
학습 결과에 계속 문제가 생겨 이를 해결하기 위해 autoregressive learning을 시도해보기로 하였다. 개념도 가물가물하고 구현해보는 것도 처음이라 공부할겸 이렇게 정리해보았다.
Autoregressive learning(자기회귀 학습)이란?
시계열 데이터나 순차적인 데이터에 대한 모델링 기법 중 하나로, 현재의 상태나 값이 이전 상태나 값에 의존하는 경우에 주로 사용된다. autoregressive model은 현재 시점의 값을 이전 시점의 값을 사용하여 예측하거나 생성하게 된다. 즉 현재 값은 이전 값들의 함수로써 모델링 된다는 것이 특징이다.
이러한 방식으로 모델을 구성하면, 데이터의 순차적인 특징을 잘 반영하고, 시간에 대한 변화나 패턴을 잘 파악할 수 있다.
Character Controller Using Motion VAEs
motion 분야에서 Autoregressive learning을 잘 활용한 "Character Controller Using Motion VAEs" 논문을 살펴보며 세부사항들을 살펴보았다. batch를 어떻게 구성하는지 등 구현과 관련된 부분을 집중적으로 살펴보았다.
두가지 step에 걸쳐 framework를 완성한다.
1) 첫번째 step: MVAE
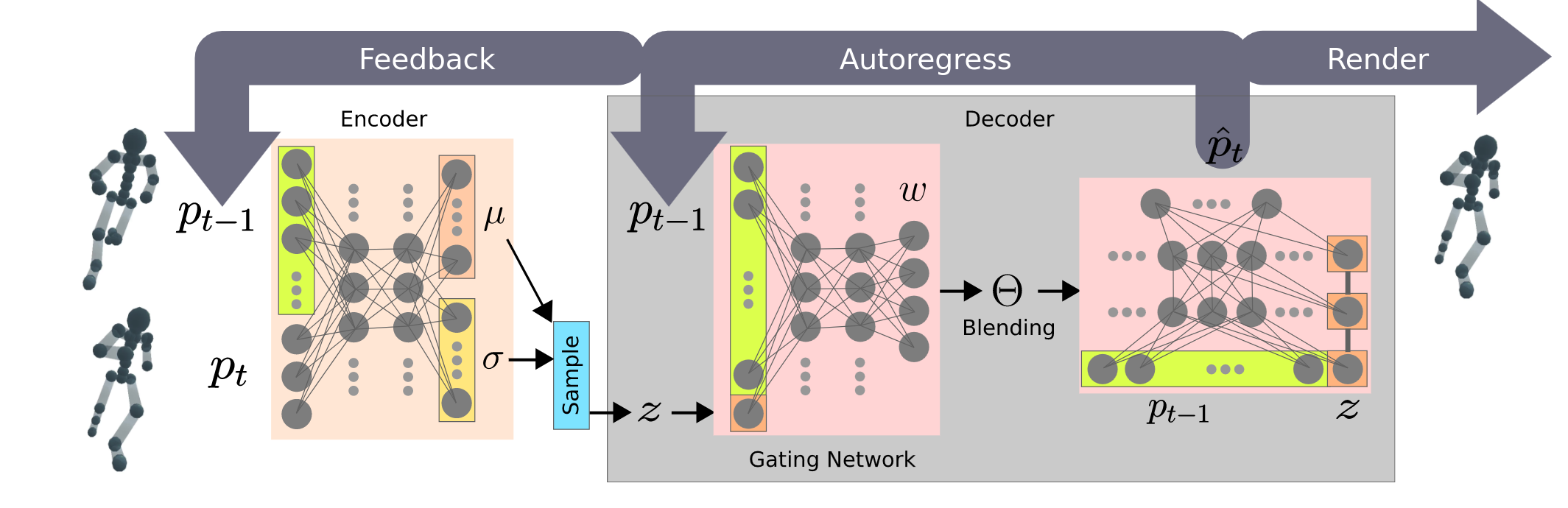
위의 frame work를 autoregressive conditional variational autoencoder, 줄여서 Motion VAE(MVAE)라고 부른다.
먼저 latent variable과 현재 pose를 받아 next pose를 잘 reconstruct 할 수 있는 Decoder를 생성해내는게 첫번째 step의 목표이다. 이를 위해 Encoder-Decoder 구조를 end-to-end로 학습시키며, Encoder는 p_{t-1}과 p_t를 받아 motion transition을 잘 반영하는 latent variable distribution을 생성해내고, 여기서 latent variable을 sampling한다. 이 Sampling된 latent varaible과 p_{t-1}가 Decoder로 들어가 p_t를 잘 reconstruct하도록 학습을 시킨다.
