상의 기댓값을 최대화하면서 동시에 정보량이 적은(엔트로피가 높은) 정책을 구성하여 샘플의 다양성을 확보한다는 것
'수업정리 > 딥러닝 이론' 카테고리의 다른 글
| Supervised Contrastive Learning 코드 분석 (0) | 2024.05.28 |
|---|---|
| Triplet Loss 이해하기(개념, 수식, 주의사항) (0) | 2024.05.19 |
| Batch normalization vs Input normalization 이해하기 (1) | 2023.11.23 |
| Residual Network, Residual Block 개념정리 (0) | 2023.10.16 |
| Diffusion Model 설명 (0) | 2023.10.15 |