
VAE에 대해선 다들 알고 있을 것이다. 내가 작성했던 아래의 포스트에서도 VAE에 대한 설명을 제공하고 있다.
https://chickencat-jjanga.tistory.com/3
VAE 설명
들어가기에 앞서 * AE와 VAE는 이름이 유사하지만, 수학적으로는 아무런 관련이 없음 * VAE는 Generative model임! * Generative model? training data가 주어졌을 때 이 data가 sampling 된 분포와 같은 분포에서 새로
chickencat-jjanga.tistory.com
VAE를 간단하게 복습해보자면, VAE(Variational Autoencoder)는 데이터를 잠재 공간(latent space)으로 압축한 후 다시 복원하는 방법론을 제공한다. VAE는 잠재 공간을 연속적인 분포로 모델링하며, 잠재 벡터를 정규 분포에서 샘플링하게 된다.
VQ-VAE는 VAE와 달리 연속적인 분포 대신 이산적인(quantized) 잠재 공간을 사용한다. 즉, VQ-VAE에서는 잠재 공간이 미리 정의된 이산적인 codebook 안의 코드 벡터들로 구성되어 있다.
VQ-VAE의 구성요소는 다음과 같다.
- 인코더(Encoder): 입력 데이터를 잠재 공간 벡터로 변환한다.
- 코드북(Codebook): 인코더에서 얻은 잠재 벡터를 미리 정의된 이산적인 코드 벡터들로 양자화한다.
- 디코더(Decoder): 코드북에서 양자화된 벡터를 다시 원래 입력 데이터로 복원한다.
이 과정에서 중요한 차이점은 VAE는 잠재 벡터를 확률적 분포에서 샘플링하는 반면, VQ-VAE는 가장 가까운 코드북 벡터를 선택하여 양자화(quantization)한다는 점이다. 즉 Vector Quantization을 한다는 점인데, 이해 대해 조금 더 자세히 살펴보자.
Vector Quantization(벡터 양자화)
Vector Quantization(벡터 양자화)는 연속적인 값들을 미리 정해진 이산적인 값들로 대체하는 과정이다. 이를 이해하기 위해, VQ-VAE에서 어떤 일이 벌어지는지 단계별로 살펴보자.
1) VQ-VAE의 인코딩 과정
VQ-VAE는 먼저 인코더를 통해 입력 데이터를 잠재 벡터(latent vector)로 변환한다. 이 잠재 벡터는 일반적인 오토인코더나 VAE에서처럼 연속적인 값들을 가진다. 하지만, VQ-VAE는 이 잠재 벡터를 그대로 사용하지 않고, 미리 정의된 "이산적인 코드북(codebook)"에 있는 값들 중에서 가장 가까운 값을 찾아 대체합니다. 이 과정이 바로 벡터 양자화이다.
2) 벡터 양자화 과정
벡터 양자화 과정은 크게 두 가지로 나눌 수 있다.
- 코드북(Codebook) 정의:
- VQ-VAE는 미리 정해진 코드북, 즉 여러 개의 코드 벡터 집합을 가지고 있다. 이 코드북은 VQ-VAE가 학습하면서 계속해서 업데이트된다.
- 코드북은 잠재 벡터를 양자화할 때 사용할 수 있는 이산적인 후보 벡터들의 집합입니다. 즉, 각 벡터는 잠재 공간에서 특정 위치를 대표하는 "좌표" 같은 역할을 합니다.
- 양자화(Quantization):
- 인코더를 통과한 잠재 벡터와 코드북에 있는 모든 벡터들 간의 거리를 계산한 뒤 코드북의 벡터들 중 거리가 가장 가까운 벡터로 대체된다.
- 이 과정을 통해, 연속적인 값을 가진 잠재 벡터가 이산적인 벡터로 변환된다.
이 과정을 통해 잠재 벡터는 더 이상 연속적인 값이 아닌 이산적인 코드북 벡터로 표현된다.
그럼, 이러한 discrete한 잠재 공간이 왜 필요할까?
VAE에서는 잠재 공간이 연속적인 값들을 가지기 때문에, 생성되는 데이터가 연속적인 분포를 따라야 한다. 하지만 자연 이미지, 음성, 비디오와 같은 데이터는 명확한 이산적인 패턴을 가진다. 예를 들어, 이미지의 특정 패치나 객체는 명확히 구분되는 특징들을 가진다.
벡터 양자화는 이런 이산적이고 구분되는 패턴을 학습하는 데 적합합니다. 코드북의 벡터들이 데이터의 특정 패턴을 학습하면, 이후 새로운 데이터를 생성할 때 코드북에서 적절한 패턴을 골라 사용함으로써 더 자연스러운 데이터 생성을 할 수 있게 됩니다.
그럼 구체적으로 벡터 양자화가 학습에 어떠한 도움을 줄 수 있을까?
- 데이터 압축:
- 벡터 양자화는 연속적인 잠재 공간 대신 이산적인 공간을 사용하기 때문에, 잠재 벡터의 표현을 더 효율적으로 압축할 수 있다. 이는 특히 고차원 데이터(예: 이미지, 음성 등)의 경우 유리하다.
- 노이즈 감소:
- 연속적인 분포를 샘플링하는 대신, 이산적인 코드 벡터를 선택함으로써 생성되는 데이터의 잡음을 줄일 수 있다.
- 패턴 학습:
- 코드북을 통해 데이터의 특정 패턴을 명확히 학습하고 그 패턴을 재사용함으로써 생성 모델의 성능을 높일 수 있다.
VQ-VAE의 학습