Decoder는 동일한 구조의 expert network 6개와 gating network 1개로 구성된다. gating network의 입력은 latent variable z와 이전 pose p_{t-1}이다. Expert network의 가장 중요한 특징은 z가 각 레이어마다 입력으로 사용되어 사후 붕괴를 방지한다는 점이며 gating network는 첫번째 layer에서만 z를 입력으로 받는다.
training 중에 MVAE는 current pose를 받아 next pose를 reconstruct하게 된다. 이때 reconstruction loss는 "predicted pose와 motion clip 상의 next pose 사이의 MSE(mean squared error)"로 정의된다.
<Training 상세 부분>
- training 과정은 표준 𝛽-VAE와 유사하다. training objective는 reconstruction과 KL-dirvergence loss를 최소화하는 것으로, posterior collapse를 최소화하기 위해 𝛽 = 0.2로 선택하였다.
- (참고로 𝛽-VAE를 학습시킬 때 사용하는 loss는 다음과 같이 표현된다. , 여기서 𝛽는 두 손실 간의 상대적인 중요도를 제어하는 파라미터이다. Reconstruction loss는 입력 데이터를 잘 재구성하는 것이 목표이고, KL-dirvergence loss는 latent variable의 분포를 원하는 형태로 가깝게 만드는 역할을 한다.)
- training data에 z-score normalization을 적용하였을 때 generalization이 더 잘되었다.
- Adam optimizer를 사용하였다.
- learning rate는 10^-4에서 시작해서 180 epoch동안 linear하게 0으로 감소된다.
- Mini-batch size는 64로 설정하였다.
***중요****이거 보려고 논문 읽었다!! <scheduled sampling>
MVAE 모델을 standard supervised learning으로 학습을 시키면 autoregressive한 prediction을 할 때 불안정한 문제가 발생하게 된다. sequence of predictions이 쌓임에 따라 작은 error들이 누적되게 되고 이는 결국 expected behavior과 큰 차이를 만들어내게 된다. 이러한 문제를 해결하기 위해 "scheduled sampling"이라는 기법을 사용하게 된다.
간단히 설명하면, training 과정에서 Model의 예측 불확실성을 서서히 도입하는 것을 목표로 한다. 작동 방식은 다음과 같다.
- 각 훈련 Epoch마다 샘플 확률 p를 정의한다. 훈련 중에 실제 data를 얼마나 사용할지를 나타내는 비율이다. (즉, p = 1이면 supervised learning으로, prediction은 실제 data에 의존하게 되고, p = 0이면 autoregressive prediction으로 prediction은 model이 만들어내는 값에 완전히 의존한다.)
- Training 중에 pose prediction이 이루어지면, 그 다음 pose를 예측할 때 model의 예측 결과를 (1-p)의 확률로 사용한다. 이러한 방법을 사용하면, 훈련과정에 불확실성과 다양성을 도입할 수 있다.
- 전체 훈련 과정은 3가지의 단계로 나뉜다.
- 지도학습단계 (p = 1): 처음 훈련 단계로, 모든 예측은 실제 데이터에 의존한다.
- 스케줄된 샘플링 단계 (확률 감소 p): 훈련 중에 모델의 예측에 점진적으로 의존하도록 전환하여, 실행 시간과 유사한 상황을 모방한다.
- 자기회귀 예측 (p = 0): 훈련 중에 모델의 예측에 완전히 의존하여 실제 자기회귀 생성을 대표한다.
- 각 단계의 epoch 수는 20(teacher_epochs), 20(ramping_epochs), 140(student_epochs)으로 정의된다.
- 스케줄된 샘플링 단계에서 샘플확률 p는 학습반복마다 선형적으로 0으로 줄어든다. 이는, 실제 데이터에서 점점 모델의 예측에 의존하는 것으로 점진적으로 변화함을 의미한다.
=> 이러한 기법을 사용하여 MVAE 모델을 학습하면, 불안정한 예측에서 회복하여 더 안정적이고 일관된 예측을 만들 수 있다.
=> 스케줄된 샘플링 단계의 세부사항이 부족한듯 싶어 코드를 살펴보았다.
