
wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations 논문에 대한 간단한 요약이다.
https://arxiv.org/abs/2006.11477
wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations
We show for the first time that learning powerful representations from speech audio alone followed by fine-tuning on transcribed speech can outperform the best semi-supervised methods while being conceptually simpler. wav2vec 2.0 masks the speech input in
arxiv.org
본 논문은 speech representations의 self-supervised learning model에 대해 다루고 있다. 즉, raw audio data를 받아 유용한 audio representation을 학습하고자한다.
(self-supervsied learning은 라벨이 없는 데이터를 이용하여 자기 자신의 특성(representation)을 배우는 학습 방법으로, self-supervised learning을 적용한 pre-trained 모델이 있다면 fine tuning을 이용해 데이터가 적은 분야에서도 성능향상을 가져올 수 있다.)
<모델의 구성>
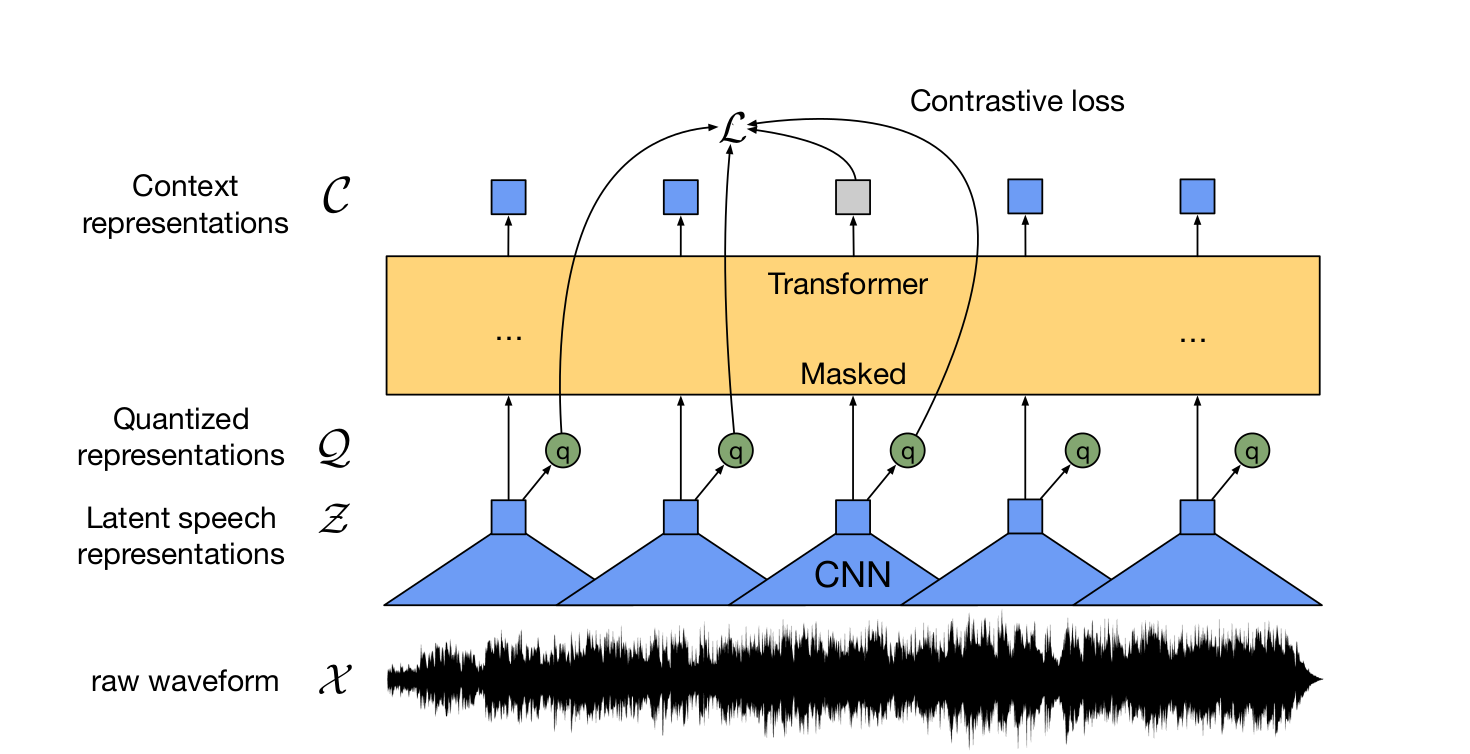
1. feature encoder <f: X -> Z>
- Raw waveform을 Multi layered CNN 인코더를 거치도록 하여 25ms 길이의 represent vector로 변환한다.
- 매 T 시점마다 latent speech representations z_1, ...z_T를 출력한다.
- latent speech representation이 모델이 학습하고자 하는 Target이다!!!!!
- 변환된 represent vector = latent speech representations은 두 모듈 (quantizer, transformer에 공급된다.)
2. Quantization Module <Z -> Q>

- CNN 인코더를 통과한 output feature는 quantizer(양자화 모듈) Z->Q를 통과하여 q_t로 이산화된다. qt로 변환하기 위해 Quantizer는 learned unit 인벤토리(codebook)에서 code words를 선택한다.
- code word는 일종의 음소에 대한 representation이라고 생각하면 된다. 아무리 언어가 달라도 인간이 발음할 수 있는 음소에는 공통적인 부분이 있고 유한하다. 이를 Embedding vector로 표현했다고 보면 된다.
- 즉, 하나의 codebook에서 V개의 음소(codeword) 중 현 시점에서 벡터 z_t와 가장 적절하게 대응될 음소 벡터 codeword를 이산화과정을 통해 고른 것이 q_t이다.
3. Transformer Module <g: Z -> C>
- Transformer는 z로부터 context 정보를 사용해 전체 시퀀스로부터 context representation c_1, ... c_T를 생성한다.
- Transformer의 출력은 contrastive task를 푸는데 사용된다. 즉, quantinized repressentations과 해당 위치의 context representations이 유사하도록 학습을 시키는 것!!(contrastive loss)
- contrastive loss를 최소화하면 음성 데이터 안에 공통적으로 가지고 있는 mutual information을 최대화할 수 있다.
이렇게 학습된 Z를 이용하여 간단한 Fine tuning 학습을 거치게 되면 적은 labeld data에 대해서도 좋은 성능을 보일 수 있다!
'연구 > 오디오' 카테고리의 다른 글
| Learning Music Reprsentation with WAV2VEC 2.0 논문리뷰 (2) | 2023.12.05 |
|---|---|
| 실시간으로 mel spectrogram 생성하기 (0) | 2023.10.10 |
| mel spectrogram 관련 조사 + 어떻게 뽑아내는지 (0) | 2023.07.05 |