VQ-VAE의 학습에 사용하는 loss term은 총 3가지이다. 첫 번째 항은 reconstruction loss, 두 번째 항은 vector quantization loss, 세 번째 항은 codebook commitment loss이다. 아래의 수식에서 sg는 해당 term에는 weight가 업데이트 되지 않는 "stop gradient"를 의미한다. 즉 역전파를 막는 연산자로, 벡터의 값은 사용하지만 그에 대한 기울기는 계산하지 않겠다는 의미입니다.

1. reconstruction loss

- 디코더가 입력 데이터를 얼마나 잘 복원하는지 측정하는 손실이다.
- VAE를 비롯하여 오토인코더 구조에서 사용하는 기본적인 손실이며 보통 L2 손실 또는 L1 손실로 정의된다.
- 디코더와 인코더 최적화에 모두 사용되는 loss 식이다.
2. vector quantization loss

- VQ-VAE의 핵심 loss이다. 코드북은 이산화되어있어서 gradient로 업데이트가 안되기 때문에 reconstruction loss로 코드북은 업데이트 되지 않는다. 따라서 코드북 자체를 학습시키기 위해 별도의 vector quantization loss가 필요하다.
- 인코더에서 얻은 잠재 벡터(z_e(x))가 코드북에 있는 가장 가까운 코드 벡터(e_k)와 얼마나 가까운지를 측정하는 손실이다.
- 이 손실 항목의 목적은 인코더가 잠재 벡터를 코드북 벡터와 더 가깝게 만들도록 유도하며 코드북을 업데이트한다. 이 과정이 원활하게 이뤄지지 않으면, 인코더의 출력이 코드북 벡터와 너무 큰 차이가 나서 재구성 품질이 떨어지게 된다.
- 해당 loss에서 z_e(x)에 sg로 stop gradient로 표시되어있는 것에서 알 수 있듯이 인코더는 이 손실로 인해 직접적으로 업데이트되지 않는다.
3. codebook commitment loss
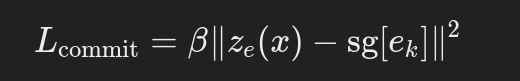
- 이 손실은 인코더가 코드북의 벡터와 가까운 값을 생성하도록 강제하는 역할을 한다.
- 만약 codebook commitment loss가 없다면 인코더가 굳이 코드북의 값에 가까운 출력을 만들 필요가 없고, Embedding vector는 무한하기 때문에, codebook loss에서 는 encoder vector만큼 빠르게 학습되기 어려우므로 학습이 원활하지 않을 수 있다.
- 따라서 Encoder vector가 embedding vector에 commit하여 encoder vector가 embedding vector와 유사해질 수 있도록하는 commitment loss를 추가하여 인코더가 잠재 벡터를 효율적으로 코드북에 매핑할 수 있도록 도와준다.
'수업정리 > 딥러닝 이론' 카테고리의 다른 글
| 딥러닝 면접 기초 개념 (0) | 2025.03.19 |
|---|---|
| SVM(State-Vector Machine)이란? (0) | 2024.09.30 |
| Supervised Contrastive Learning 코드 분석 (0) | 2024.05.28 |
| Triplet Loss 이해하기(개념, 수식, 주의사항) (0) | 2024.05.19 |
| Soft Actor-Critic(SAC) 컨셉 이해 (0) | 2024.05.16 |