코드 분석 진행중...왤케 어려워 하지만 할수있다................................
https://github.com/electronicarts/character-motion-vaes/blob/main/vae_motion/train_mvae.py
teacher_epochs = 20 # p = 1일때의 단계
ramping_epochs = 20 # p가 점진적으로 감소하는 단계
student_epochs = 100 # p = 0일때의 단계
args.num_epochs = teacher_epochs + ramping_epochs + student_epochs
args.mini_batch_size = 64 # 하나의 mini batch에 data 64개
args.initial_lr = 1e-4 # learnign rate를 1e-4 에서 1e-7로 점진적으로 감소시킴
args.final_lr = 1e-7
raw_data = np.load(args.mocap_file)
mocap_data = torch.from_numpy(raw_data["data"]).float().to(args.device)
end_indices = raw_data["end_indices"]
batch_size = mocap_data.size()[0]
frame_size = mocap_data.size()[1]
# bad indices are ones that has no required next frames
# need to take account of num_steps_per_rollout and num_future_predictions
bad_indices = np.sort(
np.concatenate(
[
end_indices - i
for i in range(
args.num_steps_per_rollout
+ (args.num_condition_frames - 1)
+ (args.num_future_predictions - 1)
)
]
)
)
all_indices = np.arange(batch_size)
good_masks = np.isin(all_indices, bad_indices, assume_unique=True, invert=True)
selectable_indices = all_indices[good_masks]
pose_vae = PoseMixtureVAE(
frame_size,
args.latent_size,
args.num_condition_frames,
args.num_future_predictions,
normalization,
args.num_experts,
).to(args.device)
for ep in range(1, args.num_epochs + 1):
sampler = BatchSampler(
SubsetRandomSampler(selectable_indices),
args.mini_batch_size,
drop_last=True,
)
ep_recon_loss = 0
ep_kl_loss = 0
ep_perplexity = 0
update_linear_schedule(
vae_optimizer, ep - 1, args.num_epochs, args.initial_lr, args.final_lr
)
num_mini_batch = 1
for num_mini_batch, indices in enumerate(sampler):
t_indices = torch.LongTensor(indices)
# condition is from newest...oldest, i.e. (t-1, t-2, ... t-n)
condition_range = (
t_indices.repeat((args.num_condition_frames, 1)).t()
+ torch.arange(args.num_condition_frames - 1, -1, -1).long()
)
t_indices += args.num_condition_frames
history[:, : args.num_condition_frames].copy_(mocap_data[condition_range])
for offset in range(args.num_steps_per_rollout):
# dims: (num_parallel, num_window, feature_size)
use_student = torch.rand(1) < sample_schedule[ep - 1]
prediction_range = (
t_indices.repeat((args.num_future_predictions, 1)).t()
+ torch.arange(offset, offset + args.num_future_predictions).long()
)
ground_truth = mocap_data[prediction_range]
condition = history[:, : args.num_condition_frames]
if isinstance(pose_vae, PoseVQVAE):
(vae_output, perplexity), (recon_loss, kl_loss) = feed_vae(
pose_vae, ground_truth, condition, future_weights
)
ep_perplexity += float(perplexity) / args.num_steps_per_rollout
else:
# PoseVAE, PoseMixtureVAE, PoseMixtureSpecialistVAE
(vae_output, _, _), (recon_loss, kl_loss) = feed_vae(
pose_vae, ground_truth, condition, future_weights
)
history = history.roll(1, dims=1)
next_frame = vae_output[:, 0] if use_student else ground_truth[:, 0]
history[:, 0].copy_(next_frame.detach())
vae_optimizer.zero_grad()
(recon_loss + args.kl_beta * kl_loss).backward()
vae_optimizer.step()
ep_recon_loss += float(recon_loss) / args.num_steps_per_rollout
ep_kl_loss += float(kl_loss) / args.num_steps_per_rollout
avg_ep_recon_loss = ep_recon_loss / num_mini_batch
avg_ep_kl_loss = ep_kl_loss / num_mini_batch
avg_ep_perplexity = ep_perplexity / num_mini_batch
logger.log_stats(
{
"epoch": ep,
"ep_recon_loss": avg_ep_recon_loss,
"ep_kl_loss": avg_ep_kl_loss,
"ep_perplexity": avg_ep_perplexity,
}
)
torch.save(copy.deepcopy(pose_vae).cpu(), pose_vae_path)
2) 두번째 step: latent variable z를 생성하는 policy 생성

첫번째 step에서 학습시킨 network에서 Encoder 부분은 discard된다. 그리고 Decoder 부분은 fixed 시킨 다음 원하는 pose를 생성해내기 위한 z 값을 만들어내는 policy를 DRL을 통해 학습하게 된다.
'수업정리 > 딥러닝 이론' 카테고리의 다른 글
| Residual Network, Residual Block 개념정리 (0) | 2023.10.16 |
|---|---|
| Diffusion Model 설명 (0) | 2023.10.15 |
| 딥러닝 수업정리) 15_Word embedding (2) | 2023.06.13 |
| 딥러닝 수업정리) 16_Transformer (2) | 2023.06.13 |
| 딥러닝 기말대비 요약본 (2) (2) | 2023.06.13 |